Python实现两种多分类混淆矩阵
目录
- 1、什么是混淆矩阵
- 2、分类模型评价指标
- 3、两种多分类混淆矩阵
- 3.1直接打印出每一个类别的分类准确率。
- 3.2打印具体的分类结果的数值
- 4、总结
1、什么是混淆矩阵
深度学习中,混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法。它可以直观地了解分类模型在每一类样本里面表现,常作为模型评估的一部分。它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class)。
首先要明确几个概念:
T或者F:该样本 是否被正确分类。
P或者N:该样本 原本是正样本还是负样本。
真正例(True Positive,TP):预测正确;模型预测也是正例,样本的真实类别是正例,
真负例(True Negative,TN):预测正确:模型预测为负例,样本的真实类别是负例,
伪正例(False Positive,FP):预测错误:模型预测为正例,样本的真实类别是负例,
伪负例(False Negative,FN):预测错误;模型预测为负例,样本的真实类别是正例,
将这四个指标一起呈现在表格中,就能得到如下这样一个矩阵,我们称它为混淆矩阵(Confusion Matrix),这里从其他博客偷了张图:

在混线矩阵中,以对角线为分界线。以上图为例子:对角线的位置表示预测正确,对角线以外的位置表示把样本错误的预测为其他样本。
2、分类模型评价指标
从混淆矩阵可以直观地看出各个参数的数值大小。查准率是在模型预测为正的所有样本中,模型预测对的比重,即:“分类器认为是正类并且确实是正类的部分占所有分类器认为是正类的比例”。计算公式如下式所示:

F1-Score指标综合了Precision与Recall的产出的结果。F1-Score的取值范围从0到1的,1代表模型的输出最好,0代表模型的输出结果最差,计算公式如下式所示:
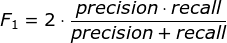
除了F1分数之外,F2分数和F0.5分数在统计学中也得到大量的应用。其中,F2分数中,召回率的权重高于精准率,而F0.5分数中,精准率的权重高于召回率。
3、两种多分类混淆矩阵
多分类混淆矩阵根据不同需求可以绘制不同的矩阵:
1、直接打印出每一个类别的分类准确率。
2、打印具体的分类结果的数值,方便数据的分析和各类指标的计算
在介绍具体代码之前,首先来介绍confusion_matrix()函数,它是Python中的sklearn库提供的输出矩阵数据的方法:
def confusion_matrix(y_true, y_pred, labels=None, sample_weight=None):
参数意义:
- y_true: 是样本真实分类结果,y_pred: 是样本预测分类结果
- y_pred:预测结果
- labels:是所给出的类别,通过这个可对类别进行选择
- sample_weight : 样本权重
3.1直接打印出每一个类别的分类准确率。
# 显示混淆矩阵
def plot_confuse(model, x_val, y_val):
# 获得预测结果
predictions = predict(model,x_val)
#获得真实标签
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
cm = confusion_matrix(y_true=truelabel, y_pred=predictions)
plt.figure()
# 指定分类类别
classes = range(np.max(truelabel)+1)
title='Confusion matrix'
#混淆矩阵颜色风格
cmap=plt.cm.jet
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
thresh = cm.max() / 2.
# 按照行和列填写百分比数据
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, '{:.2f}'.format(cm[i, j]), horizontalalignment="center",
color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
plt.show()
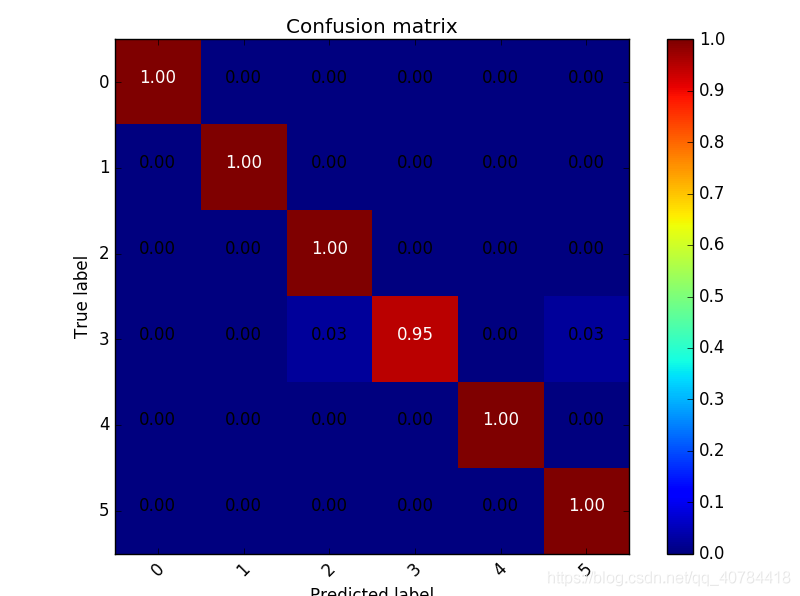
3.2打印具体的分类结果的数值
# 显示混淆矩阵
def plot_confuse_data(model, x_val, y_val):
classes = range(0,6)
predictions = predict(model,x_val)
truelabel = y_val.argmax(axis=-1) # 将one-hot转化为label
confusion = confusion_matrix(y_true=truelabel, y_pred=predictions)
#颜色风格为绿。。。。
plt.imshow(confusion, cmap=plt.cm.Greens)
# ticks 坐标轴的坐标点
# label 坐标轴标签说明
indices = range(len(confusion))
# 第一个是迭代对象,表示坐标的显示顺序,第二个参数是坐标轴显示列表
plt.xticks(indices, classes)
plt.yticks(indices, classes)
plt.colorbar()
plt.xlabel('Predicted label')
plt.ylabel('True label')
plt.title('Confusion matrix')
# plt.rcParams两行是用于解决标签不能显示汉字的问题
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# 显示数据
for first_index in range(len(confusion)): #第几行
for second_index in range(len(confusion[first_index])): #第几列
plt.text(first_index, second_index, confusion[first_index][second_index])
# 显示
plt.show()
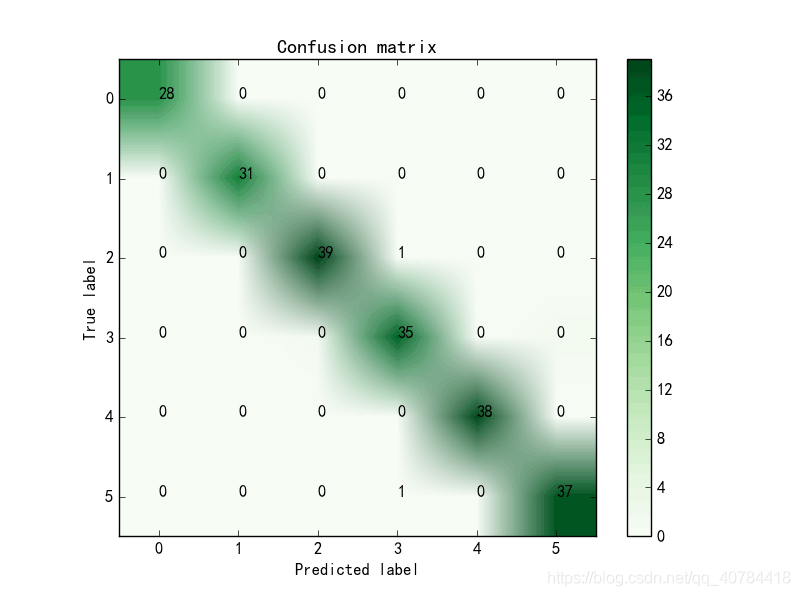
4、总结
1、混淆矩阵是深度学习中分类模型最常用的评估指标。网上大部分都是显示各类的分类正确率,不够灵活。显示具体数值灵活性大,可以计算自己想要的指标。
2、多分类的混淆矩阵中 查准率为主对角线上的值除以该值所在列的和;召回率等于主对角线上的值除以该值所在行的和。
以上就是Python实现两种多分类混淆矩阵的详细内容,更多关于Python多分类混淆矩阵的资料请关注我们其它相关文章!
相关推荐
-
利用python中的matplotlib打印混淆矩阵实例
前面说过混淆矩阵是我们在处理分类问题时,很重要的指标,那么如何更好的把混淆矩阵给打印出来呢,直接做表或者是前端可视化,小编曾经就尝试过用前端(D5)做出来,然后截图,显得不那么好看.. 代码: import itertools import matplotlib.pyplot as plt import numpy as np def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cma
-

使用Python和scikit-learn创建混淆矩阵的示例详解
目录 一.混淆矩阵概述 1.示例1 2.示例2 二.使用Scikit-learn 创建混淆矩阵 1.相应软件包 2.生成示例数据集 3.训练一个SVM 4.生成混淆矩阵 5.可视化边界 一.混淆矩阵概述 在训练了有监督的机器学习模型(例如分类器)之后,您想知道它的工作情况. 这通常是通过将一小部分称为测试集的数据分开来完成的,该数据用作模型以前从未见过的数据. 如果它在此数据集上表现良好,那么该模型很可能在其他数据上也表现良好 - 当然,如果它是从与您的测试集相同的分布中采样的. 现在,当您测试
-
详解使用python绘制混淆矩阵(confusion_matrix)
Summary 涉及到分类问题,我们经常需要通过可视化混淆矩阵来分析实验结果进而得出调参思路,本文介绍如何利用python绘制混淆矩阵(confusion_matrix),本文只提供代码,给出必要注释. Code # -*-coding:utf-8-*- from sklearn.metrics import confusion_matrix import matplotlib.pyplot as plt import numpy as np #labels表示你不同类别的代号,比如这里的de
-
python sklearn包——混淆矩阵、分类报告等自动生成方式
preface:做着最近的任务,对数据处理,做些简单的提特征,用机器学习算法跑下程序得出结果,看看哪些特征的组合较好,这一系列流程必然要用到很多函数,故将自己常用函数记录上.应该说这些函数基本上都会用到,像是数据预处理,处理完了后特征提取.降维.训练预测.通过混淆矩阵看分类效果,得出报告. 1.输入 从数据集开始,提取特征转化为有标签的数据集,转为向量.拆分成训练集和测试集,这里不多讲,在上一篇博客中谈到用StratifiedKFold()函数即可.在训练集中有data和target开始. 2.
-
Python实现两种多分类混淆矩阵
目录 1.什么是混淆矩阵 2.分类模型评价指标 3.两种多分类混淆矩阵 3.1直接打印出每一个类别的分类准确率. 3.2打印具体的分类结果的数值 4.总结 1.什么是混淆矩阵 深度学习中,混淆矩阵是ROC曲线绘制的基础,同时它也是衡量分类型模型准确度中最基本,最直观,计算最简单的方法.它可以直观地了解分类模型在每一类样本里面表现,常作为模型评估的一部分.它可以非常容易的表明多个类别是否有混淆(也就是一个class被预测成另一个class). 首先要明确几个概念: T或者F:该样本 是否被正确分类
-
python处理两种分隔符的数据集方法
在做机器学习的时候,遇到这样一个数据集... 一共399行10列, 1-9列是用不定长度的空格分割, 第9-10列之间用'\t'分割, 前九列都是数值类型,其中第三列有若干个'?'填充的缺失值... 第十列是字符串类型,.. 部分数据截图: 之前我是用python强写的...很麻烦,代码如下: 至此,可以已平均值,填充缺失值... 今天再回顾此数据库;决定用pandas库来试试; 1,导包,用pandas.read_table导入数据集, 2,数据处理 最后输出如下: 以上这篇python处理两
-
Python之两种模式的生产者消费者模型详解
第一种使用queue队列实现: #生产者消费者模型 其实服务器集群就是这个模型 # 这里介绍的是非yield方法实现过程 import threading,time import queue q = queue.Queue(maxsize=10) def Producer(anme): # for i in range(10): # q.put('骨头%s'%i) count = 1 while True: q.put('骨头%s'%count) print('生产了骨头',count) cou
-
对python中两种列表元素去重函数性能的比较方法
测试函数: 第一种:list的set函数 第二种:{}.fromkeys().keys() 测试代码: #!/usr/bin/python #-*- coding:utf-8 -*- import time import random l1 = [] leng = 10L for i in range(0,leng): temp = random.randint(1,10) l1.append(temp) print '测试列表长度为:',leng #first set last = time.
-
Python实现两种稀疏矩阵的最小二乘法
目录 最小二乘法 返回值 测试 最小二乘法 scipy.sparse.linalg实现了两种稀疏矩阵最小二乘法lsqr和lsmr,前者是经典算法,后者来自斯坦福优化实验室,据称可以比lsqr更快收敛. 这两个函数可以求解Ax=b,或arg minx ∥Ax−b∥2,或arg minx ∥Ax−b∥2 +d2∥x−x0∥2,其中A必须是方阵或三角阵,可以有任意秩. 通过设置容忍度at ,bt,可以控制算法精度,记r=b-Ax 为残差向量,如果Ax=b是相容的,lsqr在∥r∥⩽at∗∥A∥⋅∥x∥
-
python使用两种发邮件的方式smtp和outlook示例
smtp是直接调用163邮箱的smtp服务器,需要在163邮箱中设置一下.outlook发送就是Python直接调用win32方式.调用程序outlook直接发送邮件. import win32com.client as win32 import xlrd outlook = win32.Dispatch('outlook.application') mail = outlook.CreateItem(0) receivers = ['Yutao.A.Wang@alcatel-sbell.com
-
php两种无限分类方法实例
一.递归方法 复制代码 代码如下: $items = array( array('id'=>1,'pid'=>0,'name'=>'一级11'), array('id'=>2,'pid'=>0,'name'=>'一级12'), array('id'=>3,'pid'=>1,'name'=>'二级21'), array('id'=>4,'pid'=>3,'name'=>'三级31'), array('id'=>5,'pid'=&g
-
总结python实现父类调用两种方法的不同
python中有两种方法可以调用父类的方法: super(Child, self).method(args) Parent.method(self, args) 我用其中的一种报了如下错误: 找不到 classobj.当我把调用改为 super(B, self).f(name) 就能正确运行,且结果正确. 分析错误 因为基类没有继承 object , 在python中,一个可以这样创建: class A: pass 也可以这样创建: class A(object): pass 这两者的区别就是:
-
Python中的is和==比较两个对象的两种方法
Python中的is和==比较两个对象的两种方法 在Python中有两种方式比较两个对象是否相等,分别是is和==,两者之间是不同的 ==比较的是值(如同java中的equals方法) is比较的是引用(可以看作比较内存地址, 类似于java中的==) 对于: >>> n = 1 >>> n is 1 True >>> b = '1' >>> b is 1 False >>> n == b False 由于1和'1'