使用py-spy解决scrapy卡死的问题方法
背景
在使用scrapy爬取东西的时候,使用crontab定时的启动爬虫,但是发现机器上经常产生很多卡死的scrapy进程,一段时间不管的话,会导致有10几个进程都卡死在那,并且会导致数据产出延迟。
问题定位
使用py-spy这个非常好用的python性能分析工具来进行排查,py-spy可以查看一个python进程函数调用用时,类似unix下的top命令。所以我们用这个工具看看是什么函数一直在执行。
首先安装这个工具
pip install py-spy
用py-spy看看scrapy哪个函数执行时间长
# 先找到这个卡死的scrapy进程的pid ps -ef |grep scrapy # 启动 py-spy 观察这进程 py-spy top --pid 53424
首先我们按3,按OwnTime进行排序,这个表示函数自身执行的时间,可以看到read这个函数执行的时间最长,那看来是IO导致的,程序中的IO行为就是读写磁盘和网络IO,磁盘读写一般不会有问题,所以初步定位是网络IO导致的。
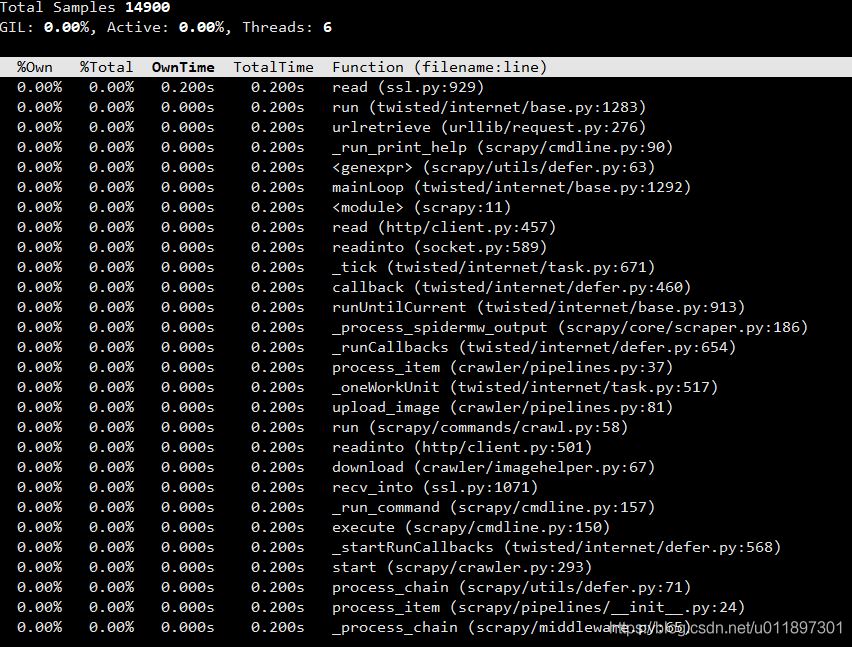
接下来进行进一步确认,再按4,按TotalTIme 所有子函数执行时间总和进行排序,可以看到是在process_item和download,upload_image这些主流程函数的执行时间比较长,这一步是先把图片下载到本地,然后上传到静床,看来是下载这步从网络中read数据时出现了问题,进一步追踪代码。

看下download的函数的代码:
if filename == '':
filename = os.path.basename(url)
path = path + '/' + filename
try:
res = request.urlretrieve(url,filename=path)
print(url,res)
return path
except Exception as e:
print('download img failed')
print(e)
return False
可以看到用了urllib这个库里面request.urlretrieve函数,这个函数是用来下载文件的,去看看python官网文档的函数说明,发现里面没有超时时间这个参数,所以是由于没有超时时间,导致一直在read,进而使得进程卡死。
urllib.request.urlretrieve(url, filename=None,reporthook=None,data=None)
解决方案
使用另一种方式来下载图片,使用支持超时时间的urlopen函数,封装成一个自定义的url_retrieve,这样就不再会出现没有超时导致的卡死问题了。
def url_retrieve(self,url, path):
r = request.urlopen(url, timeout=5)
res = False
with open(path,"wb") as f:
res = f.write(r.read())
f.flush()
f.close()
return res
到此这篇关于使用py-spy解决scrapy卡死的问题方法的文章就介绍到这了,更多相关scrapy卡死内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python使用scrapy解析js示例
复制代码 代码如下: from selenium import selenium class MySpider(CrawlSpider): name = 'cnbeta' allowed_domains = ['cnbeta.com'] start_urls = ['http://www.jb51.net'] rules = ( # Extract links matching 'category.php' (but not matching 'subsectio
-

零基础写python爬虫之使用Scrapy框架编写爬虫
网络爬虫,是在网上进行数据抓取的程序,使用它能够抓取特定网页的HTML数据.虽然我们利用一些库开发一个爬虫程序,但是使用框架可以大大提高效率,缩短开发时间.Scrapy是一个使用Python编写的,轻量级的,简单轻巧,并且使用起来非常的方便.使用Scrapy可以很方便的完成网上数据的采集工作,它为我们完成了大量的工作,而不需要自己费大力气去开发. 首先先要回答一个问题. 问:把网站装进爬虫里,总共分几步? 答案很简单,四步: 新建项目 (Project):新建一个新的爬虫项目 明确目标(Item
-
Python爬虫框架Scrapy安装使用步骤
一.爬虫框架Scarpy简介Scrapy 是一个快速的高层次的屏幕抓取和网页爬虫框架,爬取网站,从网站页面得到结构化的数据,它有着广泛的用途,从数据挖掘到监测和自动测试,Scrapy完全用Python实现,完全开源,代码托管在Github上,可运行在Linux,Windows,Mac和BSD平台上,基于Twisted的异步网络库来处理网络通讯,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片. 二.Scrapy安装指南 我们的安装步骤假设你已经安装一下内容:<1>
-
Python的Scrapy爬虫框架简单学习笔记
一.简单配置,获取单个网页上的内容. (1)创建scrapy项目 scrapy startproject getblog (2)编辑 items.py # -*- coding: utf-8 -*- # Define here the models for your scraped items # # See documentation in: # http://doc.scrapy.org/en/latest/topics/items.html from scrapy.item import
-
scrapy爬虫完整实例
本文主要通过实例介绍了scrapy框架的使用,分享了两个例子,爬豆瓣文本例程 douban 和图片例程 douban_imgs ,具体如下. 例程1: douban 目录树 douban --douban --spiders --__init__.py --bookspider.py --douban_comment_spider.py --doumailspider.py --__init__.py --items.py --pipelines.py --settings.py --scrap
-
Python实现从脚本里运行scrapy的方法
本文实例讲述了Python实现从脚本里运行scrapy的方法.分享给大家供大家参考.具体如下: 复制代码 代码如下: #!/usr/bin/python import os os.environ.setdefault('SCRAPY_SETTINGS_MODULE', 'project.settings') #Must be at the top before other imports from scrapy import log, signals, project from scrapy.x
-
Python3安装Scrapy的方法步骤
本文介绍了Python3安装Scrapy的方法步骤,分享给大家,具体如下: 运行平台:Windows Python版本:Python3.x IDE:Sublime text3 一.Scrapy简介 Scrapy是一个为了爬取网站数据提取结构性数据而编写的应用框架,可以应用于数据挖掘,信息处理或存储历史数据等一些列的程序中.Scrapy最初就是为了网络爬取而设计的.现在,Scrapy已经推出了曾承诺过的Python3.x版本. 为什么学习Scrapy呢?它能我们更好的完成爬虫任务,自己写Pytho
-
使用py-spy解决scrapy卡死的问题方法
背景 在使用scrapy爬取东西的时候,使用crontab定时的启动爬虫,但是发现机器上经常产生很多卡死的scrapy进程,一段时间不管的话,会导致有10几个进程都卡死在那,并且会导致数据产出延迟. 问题定位 使用py-spy这个非常好用的python性能分析工具来进行排查,py-spy可以查看一个python进程函数调用用时,类似unix下的top命令.所以我们用这个工具看看是什么函数一直在执行. 首先安装这个工具 pip install py-spy 用py-spy看看scrapy哪个函数执
-
解决Scrapy安装错误:Microsoft Visual C++ 14.0 is required...
问题描述 当前环境win10,python_3.6.1,64位. 在windows下,在dos中运行pip install Scrapy报错: building 'twisted.test.raiser' extension error: Microsoft Visual C++ 14.0 is required. Get it with "Microsoft Visual C++ Build Tools": http://landinghub.visualstudio.com/vis
-
解决.ui文件生成的.py文件运行不出现界面的方法
一般需要导入下面两个包 from PyQt5.QtWidgets import QApplication import sys 并且在.py文件中加入以下代码: if __name__ == "__main__": app = QtWidgets.QApplication(sys.argv) widget = QtWidgets.QWidget() ui = Ui_MainWindow() ui.setupUi(widget) widget.show() sys.exit(app.ex
-
python selenium UI自动化解决验证码的4种方法
本文介绍了python selenium UI自动化解决验证码的4种方法,分享给大家,具体如下: 测试环境 windows7+ firefox50+ geckodriver # firefox浏览器驱动 python3 selenium3 selenium UI自动化解决验证码的4种方法:去掉验证码.设置万能码.验证码识别技术-tesseract.添加cookie登录,本次主要讲解验证码识别技术-tesseract和添加cookie登录. 1. 去掉验证码 去掉验证码,直接通过用户名和密码登陆网
-
Django解决frame拒绝问题的方法
一.home页使用frame template/home.html <!DOCTYPE html> <html lang="en"> <meta http-equiv="Content-Type" content="text/html" charset="UTF-8"> <head> <title>自动化测试平台</title> </head>
-
解决python中文乱码问题方法总结
在运行这样类似的代码: #!/usr/bin/env pythons="中文"print s 最近经常遇到这样的问题: 问题一: SyntaxError: Non-ASCII character '\xe4' in file E:\coding\python\Untitled 6.py on line 3, but no encoding declared; see http://www.python.org/peps/pep-0263.html for details 问题二: Un
-
解决服务器运行jupyter notebook方法
目录 服务器运行jupyter notebook 虚拟环境 然后关防火墙 打开jupyter notebook 打开浏览器,跑起来 也可以将服务器换成本地的,建立一个隧道 本地打开没问题 今天教大家 服务器运行jupyter notebook 第一,给我买一台服务器 要知道公网ip 虚拟环境 mkvirtualenv -p /usr/bin/python3.6 deeplearn workon deeplearn pip install tensorflow pip install jupyte
-
已解决卸载pip重新安装的方法
目录 已解决卸载pip重新安装的方法 问题需求 卸载pip 安装pip 附录:安装pip的几种方式 1.脚本安装 2.源码包安装 3.python安装 4.easy_install 安装 已解决卸载pip重新安装的方法 问题需求 粉丝群里面的一个小伙伴遇到问题跑来私信我,想用卸载pip重新安装pip,但是发生了报错(当时他心里瞬间凉了一大截,跑来找我求助,然后顺利帮助他解决了,顺便记录一下希望可以帮助到更多遇到这个问题的小伙伴 卸载pip 执行下面的pip卸载命令: python -m pip
-
MySQL解决SQL注入的另类方法详解
本文实例讲述了MySQL解决SQL注入的另类方法.分享给大家供大家参考,具体如下: 问题解读 我觉得,这个问题每年带来的成本可以高达数十亿美元了.本文就来谈谈,假定我们有如下 SQL 模板语句: select * from T where f1 = '{value1}' and f2 = {value2} 现在我们需要根据用户输入值填充该语句: value1=hello value2=5 我们得到了下面的 SQL 语句,我们再提交给数据库: select * from T where f1='h
-
PHP基于回溯算法解决n皇后问题的方法示例
本文实例讲述了PHP基于回溯算法解决n皇后问题的方法.分享给大家供大家参考,具体如下: 这里对于n皇后问题就不做太多的介绍,相关的介绍与算法分析可参考前面一篇C++基于回溯法解决八皇后问题. 回溯法的基本做法是搜索,或是一种组织得井井有条的,能避免不必要搜索的穷举式搜索法.这种方法适用于解一些组合数相当大的问题. 回溯法在问题的解空间树中,按深度优先策略,从根结点出发搜索解空间树.算法搜索至解空间树的任意一点时,先判断该结点是否包含问题的解.如果肯定不包含,则跳过对该结点为根的子树的搜索,逐层向