Python机器学习NLP自然语言处理基本操作之Seq2seq的用法
概述
从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁.

Seq2seq
Seq2seq 由 Encoder 和 Decoder 两个 RNN 组成. Encoder 将变长序列输出, 编码成 encoderstate 再由 Decoder 输出变长序列.
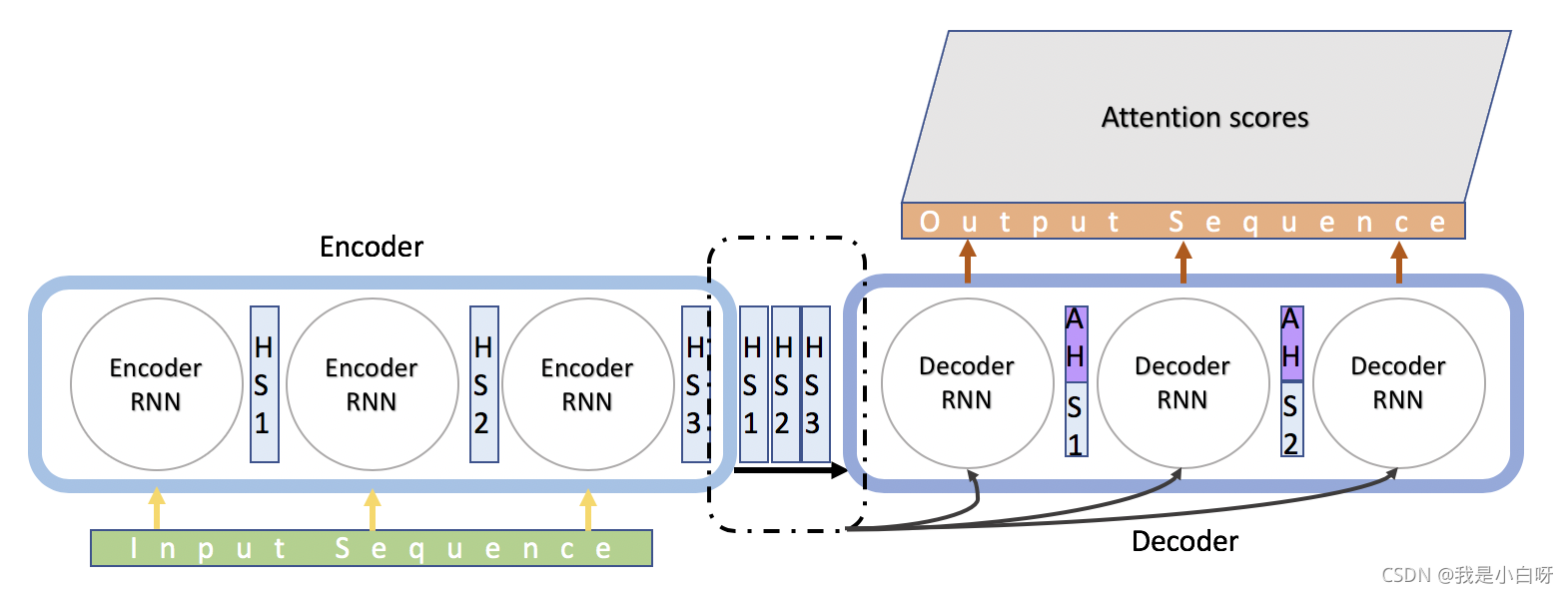
Seq2seq 的使用领域:
- 机器翻译: Encoder-Decoder 的最经典应用
- 文本摘要: 输入是一段文本序列, 输出是这段文本序列的摘要序列
- 阅读理解: 将输入的文章和问题分别编码, 再对其进行解码得到问题的答案
- 语音识别: 输入是语音信号序列, 输出是文字序列

优点:
- 非常灵活: 并不限制 Encoder, Decoder 使用何种神经网络, 也不限制输入和输出的状态
- 端到端: 将语义理解和语言生成结合在了一起, 而不是分开处理
缺点:
- 信息损失: 无论输入如何变化, Encoder 给出的都是一个固定维数的向量. 在生成文本时, 生成每个词所用到的语义向量都是一样的, 过于简单
Attention 模型
Attention 是一种用于提升 RNN 的 Encoder 和 Decoder 模型的效果的机制. 广泛应用于机器翻译, 语音识别, 图像标注等多个领域. 深度学习中的注意力机制从本质上讲和人类的选择性视觉注意力机制类似. 核心目标也是从众多信息中选择出对当前任务目标更关键的信息.
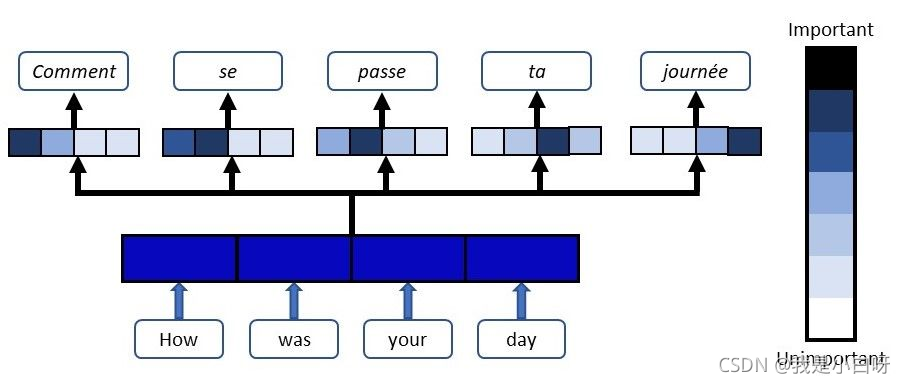
Attention 实质上是一种 content-based addressing 的机制. 即从网络中某些状态集合中选取给定状态较为相似的状态, 进而做后续的信息抽取.

首先根据 Encoder 和 Decoder 的特征计算权值, 然后对 Encoder 的特征进行加权求和, 作为 Decoder 的输入. 其作用的将 Encoder 的特征以更好的方式呈献给 Decoder. (并不是所有的 context 都对下一个状态的生成产生影响, Attention 就是选择恰当的 context 用它生成下一个状态.
Seq2seq 模型
# Copyright 2015 The TensorFlow Authors. All Rights Reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
# ==============================================================================
"""Sequence-to-sequence model with an attention mechanism."""
from __future__ import absolute_import
from __future__ import division
from __future__ import print_function
import random
import numpy as np
from six.moves import xrange # pylint: disable=redefined-builtin
import tensorflow as tf
import data_utils
setattr(tf.contrib.rnn.GRUCell, '__deepcopy__', lambda self, _: self)
setattr(tf.contrib.rnn.BasicLSTMCell, '__deepcopy__', lambda self, _: self)
setattr(tf.contrib.rnn.MultiRNNCell, '__deepcopy__', lambda self, _: self)
class Seq2SeqModel(object):
"""Sequence-to-sequence model with attention and for multiple buckets.
This class implements a multi-layer recurrent neural network as encoder,
and an attention-based decoder. This is the same as the model described in
this paper: http://arxiv.org/abs/1412.7449 - please look there for details,
or into the seq2seq library for complete model implementation.
This class also allows to use GRU cells in addition to LSTM cells, and
sampled softmax to handle large output vocabulary size. A single-layer
version of this model, but with bi-directional encoder, was presented in
http://arxiv.org/abs/1409.0473
and sampled softmax is described in Section 3 of the following paper.
http://arxiv.org/abs/1412.2007
"""
def __init__(self,
source_vocab_size,
target_vocab_size,
buckets,
size,
num_layers,
max_gradient_norm,
batch_size,
learning_rate,
learning_rate_decay_factor,
use_lstm=False,
num_samples=512,
forward_only=False,
dtype=tf.float32):
"""Create the model.
Args:
source_vocab_size: size of the source vocabulary.
target_vocab_size: size of the target vocabulary.
buckets: a list of pairs (I, O), where I specifies maximum input length
that will be processed in that bucket, and O specifies maximum output
length. Training instances that have inputs longer than I or outputs
longer than O will be pushed to the next bucket and padded accordingly.
We assume that the list is sorted, e.g., [(2, 4), (8, 16)].
size: number of units in each layer of the model.
num_layers: number of layers in the model.
max_gradient_norm: gradients will be clipped to maximally this norm.
batch_size: the size of the batches used during training;
the model construction is independent of batch_size, so it can be
changed after initialization if this is convenient, e.g., for decoding.
learning_rate: learning rate to start with.
learning_rate_decay_factor: decay learning rate by this much when needed.
use_lstm: if true, we use LSTM cells instead of GRU cells.
num_samples: number of samples for sampled softmax. #??
forward_only: if set, we do not construct the backward pass in the model.
dtype: the data type to use to store internal variables.
"""
self.source_vocab_size = source_vocab_size
self.target_vocab_size = target_vocab_size
self.buckets = buckets
self.batch_size = batch_size
self.learning_rate = tf.Variable(
float(learning_rate), trainable=False, dtype=dtype)
self.learning_rate_decay_op = self.learning_rate.assign(
self.learning_rate * learning_rate_decay_factor)
self.global_step = tf.Variable(0, trainable=False)
# If we use sampled softmax, we need an output projection.
output_projection = None
softmax_loss_function = None
# Sampled softmax only makes sense if we sample less than vocabulary size.
if num_samples > 0 and num_samples < self.target_vocab_size:
w_t = tf.get_variable("proj_w", [self.target_vocab_size, size], dtype=dtype)
w = tf.transpose(w_t)
b = tf.get_variable("proj_b", [self.target_vocab_size], dtype=dtype)
output_projection = (w, b)
def sampled_loss(labels, logits):
labels = tf.reshape(labels, [-1, 1])
# We need to compute the sampled_softmax_loss using 32bit floats to
# avoid numerical instabilities.
local_w_t = tf.cast(w_t, tf.float32)
local_b = tf.cast(b, tf.float32)
local_inputs = tf.cast(logits, tf.float32)
return tf.cast(
tf.nn.sampled_softmax_loss(
weights=local_w_t,
biases=local_b,
labels=labels,
inputs=local_inputs,
num_sampled=num_samples,
num_classes=self.target_vocab_size),
dtype)
softmax_loss_function = sampled_loss
# Create the internal multi-layer cell for our RNN.
def single_cell():
return tf.contrib.rnn.GRUCell(size)
if use_lstm:
def single_cell():
return tf.contrib.rnn.BasicLSTMCell(size)
cell = single_cell()
if num_layers > 1:
cell = tf.contrib.rnn.MultiRNNCell([single_cell() for _ in range(num_layers)])
# The seq2seq function: we use embedding for the input and attention.
def seq2seq_f(encoder_inputs, decoder_inputs, do_decode):
return tf.contrib.legacy_seq2seq.embedding_attention_seq2seq(
encoder_inputs,
decoder_inputs,
cell,
num_encoder_symbols=source_vocab_size,
num_decoder_symbols=target_vocab_size,
embedding_size=size,
output_projection=output_projection,
feed_previous=do_decode,
dtype=dtype)
# Feeds for inputs. 从这边可以看出不同bucket是共用一组参数
self.encoder_inputs = []
self.decoder_inputs = []
self.target_weights = []
for i in xrange(buckets[-1][0]): # Last bucket is the biggest one.
self.encoder_inputs.append(tf.placeholder(tf.int32, shape=[None],
name="encoder{0}".format(i)))
for i in xrange(buckets[-1][1] + 1): # 因为增加了“go”标志
self.decoder_inputs.append(tf.placeholder(tf.int32, shape=[None],
name="decoder{0}".format(i)))
self.target_weights.append(tf.placeholder(dtype, shape=[None],
name="weight{0}".format(i)))
# Our targets are decoder inputs shifted by one. decoder_inputs[0]没有用
targets = [self.decoder_inputs[i + 1]
for i in xrange(len(self.decoder_inputs) - 1)]
# Training outputs and losses.
'''
lambda x, y的x是指encoder_inputs,y是指decoder_inputs
'''
if forward_only:
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs, self.decoder_inputs, targets,
self.target_weights, buckets, lambda x, y: seq2seq_f(x, y, True),
softmax_loss_function=softmax_loss_function)
# If we use output projection, we need to project outputs for decoding.
if output_projection is not None:
for b in xrange(len(buckets)):
self.outputs[b] = [
tf.matmul(output, output_projection[0]) + output_projection[1]
for output in self.outputs[b]
]
else:
self.outputs, self.losses = tf.contrib.legacy_seq2seq.model_with_buckets(
self.encoder_inputs, self.decoder_inputs, targets,
self.target_weights, buckets,
lambda x, y: seq2seq_f(x, y, False),
softmax_loss_function=softmax_loss_function)
# Gradients and SGD update operation for training the model.
params = tf.trainable_variables()
if not forward_only:
self.gradient_norms = []
self.updates = []
opt = tf.train.GradientDescentOptimizer(self.learning_rate)
for b in xrange(len(buckets)):
gradients = tf.gradients(self.losses[b], params)
clipped_gradients, norm = tf.clip_by_global_norm(gradients,
max_gradient_norm)
self.gradient_norms.append(norm)
self.updates.append(opt.apply_gradients(
zip(clipped_gradients, params), global_step=self.global_step))
self.saver = tf.train.Saver(tf.global_variables())
def step(self, session, encoder_inputs, decoder_inputs, target_weights,
bucket_id, forward_only):
"""Run a step of the model feeding the given inputs.
Args:
session: tensorflow session to use.
encoder_inputs: list of numpy int vectors to feed as encoder inputs.
decoder_inputs: list of numpy int vectors to feed as decoder inputs.
target_weights: list of numpy float vectors to feed as target weights.
bucket_id: which bucket of the model to use.
forward_only: whether to do the backward step or only forward.
Returns:
A triple consisting of gradient norm (or None if we did not do backward),
average perplexity, and the outputs.
Raises:
ValueError: if length of encoder_inputs, decoder_inputs, or
target_weights disagrees with bucket size for the specified bucket_id.
"""
# Check if the sizes match.
encoder_size, decoder_size = self.buckets[bucket_id]
#encoder_inputs的shape为(encoder_size,batch_size)
if len(encoder_inputs) != encoder_size:
raise ValueError("Encoder length must be equal to the one in bucket,"
" %d != %d." % (len(encoder_inputs), encoder_size))
if len(decoder_inputs) != decoder_size:
raise ValueError("Decoder length must be equal to the one in bucket,"
" %d != %d." % (len(decoder_inputs), decoder_size))
if len(target_weights) != decoder_size:
raise ValueError("Weights length must be equal to the one in bucket,"
" %d != %d." % (len(target_weights), decoder_size))
# Input feed: encoder inputs, decoder inputs, target_weights, as provided.
input_feed = {}
for k in xrange(encoder_size):
input_feed[self.encoder_inputs[k].name] = encoder_inputs[k]
for k in xrange(decoder_size):
input_feed[self.decoder_inputs[k].name] = decoder_inputs[k]
input_feed[self.target_weights[k].name] = target_weights[k]
# Since our targets are decoder inputs shifted by one, we need one more.
last_target = self.decoder_inputs[decoder_size].name
input_feed[last_target] = np.zeros([self.batch_size], dtype=np.int32)
# Output feed: depends on whether we do a backward step or not.
if not forward_only:
output_feed = [self.updates[bucket_id], # Update Op that does SGD.
self.gradient_norms[bucket_id], # Gradient norm.
self.losses[bucket_id]] # Loss for this batch.
else:
output_feed = [self.losses[bucket_id]] # Loss for this batch.
for l in xrange(decoder_size): # Output logits.
output_feed.append(self.outputs[bucket_id][l])
outputs = session.run(output_feed, input_feed)
if not forward_only:
return outputs[1], outputs[2], None # Gradient norm, loss, no outputs.
else:
return None, outputs[0], outputs[1:] # No gradient norm, loss, outputs.
'''
根据指定bucket_id,产生batch_encoder_inputs和batch_decoder_inputs
这里batch_encoder_inputs和batch_decoder_inputs的shape都由原来的(batch_size,encoder_size)
变为(encoder_size,batch_size),方便进行batch训练
'''
def get_batch(self, data, bucket_id):
"""Get a random batch of data from the specified bucket, prepare for step.
To feed data in step(..) it must be a list of batch-major vectors, while
data here contains single length-major cases. So the main logic of this
function is to re-index data cases to be in the proper format for feeding.
Args:
data: a tuple of size len(self.buckets) in which each element contains
lists of pairs of input and output data that we use to create a batch.
bucket_id: integer, which bucket to get the batch for.
Returns:
The triple (encoder_inputs, decoder_inputs, target_weights) for
the constructed batch that has the proper format to call step(...) later.
"""
encoder_size, decoder_size = self.buckets[bucket_id]
encoder_inputs, decoder_inputs = [], []
# Get a random batch of encoder and decoder inputs from data,
# pad them if needed, reverse encoder inputs and add GO to decoder.
for _ in xrange(self.batch_size):
encoder_input, decoder_input = random.choice(data[bucket_id])
# Encoder inputs are padded and then reversed.
encoder_pad = [data_utils.PAD_ID] * (encoder_size - len(encoder_input))
encoder_inputs.append(list(reversed(encoder_input + encoder_pad)))
# Decoder inputs get an extra "GO" symbol, and are padded then.
decoder_pad_size = decoder_size - len(decoder_input) - 1
decoder_inputs.append([data_utils.GO_ID] + decoder_input +
[data_utils.PAD_ID] * decoder_pad_size)
# Now we create batch-major vectors from the data selected above.
batch_encoder_inputs, batch_decoder_inputs, batch_weights = [], [], []
# Batch encoder inputs are just re-indexed encoder_inputs.
#encoder_inputs的shape为(batch_size,encoder_size)
#batch_encoder_inputs的shape为(encoder_size,batch_size)
for length_idx in xrange(encoder_size):
batch_encoder_inputs.append(
np.array([encoder_inputs[batch_idx][length_idx]
for batch_idx in xrange(self.batch_size)], dtype=np.int32))
# Batch decoder inputs are re-indexed decoder_inputs, we create weights.
for length_idx in xrange(decoder_size):
batch_decoder_inputs.append(
np.array([decoder_inputs[batch_idx][length_idx]
for batch_idx in xrange(self.batch_size)], dtype=np.int32))
# Create target_weights to be 0 for targets that are padding.
batch_weight = np.ones(self.batch_size, dtype=np.float32)
for batch_idx in xrange(self.batch_size):
# We set weight to 0 if the corresponding target is a PAD symbol.
# The corresponding target is decoder_input shifted by 1 forward.
if length_idx < decoder_size - 1:
target = decoder_inputs[batch_idx][length_idx + 1]
#如果到底decoder的最后一个单词或target为pad,则不需要比较,即不考虑这一部分的损失函数
if length_idx == decoder_size - 1 or target == data_utils.PAD_ID:
batch_weight[batch_idx] = 0.0
batch_weights.append(batch_weight) #shape为(encoder_size,batch_size)
return batch_encoder_inputs, batch_decoder_inputs, batch_weights
到此这篇关于Python机器学习NLP自然语言处理基本操作之Seq2seq的用法的文章就介绍到这了,更多相关Python Seq2seq内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python机器学习NLP自然语言处理基本操作家暴归类
目录 概述 数据介绍 词频统计 朴素贝叶斯 代码实现 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 数据介绍 该数据是家庭暴力的一份司法数据.分为 4 个不同类别: 报警人被老公打,报警人被老婆打,报警人被儿子打,报警人被女儿打. 今天我们就要运用我们前几次学到的知识, 来实现一个 NLP 分类问题. 词频统计 CountVectorizer是一个文本特征提取的方
-
Python机器学习NLP自然语言处理基本操作之京东评论分类
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 数据介绍 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天
-
Python机器学习NLP自然语言处理基本操作电影影评分析
目录 概述 RNN 权重共享 计算过程 LSTM 阶段 代码 预处理 主函数 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. RNN RNN (Recurrent Neural Network), 即循环神经网络. RNN 相较于 CNN, 可以帮助我们更好的处理序列信息, 挖掘前后信息之间的联系. 对于 NLP 这类的任务, 语料的前后概率有极大的联系. 比如: "明天天气真好&
-
Python机器学习NLP自然语言处理基本操作词袋模型
概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词袋模型 词袋模型 (Bag of Words Model) 能帮助我们把一个句子转换为向量表示. 词袋模型把文本看作是无序的词汇集合, 把每一单词都进行统计. 向量化 词袋模型首先会进行分词, 在分词之后. 通过通过统计在每个词在文本中出现的次数. 我们就可以得到该文本基于词语的特征, 如果将各个文本样本的这些词与对应的词频放在一起
-
Python机器学习NLP自然语言处理基本操作关键词
目录 概述 关键词 TF-IDF 关键词提取 TF IDF TF-IDF jieba TF-IDF 关键词抽取 jieba 词性 不带关键词权重 附带关键词权重 TextRank 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 关键词 关键词 (keywords), 即关键词语. 关键词能描述文章的本质, 在文献检索, 自动文摘, 文本聚类 / 分类等方面有着重要的应用. 关键词抽
-
Python机器学习NLP自然语言处理基本操作词向量模型
目录 概述 词向量 词向量维度 Word2Vec CBOW 模型 Skip-Gram 模型 负采样模型 词向量的训练过程 1. 初始化词向量矩阵 2. 神经网络反向传播 词向量模型实战 训练模型 使用模型 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了.
-
Python机器学习NLP自然语言处理Word2vec电影影评建模
目录 概述 词向量 词向量维度 代码实现 预处理 主程序 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 词向量 我们先来说说词向量究竟是什么. 当我们把文本交给算法来处理的时候, 计算机并不能理解我们输入的文本, 词向量就由此而生了. 简单的来说, 词向量就是将词语转换成数字组成的向量. 当我们描述一个人的时候, 我们会使用身高体重等种种指标, 这些指标就可以当做向量. 有了向量
-
Python机器学习NLP自然语言处理基本操作之Seq2seq的用法
概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. Seq2seq Seq2seq 由 Encoder 和 Decoder 两个 RNN 组成. Encoder 将变长序列输出, 编码成 encoderstate 再由 Decoder 输出变长序列. Seq2seq 的使用领域: 机器翻译: Encoder-Decoder 的最经典应用 文本摘要: 输入是一段文本序列, 输出是这段文本
-
Python机器学习NLP自然语言处理基本操作之精确分词
目录 概述 分词器 jieba 安装 精确分词 全模式 搜索引擎模式 获取词性 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 分词器 jieba jieba 算法基于前缀词典实现高效的词图扫描, 生成句子中汉字所有可能成词的情况所构成的有向无环图. 通过动态规划查找最大概率路径, 找出基于词频的最大切分组合. 对于未登录词采用了基于汉字成词能力的 HMM 模型, 使用 Viter
-
Python机器学习NLP自然语言处理基本操作新闻分类
目录 概述 TF-IDF 关键词提取 TF IDF TF-IDF TfidfVectorizer 数据介绍 代码实现 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. TF-IDF 关键词提取 TF-IDF (Term Frequency-Inverse Document Frequency), 即词频-逆文件频率是一种用于信息检索与数据挖掘的常用加权技术. TF-IDF 可以帮助我
-
Python机器学习NLP自然语言处理基本操作之命名实例提取
目录 概述 命名实例 HMM 随机场 马尔科夫随机场 CRF 命名实例实战 数据集 crf 预处理 主程序 概述 从今天开始我们将开启一段自然语言处理 (NLP) 的旅程. 自然语言处理可以让来处理, 理解, 以及运用人类的语言, 实现机器语言和人类语言之间的沟通桥梁. 命名实例 命名实例 (Named Entity) 指的是 NLP 任务中具有特定意义的实体, 包括人名, 地名, 机构名, 专有名词等. 举个例子: Luke Rawlence 代表人物 Aiimi 和 University o