Python实现CART决策树算法及详细注释
目录
- 一、CART决策树算法简介
- 二、基尼系数
- 三、CART决策树生成算法
- 四、CART算法的Python实现
- 五、运行结果
一、CART决策树算法简介
CART(Classification And Regression Trees 分类回归树)算法是一种树构建算法,既可以用于分类任务,又可以用于回归。相比于 ID3 和 C4.5 只能用于离散型数据且只能用于分类任务,CART 算法的适用面要广得多,既可用于离散型数据,又可以处理连续型数据,并且分类和回归任务都能处理。
本文仅讨论基本的CART分类决策树构建,不讨论回归树和剪枝等问题。
首先,我们要明确以下几点:
1. CART算法是二分类常用的方法,由CART算法生成的决策树是二叉树,而 ID3 以及 C4.5 算法生成的决策树是多叉树,从运行效率角度考虑,二叉树模型会比多叉树运算效率高。
2. CART算法通过基尼(Gini)指数来选择最优特征。
二、基尼系数
基尼系数代表模型的不纯度,基尼系数越小,则不纯度越低,注意这和 C4.5的信息增益比的定义恰好相反。
分类问题中,假设有K个类,样本点属于第k类的概率为pk,则概率分布的基尼系数定义为:

若CART用于二类分类问题(不是只能用于二分类),那么概率分布的基尼系数可简化为
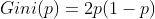
假设使用特征 A 将数据集 D 划分为两部分 D1 和 D2,此时按照特征 A 划分的数据集的基尼系数为:

三、CART决策树生成算法
输入:训练数据集D,停止计算的条件
输出:CART决策树
根据训练数据集,从根结点开始,递归地对每个结点进行以下操作,构建二叉决策树:
(1)计算现有特征对该数据集的基尼指数,如上面所示;
(2)选择基尼指数最小的值对应的特征为最优特征,对应的切分点为最优切分点(若最小值对应的特征或切分点有多个,随便取一个即可);
(3)按照最优特征和最优切分点,从现结点生成两个子结点,将训练数据集中的数据按特征和属性分配到两个子结点中;
(4)对两个子结点递归地调用(1)(2)(3),直至满足停止条件。
(5)生成CART树。
算法停止的条件:结点中的样本个数小于预定阈值,或样本集的基尼指数小于预定阈值(样本基本属于同一类,如完全属于同一类则为0),或者特征集为空。
注:最优切分点是将当前样本下分为两类(因为我们要构造二叉树)的必要条件。对于离散的情况,最优切分点是当前最优特征的某个取值;对于连续的情况,最优切分点可以是某个具体的数值。具体应用时需要遍历所有可能的最优切分点取值去找到我们需要的最优切分点。
四、CART算法的Python实现
若是二分类问题,则函数calcGini和choose_best_feature可简化如下:
# 计算样本属于第1个类的概率p
def calcProbabilityEnt(dataset):
numEntries = len(dataset)
count = 0
label = dataset[0][len(dataset[0]) - 1]
for example in dataset:
if example[-1] == label:
count += 1
probabilityEnt = float(count) / numEntries
return probabilityEnt
def choose_best_feature(dataset):
# 特征总数
numFeatures = len(dataset[0]) - 1
# 当只有一个特征时
if numFeatures == 1:
return 0
# 初始化最佳基尼系数
bestGini = 1
# 初始化最优特征
index_of_best_feature = -1
for i in range(numFeatures):
# 去重,每个属性值唯一
uniqueVals = set(example[i] for example in dataset)
# 定义特征的值的基尼系数
Gini = {}
for value in uniqueVals:
sub_dataset1, sub_dataset2 = split_dataset(dataset,i,value)
prob1 = len(sub_dataset1) / float(len(dataset))
prob2 = len(sub_dataset2) / float(len(dataset))
probabilityEnt1 = calcProbabilityEnt(sub_dataset1)
probabilityEnt2 = calcProbabilityEnt(sub_dataset2)
Gini[value] = prob1 * 2 * probabilityEnt1 * (1 - probabilityEnt1) + prob2 * 2 * probabilityEnt2 * (1 - probabilityEnt2)
if Gini[value] < bestGini:
bestGini = Gini[value]
index_of_best_feature = i
best_split_point = value
return index_of_best_feature, best_split_point
五、运行结果

到此这篇关于Python实现CART决策树算法及详细注释的文章就介绍到这了,更多相关Python策树算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现ID3决策树算法
ID3决策树是以信息增益作为决策标准的一种贪心决策树算法 # -*- coding: utf-8 -*- from numpy import * import math import copy import cPickle as pickle class ID3DTree(object): def __init__(self): # 构造方法 self.tree = {} # 生成树 self.dataSet = [] # 数据集 self.labels = [] # 标签集 # 数据导入函数
-

python实现C4.5决策树算法
C4.5算法使用信息增益率来代替ID3的信息增益进行特征的选择,克服了信息增益选择特征时偏向于特征值个数较多的不足.信息增益率的定义如下: # -*- coding: utf-8 -*- from numpy import * import math import copy import cPickle as pickle class C45DTree(object): def __init__(self): # 构造方法 self.tree = {} # 生成树 self.dataSet =
-
Python机器学习之决策树算法
一.决策树原理 决策树是用样本的属性作为结点,用属性的取值作为分支的树结构. 决策树的根结点是所有样本中信息量最大的属性.树的中间结点是该结点为根的子树所包含的样本子集中信息量最大的属性.决策树的叶结点是样本的类别值.决策树是一种知识表示形式,它是对所有样本数据的高度概括决策树能准确地识别所有样本的类别,也能有效地识别新样本的类别. 决策树算法ID3的基本思想: 首先找出最有判别力的属性,把样例分成多个子集,每个子集又选择最有判别力的属性进行划分,一直进行到所有子集仅包含同一类型的数据为止.最后
-
Python机器学习之决策树算法实例详解
本文实例讲述了Python机器学习之决策树算法.分享给大家供大家参考,具体如下: 决策树学习是应用最广泛的归纳推理算法之一,是一种逼近离散值目标函数的方法,在这种方法中学习到的函数被表示为一棵决策树.决策树可以使用不熟悉的数据集合,并从中提取出一系列规则,机器学习算法最终将使用这些从数据集中创造的规则.决策树的优点为:计算复杂度不高,输出结果易于理解,对中间值的缺失不敏感,可以处理不相关特征数据.缺点为:可能产生过度匹配的问题.决策树适于处理离散型和连续型的数据. 在决策树中最重要的就是如何选取
-
Python实现CART决策树算法及详细注释
目录 一.CART决策树算法简介 二.基尼系数 三.CART决策树生成算法 四.CART算法的Python实现 五.运行结果 一.CART决策树算法简介 CART(Classification And Regression Trees 分类回归树)算法是一种树构建算法,既可以用于分类任务,又可以用于回归.相比于 ID3 和 C4.5 只能用于离散型数据且只能用于分类任务,CART 算法的适用面要广得多,既可用于离散型数据,又可以处理连续型数据,并且分类和回归任务都能处理. 本文仅讨论基本的CAR
-
python实现坦克大战游戏 附详细注释
本文实例为大家分享了python实现坦克大战的具体代码,供大家参考,具体内容如下 #功能实现游戏主窗口 import pygame,time,random#导入模块 _display = pygame.display#赋值给一个变量 调用时方便 color_red = pygame.Color(255,0,0)#同上 v class MainGame(object): screen_width = 900#游戏界面宽度 screen_height = 550#界面的高度 Tank_p1 = No
-
解读python如何实现决策树算法
数据描述 每条数据项储存在列表中,最后一列储存结果 多条数据项形成数据集 data=[[d1,d2,d3...dn,result], [d1,d2,d3...dn,result], . . [d1,d2,d3...dn,result]] 决策树数据结构 class DecisionNode: '''决策树节点 ''' def __init__(self,col=-1,value=None,results=None,tb=None,fb=None): '''初始化决策树节点 args: col -
-
python代码实现ID3决策树算法
本文实例为大家分享了python实现ID3决策树算法的具体代码,供大家参考,具体内容如下 ''''' Created on Jan 30, 2015 @author: 史帅 ''' from math import log import operator import re def fileToDataSet(fileName): ''''' 此方法功能是:从文件中读取样本集数据,样本数据的格式为:数据以空白字符分割,最后一列为类标签 参数: fileName:存放样本集数据的文件路径 返回值:
-
Python画图小案例之多啦A梦叮当猫超详细注释
一步步教你怎么用Python画多啦A梦叮当猫,进一步熟悉Python的基础画图操作. 分析:叮当猫由头.脸.眼.眼珠.鼻子.嘴.胡子.项带.铃当.身子.围嘴.手臂.手.脚组成. 其中:头.脸.眼.眼珠.鼻子.嘴.胡子组成一个部件:其余元件组成一个部件.废话不多说,上代码. 希望您给个关注给个赞,也算对我们的支持了. import math import sys from PyQt5.QtCore import * from PyQt5.QtGui import * from PyQt5.QtWi
-
Python机器学习应用之基于决策树算法的分类预测篇
目录 一.决策树的特点 1.优点 2.缺点 二.决策树的适用场景 三.demo 一.决策树的特点 1.优点 具有很好的解释性,模型可以生成可以理解的规则. 可以发现特征的重要程度. 模型的计算复杂度较低. 2.缺点 模型容易过拟合,需要采用减枝技术处理. 不能很好利用连续型特征. 预测能力有限,无法达到其他强监督模型效果. 方差较高,数据分布的轻微改变很容易造成树结构完全不同. 二.决策树的适用场景 决策树模型多用于处理自变量与因变量是非线性的关系. 梯度提升树(GBDT),XGBoost以及L
-
Pytorch实现图像识别之数字识别(附详细注释)
使用了两个卷积层加上两个全连接层实现 本来打算从头手撕的,但是调试太耗时间了,改天有时间在从头写一份 详细过程看代码注释,参考了下一个博主的文章,但是链接没注意关了找不到了,博主看到了联系下我,我加上 代码相关的问题可以评论私聊,也可以翻看博客里的文章,部分有详细解释 Python实现代码: import torch import torch.nn as nn import torch.optim as optim from torchvision import datasets, transf