教你使用Python建立任意层数的深度神经网络
目录
- 一、神经网络介绍:
- 二、数据集
- 三、激活函数
- 四、正向传播
- 五、损失函数
- 六、反向传播
- 七、总体思路
一、神经网络介绍:
神经网络算法参考人的神经元原理(轴突、树突、神经核),在很多神经元基础上构建神经网络模型,每个神经元可看作一个个学习单元。这些神经元采纳一定的特征作为输入,根据自身的模型得到输出。

图1 神经网络构造的例子(符号说明:上标[l]表示与第l层;上标(i)表示第i个例子;下标i表示矢量第i项)

图2 单层神经网络示例
神经元模型是先计算一个线性函数(z=Wx+b),接着再计算一个激活函数。一般来说,神经元模型的输出值是a=g(Wx+b),其中g是激活函数(sigmoid,tanh, ReLU, …)。
二、数据集
假设有一个很大的数据库,里面记录了很多天气数据,例如,气温、湿度、气压和降雨率。
问题陈述:
一组训练数据m_train,下雨标记为(1),不下雨标记为(0)。
一个测试数据组m_test,标记是否下雨。
每一个天气数据包含x1=气温,x2=湿度,x3=气压。
机器学习中一个常见的预处理步骤是将数据集居中并标准化,这意味着从每个示例中减去整个numpy数组的平均值,然后将每个示例除以整个numpy数组的标准偏差。

通用方法(建立部分算法)
使用深度学习来建造模型
1. 定义模型构造(例如,数据的输入特征)
2. 初始化参数并定义超参数(迭代次数、在神经网络中的L层的层数、隐藏层大小、学习率α)
3. 迭代循环(正向传播(计算电流损耗)、计算成本函数、反向传播(计算电流损耗)、升级参数(使用背景参数和梯度))
4. 使用训练参数来预测标签(初始化)
更深层次的L-层神经网络的初始化更为复杂,因为有更多的权重矩阵和偏置向量。下表展示了不同结构的各种层级。

表1 L层的权重矩阵w、偏置向量b和激活函数z

表2 示例架构中的神经网络权重矩阵w、偏置向量b和激活函数z
表2帮助我们为图1中的示例神经网络架构的矩阵准备了正确的维度。
import numpy as np
import matplotlib.pyplot as plt
nn_architecture = [
{"layer_size": 4,"activation": "none"}, # input layer
{"layer_size": 5,"activation": "relu"},
{"layer_size": 4,"activation": "relu"},
{"layer_size": 3,"activation": "relu"},
{"layer_size": 1,"activation": "sigmoid"}
]
def initialize_parameters(nn_architecture, seed = 3):
np.random.seed(seed)
# python dictionary containingour parameters "W1", "b1", ..., "WL","bL"
parameters = {}
number_of_layers = len(nn_architecture)
for l in range(1,number_of_layers):
parameters['W' + str(l)] =np.random.randn(
nn_architecture[l]["layer_size"],
nn_architecture[l-1]["layer_size"]
) * 0.01
parameters['b' + str(l)] =np.zeros((nn_architecture[l]["layer_size"], 1))
return parameters
代码段1 参数初始化
使用小随机数初始化参数是一种简单的方法,但同时也保证算法的起始值足够好。
记住:
- 不同的初始化工具,例如Zero,Random, He or Xavier,都会导致不同的结果。
- 随机初始化能够确保不同的隐藏单元可以学习不同的东西(初始化所有权重为零会导致,所有层次的所有感知机都将学习相同的东西)。
- 不要初始化为太大的值
三、激活函数
激活函数的作用是为了增加神经网络的非线性。下例将使用sigmoid and ReLU。
Sigmoid输出一个介于0和1之间的值,这使得它成为二进制分类的一个很好的选择。如果输出小于0.5,可以将其分类为0;如果输出大于0.5,可以将其分类为1。
def sigmoid(Z):
S = 1 / (1 + np.exp(-Z))
return S
def relu(Z):
R = np.maximum(0, Z)
return R
def sigmoid_backward(dA, Z):
S = sigmoid(Z)
dS = S * (1 - S)
return dA * dS
def relu_backward(dA, Z):
dZ = np.array(dA, copy=True)
dZ[Z <= 0] = 0
return dZ
代码段2 Sigmoid和ReLU激活函数,及其衍生物
在代码段2中,可以看到激活函数及其派生的矢量化编程实现。该代码将用于进一步的计算。
四、正向传播
在正向传播中,在层l的正向函数中,需要知道该层中的激活函数是哪一种(sigmoid、tanh、ReLU等)。前一层的输出值为这一层的输入值,先计算z,再用选定的激活函数计算。

图3 神经网络的正向传播
线性正向模块(对所有示例进行矢量化)计算以下方程式:

方程式1 线性正向函数
def L_model_forward(X, parameters, nn_architecture):
forward_cache = {}
A = X
number_of_layers = len(nn_architecture)
for l in range(1, number_of_layers):
A_prev = A
W = parameters['W' + str(l)]
b = parameters['b' + str(l)]
activation = nn_architecture[l]["activation"]
Z, A = linear_activation_forward(A_prev, W, b, activation)
forward_cache['Z' + str(l)] = Z
forward_cache['A' + str(l)] = A
AL = A
return AL, forward_cache
def linear_activation_forward(A_prev, W, b, activation):
if activation == "sigmoid":
Z = linear_forward(A_prev, W, b)
A = sigmoid(Z)
elif activation == "relu":
Z = linear_forward(A_prev, W, b)
A = relu(Z)
return Z, A
def linear_forward(A, W, b):
Z = np.dot(W, A) + b
return Z
代码段3 正向传播模型
使用“cache”(python字典包含为特定层所计算的a和z值)以在正向传播至相应的反向传播期间传递变量。它包含用于反向传播计算导数的有用值。
五、损失函数
为了管程学习过程,需要计算代价函数的值。下面的公式用于计算成本。
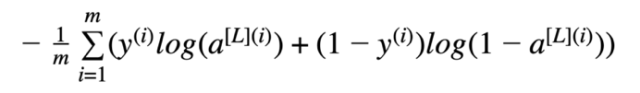
方程式2 交叉熵成本
def compute_cost(AL, Y):
m = Y.shape[1]
# Compute loss from AL and y
logprobs = np.multiply(np.log(AL), Y) + np.multiply(1 - Y, np.log(1 - AL))
# cross-entropy cost
cost = - np.sum(logprobs) / m
cost = np.squeeze(cost)
return cost
代码段4 代价函数的计算
六、反向传播
反向传播用于计算参数的损失函数梯度。该算法是由微分学中已知的“链规则”递归使用的。
反向传播计算中使用的公式:

方程式3 反向传播计算公式
链式法则是计算复合函数导数的公式。复合函数就是函数套函数。

方程式4 链规则示例
“链规则”在计算损失时十分重要(以方程式5为例)。

方程式5 损失函数(含替换数据)及其相对于第一权重的导数
神经网络模型反向传播的第一步是计算最后一层损失函数相对于z的导数。方程式6由两部分组成:方程式2损失函数的导数(关于激活函数)和激活函数“sigmoid”关于最后一层Z的导数。

方程式6 从4层对z的损失函数导数
方程式6的结果可用于计算方程式3的导数。

方程式7 损失函数相对于3层的导数
在进一步计算中,使用了与第三层激活函数有关的损失函数的导数(方程式7)。
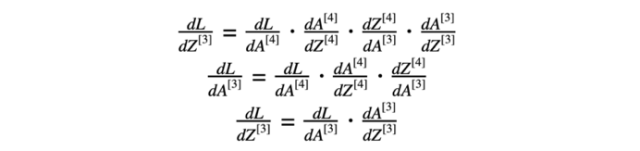
方程式8 第三层的导数
方程式7的结果和第三层活化函数“relu”的导数用于计算方程式8的导数(损失函数相对于z的导数)。然后,我们对方程式3进行了计算。
我们对方程9和10做了类似的计算。
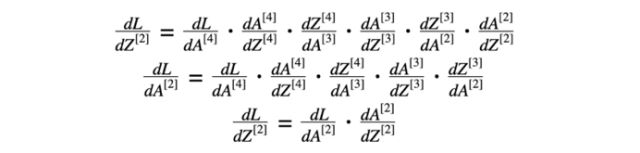
方程式9 第二层的导数

方程式10 第一层的导数
七、总体思路
从第一层层对z的损失函数导数有助于计算(L-1)层(上一层)对损失函数的导数。结果将用于计算激活函数的导数。

图4 神经网络的反向传播
def L_model_backward(AL, Y, parameters, forward_cache, nn_architecture):
grads = {}
number_of_layers =len(nn_architecture)
m = AL.shape[1]
Y = Y.reshape(AL.shape) # afterthis line, Y is the same shape as AL
# Initializing thebackpropagation
dAL = - (np.divide(Y, AL) -np.divide(1 - Y, 1 - AL))
dA_prev = dAL
for l in reversed(range(1,number_of_layers)):
dA_curr = dA_prev
activation =nn_architecture[l]["activation"]
W_curr = parameters['W' +str(l)]
Z_curr = forward_cache['Z' +str(l)]
A_prev = forward_cache['A' +str(l-1)]
dA_prev, dW_curr, db_curr =linear_activation_backward(dA_curr, Z_curr, A_prev, W_curr, activation)
grads["dW" +str(l)] = dW_curr
grads["db" +str(l)] = db_curr
return grads
def linear_activation_backward(dA, Z, A_prev, W, activation):
if activation =="relu":
dZ = relu_backward(dA, Z)
dA_prev, dW, db =linear_backward(dZ, A_prev, W)
elif activation =="sigmoid":
dZ = sigmoid_backward(dA, Z)
dA_prev, dW, db =linear_backward(dZ, A_prev, W)
return dA_prev, dW, db
def linear_backward(dZ, A_prev, W):
m = A_prev.shape[1]
dW = np.dot(dZ, A_prev.T) / m
db = np.sum(dZ, axis=1,keepdims=True) / m
dA_prev = np.dot(W.T, dZ)
return dA_prev, dW, db
代码段5 反向传播模块
更新参数
该函数的目标是通过梯度优化来更新模型的参数。
def update_parameters(parameters, grads, learning_rate):
L = len(parameters)
for l in range(1, L):
parameters["W" +str(l)] = parameters["W" + str(l)] - learning_rate *grads["dW" + str(l)]
parameters["b" +str(l)] = parameters["b" + str(l)] - learning_rate *grads["db" + str(l)]
return parameters
全模型
神经网络模型的完整实现包括在片段中提供的方法。
def L_layer_model(X, Y, nn_architecture, learning_rate = 0.0075,num_iterations = 3000, print_cost=False):
np.random.seed(1)
# keep track of cost
costs = []
# Parameters initialization.
parameters =initialize_parameters(nn_architecture)
# Loop (gradient descent)
for i in range(0,num_iterations):
# Forward propagation:[LINEAR -> RELU]*(L-1) -> LINEAR -> SIGMOID.
AL, forward_cache =L_model_forward(X, parameters, nn_architecture)
# Compute cost.
cost = compute_cost(AL, Y)
# Backward propagation.
grads = L_model_backward(AL,Y, parameters, forward_cache, nn_architecture)
# Update parameters.
parameters =update_parameters(parameters, grads, learning_rate)
# Print the cost every 100training example
if print_cost and i % 100 ==0:
print("Cost afteriteration %i: %f" %(i, cost))
costs.append(cost)
# plot the cost
plt.plot(np.squeeze(costs))
plt.ylabel('cost')
plt.xlabel('iterations (pertens)')
plt.title("Learning rate=" + str(learning_rate))
plt.show()
return parameters
代码段7 整个神经网络模型
只需要将已知的权重和系列测试数据,应用于正向传播模型,就能预测结果。
可以修改snippet1中的nn_架构,以构建具有不同层数和隐藏层大小的神经网络。此外,准备正确实现激活函数及其派生函数(代码段2)。所实现的函数可用于修改代码段3中的线性正向激活方法和代码段5中的线性反向激活方法。
进一步改进
如果训练数据集不够大,则可能面临“过度拟合”问题。这意味着所学的网络不会概括为它从未见过的新例子。可以使用正则化方法,如L2规范化(它包括适当地修改成本函数)或退出(它在每次迭代中随机关闭一些感知机)。
我们使用梯度下降来更新参数和最小化成本。你可以学习更多高级优化方法,这些方法可以加快学习速度,甚至可以为成本函数提供更好的最终价值,例如:
- 小批量梯度下降
- 动力
- Adam优化器


参考:http://www.uml.org.cn/ai/201911251.asp
到此这篇关于Python建立任意层数的深度神经网络的文章就介绍到这了,更多相关Python神经网络内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python实现BP神经网络回归预测模型
神经网络模型一般用来做分类,回归预测模型不常见,本文基于一个用来分类的BP神经网络,对它进行修改,实现了一个回归模型,用来做室内定位.模型主要变化是去掉了第三层的非线性转换,或者说把非线性激活函数Sigmoid换成f(x)=x函数.这样做的主要原因是Sigmoid函数的输出范围太小,在0-1之间,而回归模型的输出范围较大.模型修改如下: 代码如下: #coding: utf8 '''' author: Huangyuliang ''' import json import random impo
-
Python实现Keras搭建神经网络训练分类模型教程
我就废话不多说了,大家还是直接看代码吧~ 注释讲解版: # Classifier example import numpy as np # for reproducibility np.random.seed(1337) # from keras.datasets import mnist from keras.utils import np_utils from keras.models import Sequential from keras.layers import Dense, Act
-
Python利用神经网络解决非线性回归问题实例详解
本文实例讲述了Python利用神经网络解决非线性回归问题.分享给大家供大家参考,具体如下: 问题描述 现在我们通常使用神经网络进行分类,但是有时我们也会进行回归分析. 如本文的问题: 我们知道一个生物体内的原始有毒物质的量,然后对这个生物体进行治疗,向其体内注射一个物质,过一段时间后重新测量这个生物体内有毒物质量的多少. 因此,问题中有两个输入,都是标量数据,分别为有毒物质的量和注射物质的量,一个输出,也就是注射治疗物质后一段时间生物体的有毒物质的量. 数据如下图: 其中Dose of Myco
-
用Python实现BP神经网络(附代码)
用Python实现出来的机器学习算法都是什么样子呢? 前两期线性回归及逻辑回归项目已发布(见文末链接),今天来讲讲BP神经网络. BP神经网络 全部代码 https://github.com/lawlite19/MachineLearning_Python/blob/master/NeuralNetwok/NeuralNetwork.py 神经网络model 先介绍个三层的神经网络,如下图所示 输入层(input layer)有三个units( 为补上的bias,通常设为1) 表示第j层的第i个
-
python神经网络编程实现手写数字识别
本文实例为大家分享了python实现手写数字识别的具体代码,供大家参考,具体内容如下 import numpy import scipy.special #import matplotlib.pyplot class neuralNetwork: def __init__(self,inputnodes,hiddennodes,outputnodes,learningrate): self.inodes=inputnodes self.hnodes=hiddennodes self.onodes
-
教你使用Python建立任意层数的深度神经网络
目录 一.神经网络介绍: 二.数据集 三.激活函数 四.正向传播 五.损失函数 六.反向传播 七.总体思路 一.神经网络介绍: 神经网络算法参考人的神经元原理(轴突.树突.神经核),在很多神经元基础上构建神经网络模型,每个神经元可看作一个个学习单元.这些神经元采纳一定的特征作为输入,根据自身的模型得到输出. 图1 神经网络构造的例子(符号说明:上标[l]表示与第l层:上标(i)表示第i个例子:下标i表示矢量第i项) 图2 单层神经网络示例 神经元模型是先计算一个线性函数(z=Wx+b),接着再计
-
Python利用keras接口实现深度神经网络回归
目录 1 写在前面 2 代码分解介绍 2.1 准备工作 2.2 参数配置 2.3 数据导入与数据划分 2.4 联合分布图绘制 2.5 因变量分离与数据标准化 2.6 原有模型删除 2.7 最优Epoch保存与读取 2.8 模型构建 2.9 训练图像绘制 2.10 最优Epoch选取 2.11 模型测试.拟合图像绘制.精度验证与模型参数与结果保存 3 完整代码 1 写在前面 前期一篇文章Python TensorFlow深度学习回归代码:DNNRegressor详细介绍了基于TensorFlow
-
如何教少儿学习Python编程
如何给少儿讲编程? 1.首先给少儿讲编程一定要简单,通俗易懂. 因为少儿接触的事务比较少,你要用形象的少儿可以接受的方式让他们理解. 2.讲编程的速度一定要慢. 因为少儿的接受能力相对较弱一些,所以要适当调慢步骤. 3.讲编程一定要少儿亲手实践. 因为编程本来就是抽象的事物,如果不进行练习的话,少儿不能很好理解抽象的事物. 4.一定要多复习. 少儿的自觉力差些,课上一定要先复习再讲新的知识. 知识点扩展: 我们需要明确,给孩子上编程课的目的是什么 我想,对于中小学年龄段的孩子,编程课的主要目的应
-
教你用Python实现一个轮盘抽奖小游戏
一.Python GUI 编程简介 Tkinter 模块(Tk 接口)是 Python 的标准 Tk GUI 工具包的接口 .Tk 和 Tkinter 可以在大多数的 Unix 平台下使用,同样可以应用在 Windows 和 Macintosh 系统里.Tk8.0 的后续版本可以实现本地窗口风格,并良好地运行在绝大多数平台中. wxPython 是一款开源软件,是 Python 语言的一套优秀的 GUI 图形库,允许 Python 程序员很方便的创建完整的.功能健全的 GUI 用户界面. pyq
-
手把手教你实现Python连接数据库并快速取数的工具
目录 前言 一.数据库连接类 二.数据提取主函数模块 在数据生产应用部门,取数分析是一个很常见的需求,实际上业务人员需求时刻变化,最高效的方式是让业务部门自己来取,减少不必要的重复劳动,一般情况下,业务部门数据库表结构一般是固定的,根据实际业务将取数需求做成sql 脚本,快速完成数据获取---授人以渔的方式,提供平台或工具 那如何实现一个自助取数查询工具? 基于底层数据来开发不难,无非是将用户输入变量作为筛选条件,将参数映射到 sql 语句,并生成一个 sql 语句然后再去数据库执行 前言 最后
-
Python获取任意xml节点值的方法
本文实例讲述了Python获取任意xml节点值的方法.分享给大家供大家参考.具体实现方法如下: # -*- coding: utf-8 -*- import xml.dom.minidom ELEMENT_NODE = xml.dom.Node.ELEMENT_NODE class SimpleXmlGetter(object): def __init__(self, data): if type(data) == str: self.root = xml.dom.minidom.parse(d
-
教你用Python脚本快速为iOS10生成图标和截屏
简介 这两天更新完Xcode8之后发现Xcode对图标的要求又有了变化,之前用的一个小应用"IconKit"还没赶上节奏,已经不能满足Xcode8的要求了. 于是就想起来用Python自己做个脚本来生成图标. 其实这个脚本很早就写了,现在为了适应iOS10,就修改完善下,并且放到了 GitHub . 可以看看效果图: 代码: #encoding=utf-8 #by 不灭的小灯灯 #create date 2016/5/22 #update 2016/9/21 #support iOS
-
教你用 Python 实现微信跳一跳(Mac+iOS版)
这几天看网上好多微信跳一跳破解了,不过都是安卓的,无奈苹果不是开源也没办法.这个教程是 Mac + iOS , 要下xcode 要配置环境小白估计是没戏了,有iOS 开发经验的可以看看 .不过其实可以没事帮同事刷一下,让他们请吃个饭什么的,哈哈. 先发个战果 一.WebDriverAgent 首先去 https://github.com/facebook/WebDriverAgent 下一份代码 选择 WebDriverAgentRunner 用真机 然后 test 运行一下 , 看到IP地址就
-
Python建立Map写Excel表实例解析
本文主要研究的是用Python语言建立Map写Excel表的相关代码,具体如下. 前言:我们已经能够很熟练的写Excel表相关的脚本了.大致的操作就是,从数据库中取数据,建立Excel模板,然后根据模板建立一个新的Excel表,把数据库中的数据写入.最后发送邮件.之前的一篇记录博客,写的很标准了.这里我们说点遇到的新问题. 我们之前写类似脚本的时候,有个问题没有考虑过,为什么要建立模板然后再写入数据呢?诶-其实也不算是没考虑过,只是懒没有深究罢了.只求快点完成任务... 这里对这个问题进行思考阐
-
手把手教你用python抢票回家过年(代码简单)
首先看看如何快速查看剩余火车票? 当你想查询一下火车票信息的时候,你还在上12306官网吗?或是打开你手机里的APP?下面让我们来用Python写一个命令行版的火车票查看器, 只要在命令行敲一行命令就能获得你想要的火车票信息!如果你刚掌握了Python基础,这将是个不错的小练习. 接口设计 一个应用写出来最终是要给人使用的,哪怕只是给你自己使用.所以,首先应该想想你希望怎么使用它?让我们先给这个小应用起个名字吧,既然及查询票务信息,那就叫它tickets好了.我们希望用户只要输入出发站,到达站以