Java面试题之HashMap 的 hash 方法原理是什么
Warning:这是《Java 程序员进阶之路》专栏的第 55 篇。
回来后小二找到了我,于是我就写下了这篇文章丢给他,并严厉地告诉他:再搞不懂就别来找我。听到这句话,心头一阵酸,小二绷不住差点要哭 😭。
PS:本文 GitHub 上已同步,有 GitHub 账号的小伙伴,记得看完后给二哥安排一波 star 呀!冲一波 GitHub 的 trending 榜单,求求各位了。
GitHub 地址:https://github.com/itwanger/toBeBetterJavaer
来看一下 hash 方法的源码(JDK 8 中的 HashMap):
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
这段代码究竟是用来干嘛的呢?
我们都知道,key.hashCode() 是用来获取键位的哈希值的,理论上,哈希值是一个 int 类型,范围从-2147483648 到 2147483648。前后加起来大概 40 亿的映射空间,只要哈希值映射得比较均匀松散,一般是不会出现哈希碰撞的。
但问题是一个 40 亿长度的数组,内存是放不下的。HashMap 扩容之前的数组初始大小只有 16,所以这个哈希值是不能直接拿来用的,用之前要和数组的长度做取模运算,用得到的余数来访问数组下标才行。
取模运算有两处。
取模运算(“Modulo Operation”)和取余运算(“Remainder Operation ”)两个概念有重叠的部分但又不完全一致。主要的区别在于对负整数进行除法运算时操作不同。取模主要是用于计算机术语中,取余则更多是数学概念。
一处是往 HashMap 中 put 的时候(putVal 方法中):
final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) {
HashMap.Node<K,V>[] tab; HashMap.Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
tab[i] = newNode(hash, key, value, null);
}
一处是从 HashMap 中 get 的时候(getNode 方法中):
final Node<K,V> getNode(int hash, Object key) {
Node<K,V>[] tab; Node<K,V> first, e; int n; K k;
if ((tab = table) != null && (n = tab.length) > 0 &&
(first = tab[(n - 1) & hash]) != null) {}
}
其中的 (n - 1) & hash 正是取模运算,就是把哈希值和(数组长度-1)做了一个“与”运算。
可能大家在疑惑:取模运算难道不该用 % 吗?为什么要用 & 呢?
这是因为 & 运算比 % 更加高效,并且当 b 为 2 的 n 次方时,存在下面这样一个公式。
a % b = a & (b-1)
用 2 n 2^n 2n 替换下 b 就是:

我们来验证一下,假如 a = 14,b = 8,也就是 2 3 2^3 23,n=3。
14%8,14 的二进制为 1110,8 的二进制 1000,8-1 = 7 的二进制为 0111,1110&0111=0110,也就是 0* 2 0 2^0 20+1* 2 1 2^1 21+1* 2 2 2^2 22+0* 2 3 2^3 23=0+2+4+0=6,14%8 刚好也等于 6。
这也正好解释了为什么 HashMap 的数组长度要取 2 的整次方。
因为(数组长度-1)正好相当于一个“低位掩码”——这个掩码的低位最好全是 1,这样 & 操作才有意义,否则结果就肯定是 0,那么 & 操作就没有意义了。
a&b 操作的结果是:a、b 中对应位同时为 1,则对应结果位为 1,否则为 0
2 的整次幂刚好是偶数,偶数-1 是奇数,奇数的二进制最后一位是 1,保证了 hash &(length-1) 的最后一位可能为 0,也可能为 1(这取决于 h 的值),即 & 运算后的结果可能为偶数,也可能为奇数,这样便可以保证哈希值的均匀性。
& 操作的结果就是将哈希值的高位全部归零,只保留低位值,用来做数组下标访问。
假设某哈希值为 10100101 11000100 00100101,用它来做取模运算,我们来看一下结果。HashMap 的初始长度为 16(内部是数组),16-1=15,二进制是 00000000 00000000 00001111(高位用 0 来补齐):
10100101 11000100 00100101
& 00000000 00000000 00001111
----------------------------------
00000000 00000000 00000101
因为 15 的高位全部是 0,所以 & 运算后的高位结果肯定是 0,只剩下 4 个低位 0101,也就是十进制的 5,也就是将哈希值为 10100101 11000100 00100101 的键放在数组的第 5 位。
明白了取模运算后,我们再来看 put 方法的源码:
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
以及 get 方法的源码:
public V get(Object key) {
HashMap.Node<K,V> e;
return (e = getNode(hash(key), key)) == null ? null : e.value;
}
它们在调用 putVal 和 getNode 之前,都会先调用 hash 方法:
static final int hash(Object key) {
int h;
return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16);
}
那为什么取模运算之前要调用 hash 方法呢?
看下面这个图。
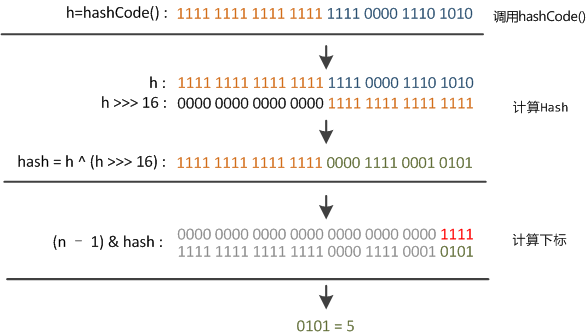
某哈希值为 11111111 11111111 11110000 1110 1010,将它右移 16 位(h >>> 16),刚好是 00000000 00000000 11111111 11111111,再进行异或操作(h ^ (h >>> 16)),结果是 11111111 11111111 00001111 00010101
异或(^)运算是基于二进制的位运算,采用符号 XOR 或者^来表示,运算规则是:如果是同值取 0、异值取 1
由于混合了原来哈希值的高位和低位,所以低位的随机性加大了(掺杂了部分高位的特征,高位的信息也得到了保留)。
结果再与数组长度-1(00000000 00000000 00000000 00001111)做取模运算,得到的下标就是 00000000 00000000 00000000 00000101,也就是 5。
还记得之前我们假设的某哈希值 10100101 11000100 00100101 吗?在没有调用 hash 方法之前,与 15 做取模运算后的结果也是 5,我们不妨来看看调用 hash 之后的取模运算结果是多少。
某哈希值 00000000 10100101 11000100 00100101(补齐 32 位),将它右移 16 位(h >>> 16),刚好是 00000000 00000000 00000000 10100101,再进行异或操作(h ^ (h >>> 16)),结果是 00000000 10100101 00111011 10000000
结果再与数组长度-1(00000000 00000000 00000000 00001111)做取模运算,得到的下标就是 00000000 00000000 00000000 00000000,也就是 0。
综上所述,hash 方法是用来做哈希值优化的,把哈希值右移 16 位,也就正好是自己长度的一半,之后与原哈希值做异或运算,这样就混合了原哈希值中的高位和低位,增大了随机性。
说白了,hash 方法就是为了增加随机性,让数据元素更加均衡的分布,减少碰撞。
到此这篇关于Java面试题之HashMap 的 hash 方法原理是什么的文章就介绍到这了,更多相关Java HashMap内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java京东面试题之为什么HashMap线程不安全
目录 01.多线程下扩容会死循环 02.多线程下 put 会导致元素丢失 03.put 和 get 并发时会导致 get 到 null 01.多线程下扩容会死循环 众所周知,HashMap 是通过拉链法来解决哈希冲突的,也就是当哈希冲突时,会将相同哈希值的键值对通过链表的形式存放起来. JDK 7 时,采用的是头部插入的方式来存放链表的,也就是下一个冲突的键值对会放在上一个键值对的前面(同一位置上的新元素被放在链表的头部).扩容的时候就有可能导致出现环形链表,造成死循环. resize 方法的源
-
java编程进阶小白也能手写HashMap代码
目录 什么是HashMap HashCode和数组 Hash碰撞 toString方法 百万级数据压测 步骤 1 来100w条数据,看看要花多久? 步骤 2 设计思路 步骤 3 添加一个size 步骤 4 先设计,后实现 步骤 5 扩容方法 步骤 6 reHash方法 步骤 7 新的问题出现 步骤 8 indexForTable方法 步骤 9 重新转测 步骤 10 再次测试100w数据 步骤 11 PK 原生JDK8的HashMap 补丁 步骤 1 put元素的bug 步骤 2 HashMap为
-
Java详解HashMap实现原理和源码分析
目录 学习要点: 1.什么是HashMap? 2.HashMap的特性 3.HashMap的数据结构 4.HashMap初始化操作 4.1.成员变量 4.2. 构造方法 5.Jdk8中HashMap的算法 5.1.HashMap中散列算法 5.2.什么是HashMap中哈希冲突? 6.Jdk8中HashMap的put操作 7.HashMap的扩容机制 7.1.什么时候需要扩容? 7.2.什么是HashMap的扩容? 7.3.resize的源码实现 8.Jdk8中HashMap的remove操作
-
Java8 HashMap遍历方式性能探讨
原因: keySet其实是遍历了2次,一次是转为Iterator对象,另一次是从hashMap中取出key所对应的value.而entrySet只是遍历了一次就把key和value都放到了entry中,效率更高.如果是JDK8,使用Map.foreach方法. 一. keySet和entrySet Map<String, String> map = new HashMap<String, String>(); int num = 5000000; String key, value
-
Java中HashMap集合的常用方法详解
目录 public Object clone() 总结 public Object clone() 返回hashMap集合的副本 其余的方法都是实现Map集合的 //www.jb51.net/article/227296.htm 总结 本篇文章就到这里了,希望能够给你带来帮助,也希望您能够多多关注我们的更多内容!
-
java中Hashmap的get方法使用
目录 java中Hashmap的get方法 举例 HashMap中get方法的原理 1.首先向get()方法中传递一个key 2.在get()方法中调用hash(key) 3.在get()方法中调用getNode(hash,key)方法 4.getNode()方法中 java中Hashmap的get方法 map中存储的是键值对,也就是说通过set方法进行参数和值的存储,之后通过get"键"的形式进行值的读取. 举例 Map map = new Hashmap();//创建一个map m
-
Java使用HashMap映射实现消费抽奖功能
本文实例为大家分享了Java实现消费抽奖功能的具体代码,供大家参考,具体内容如下 要求如下: 1.定义奖项类Awards,包含成员变量String类型的name(奖项名称)和int类型的count(奖项数量). 2.定义抽奖类DrawReward,包含成员变量Map<Integer, Awards> 类型的rwdPool(奖池对象).该类实现功能如下:a) 构造方法中对奖池对象初始化,本实验要求提供不少于4类奖品,每类奖品数量为有限个,每类奖品对应唯一的键值索引(抽奖号).b) 实现抽奖方法d
-
Java面试题之HashMap 的 hash 方法原理是什么
Warning:这是<Java 程序员进阶之路>专栏的第 55 篇. 回来后小二找到了我,于是我就写下了这篇文章丢给他,并严厉地告诉他:再搞不懂就别来找我.听到这句话,心头一阵酸,小二绷不住差点要哭
-
Java源码解析HashMap的keySet()方法
HashMap的keySet()方法比较简单,作用是获取HashMap中的key的集合.虽然这个方法十分简单,似乎没有什么可供分析的,但真正看了源码,发现自己还是有很多不懂的地方.下面是keySet的代码. public Set<K> keySet() { Set<K> ks = keySet; if (ks == null) { ks = new KeySet(); keySet = ks; } return ks; } 从代码中了解到,第一次调用keySet方法时,keySet
-
java面试题——详解HashMap和Hashtable 的区别
一.HashMap 和Hashtable 的区别 我们先看2个类的定义 public class Hashtable extends Dictionary implements Map, Cloneable, java.io.Serializable public class HashMap extends AbstractMap implements Map, Cloneable, Serializable 可见Hashtable 继承自 Dictiionary 而 HashMap继承自Abs
-
java遍历HashMap简单的方法
本文实例讲述了java遍历HashMap简单的方法.分享给大家供大家参考.具体实现方法如下: import java.util.HashMap; import java.util.Iterator; import java.util.Set; public class HashSetTest { public static void main(String[] args) { HashMap map = new HashMap(); map.put("a", "aa"
-
Java编程实现用hash方法切割文件
Hash,一般翻译做"散列",也有直接音译为"哈希"的,就是把任意长度的输入(又叫做预映射, pre-image),通过散列算法,变换成固定长度的输出,该输出就是散列值.这种转换是一种压缩映射,也就是,散列值的空间通常远小于输入的空间,不同的输入可能会散列成相同的输出,所以不可能从散列值来唯一的确定输入值.简单的说就是一种将任意长度的消息压缩到某一固定长度的消息摘要的函数. 如果有大型数据文件(如每行为url或者ip或者单词等的),以G为单位的,处理的时候需先切分.
-
java中JSONObject转换为HashMap(方法+main方法调用实例)
1.首先要导入json相关的jar包 引入的jar包: (版本自行定义,可以选用使用人数偏多的版本,这样比较稳定) commons-beanutils-1.9.2.jar commons-collections-3.2.1.jar commons-lang-2.6.jar commons-logging-1.2.jar ezmorph-1.0.6.jar json-lib-2.4-jdk15.jar jar包的下载可以去下面这个网址搜索: https://mvnrepository.com/ 2
-
Java 面试题和答案 -(上)
本文我们将要讨论Java面试中的各种不同类型的面试题,它们可以让雇主测试应聘者的Java和通用的面向对象编程的能力.下面的章节分为上下两篇,第一篇将要讨论面向对象编程和它的特点,关于Java和它的功能的常见问题,Java的集合类,垃圾收集器,第二篇主要讨论异常处理,Java小应用程序,Swing,JDBC,远程方法调用(RMI),Servlet和JSP. 开始! 目录 面向对象编程(OOP) 常见的Java问题 Java线程 Java集合类 垃圾收集器 面向对象编程(OOP) Java是一个支持
-
Java面试题及答案集锦(基础题122道,代码题19道)
Java基础面试题及答案集锦(基础题122道,代码题19道),具体详情如下所示: 1.面向对象的特征有哪些方面 1.抽象: 抽象就是忽略一个主题中与当前目标无关的那些方面,以便更充分地注意与当前目标有关的方面.抽象并不打算了解全部问题,而只是选择其中的一部分,暂时不用部分细节.抽象包括两个方面,一是过程抽象,二是数据抽象. 2.继承: 继承是一种联结类的层次模型,并且允许和鼓励类的重用,它提供了一种明确表述共性的方法.对象的一个新类可以从现有的类中派生,这个过程称为类继承.新类继承了原始类的特性
-
阿里、华为、腾讯Java技术面试题精选
阿里.华为.腾讯Java技术面试题精选,具体内容如下 JVM的类加载机制是什么?有哪些实现方式? 类加载机制: 类的加载指的是将类的.class文件中的二进制数据读入到内存中,将其放在运行时数据区的方法去内,然后在堆区创建一个java.lang.Class对象,用来封装在方法区内的数据结构.类的加载最终是在堆区内的Class对象,Class对象封装了类在方法区内的数据结构,并且向Java程序员提供了访问方法区内的数据结构的接口. 类加载有三种方式: 1)命令行启动应用时候由JVM初始化加载 2)