Python多进程multiprocessing、进程池用法实例分析
本文实例讲述了Python多进程multiprocessing、进程池用法。分享给大家供大家参考,具体如下:
内容相关:
multiprocessing:
- 进程的创建与运行
- 进程常用相关函数
进程池:
- 为什么要有进程池
- 进程池的创建与运行:串行、并行
- 回调函数
多进程multiprocessing:
python中的多进程需要使用multiprocessing模块
- 多进程的创建与运行:
1.进程的创建:进程对象=multiprocessing.Process(target=函数名,args=(参数,))【补充,由于args是一个元组,单个参数时要加“,”】
2.进程的运行: 进程对象.start()
进程的join跟线程的join一样,意义是 “阻塞当前进程,直到调用join方法的那个进程执行完,再继续执行当前进程”
注:在windows中代码中必须使用这个 ,在Linux 中不需要加这个
,在Linux 中不需要加这个
import multiprocessing,time,os
def thread_run():
print(threading.current_thread())
def run(name):
time.sleep(1)
print("hello",name,"run in ",os.getpid(),"ppid:",os.getppid())
if __name__=='__main__':#必须加
obj=[]
for i in range(10):
p=multiprocessing.Process(target=run,args=('bob',))
obj.append(p)
p.start()
start_time=time.time()
for i in obj:
i.join()
print("run in main")
print("spend time :",time.time()-start_time)
- 与多线程同样的:也可以通过继承multiprocessing的Process来创建进程
继承multiprocessing的Process类的类要主要做两件事:
1.如果初始化自己的变量,则先要调用父类的__init__()【如果不调用,则要自己填写相关的参数,麻烦!】然后做自己的初始化;如果不需要初始化自己的变量,那么不需要重写__init__,直接使用父类的__init__即可【已经继承了】
2.重写run函数
import multiprocessing
class myProcess(multiprocessing.Process):
def run(self):
print("run in myProcess")
if __name__=="__main__":
p=myProcess()
p.start()
p.join()
进程常用相关函数:
- os.getpid():获取当前进程号。
- os.getppid():获取当前进程的父进程号。
- 进程对象.is_alive():判断进程是否存活

- 进程对象.terminate():结束进程【不建议的方法,现实少用】
进程池:
- 为什么需要进程池
- 如果要启动大量的子进程,可以用进程池的方式批量创建子进程,而进程池可以限制运行的进程的数量【有太多人想要游泳,而池子的容量决定了游泳的人的数量
- Pool类可以提供指定数量的进程供用户调用,当有新的请求提交到Pool中时,如果池还没有满,就会创建一个新的进程来执行请求。如果进程池满了,请求就会告知先等待,直到池中有进程结束,才会创建新的进程来执行这些请求
- 进程池的创建与使用:
- 使用进程池需要导入:from multiprocessing import Pool
- 创建进程池:进程池对象=Pool(容量)
- 给进程池添加进程:
- 串行:进程池对象.apply(func=函数名,args=(参数,))
from multiprocessing import Pool
import time,os
def func1(i):
time.sleep(1)
print("run in process:",os.getpid())
if __name__=="__main__":
pool=Pool(5)
start_time = time.time()
for i in range(10):
pool.apply(func=func1,args=(i,))#串行,这里是加一个运行完再加一个
pool.close()#先close再等待
pool.join()
print("main run done,spend_time:",time.time()-start_time)
- 并行:进程池对象.apply_async(func=函数名,args=(参数,),callback=回调函数)
from multiprocessing import Pool
import time,os
def func1(i):
time.sleep(1)
print("run in process:",os.getpid())
if __name__=="__main__":
pool=Pool(5)
start_time = time.time()
for i in range(10):
pool.apply_async(func=func1,args=(i,))#并行
pool.close()#先close再等待
pool.join()
print("main run done,spend_time:",time.time()-start_time)#2.6,证明是并行
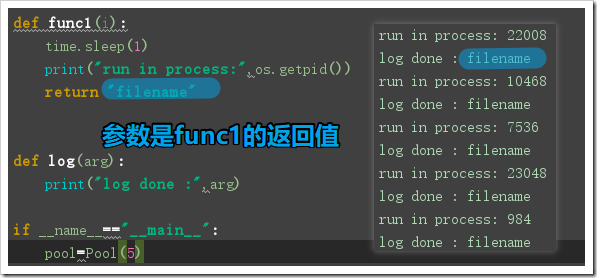
- 回调函数的使用:在并行中,支持callback=回调函数,当一个进程执行完毕后会调用该回调函数,并且参数为func中的返回值
- 注意:回调函数是在父进程中执行的!【当儿子执行完后,会在父亲里调用函数】
from multiprocessing import Pool
import time,os
def func1(i):
time.sleep(1)
print("run in process:",os.getpid())
return "filename"
def log(arg):##参数为进程创建中func的函数的返回值
print("log done :",arg)
if __name__=="__main__":
pool=Pool(5)
start_time = time.time()
for i in range(10):
pool.apply_async(func=func1,args=(i,),callback=log,)#log的参数是func1的返回值
pool.close()#先close再等待
pool.join()
print("main run done,spend_time:",time.time()-start_time)
- 注:对
Pool对象调用join()方法会等待所有子进程执行完毕,调用join()之前必须先调用close(),调用close()之后就不能继续添加新的Process了。【意思就是比如游泳池只卖1个小时的票,约定5点关门,那么4点多之后就不能再卖票了,就一直等着游泳池里面的人出来再关门,进程池的close是一个关门的意思,并不是结束的意思,它只是关上了进来的门,而里面的进程还可以运行】【进程池的join是等池子里的所有进程执行完毕,如果后面再进来进程的话就没完没了了,所以需要先关闭进入,再等待进程结束】
- 小测试:

- 小测试:
更多关于Python相关内容感兴趣的读者可查看本站专题:《Python进程与线程操作技巧总结》、《Python数据结构与算法教程》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》、《Python入门与进阶经典教程》、《Python+MySQL数据库程序设计入门教程》及《Python常见数据库操作技巧汇总》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-

简单学习Python多进程Multiprocessing
1.1 什么是 Multiprocessing 多线程在同一时间只能处理一个任务. 可把任务平均分配给每个核,而每个核具有自己的运算空间. 1.2 添加进程 Process 与线程类似,如下所示,但是该程序直接运行无结果,因为IDLE不支持多进程,在命令行终端运行才有结果显示 import multiprocessing as mp def job(a,b): print('abc') if __name__=='__main__': p1=mp.Process(target=job,args=
-
Python多进程池 multiprocessing Pool用法示例
本文实例讲述了Python多进程池 multiprocessing Pool用法.分享给大家供大家参考,具体如下: 1. 背景 由于需要写python程序, 定时.大量发送htttp请求,并对结果进行处理. 参考其他代码有进程池,记录一下. 2. 多进程 vs 多线程 c++程序中,单个模块通常是单进程,会启动几十.上百个线程,充分发挥机器性能.(目前c++11有了std::thread编程多线程很方便,可以参考我之前的博客) shell脚本中,都是多进程后台执行.({ ...} &, 可以参考
-
Python多进程库multiprocessing中进程池Pool类的使用详解
问题起因 最近要将一个文本分割成好几个topic,每个topic设计一个regressor,各regressor是相互独立的,最后汇总所有topic的regressor得到总得预测结果.没错!类似bagging ensemble!只是我没有抽样.文本不大,大概3000行,topic个数为8,于是我写了一个串行的程序,一个topic算完之后再算另一个topic.可是我在每个topic中用了GridSearchCV来调参,又要选特征又要调整regressor的参数,导致参数组合一共有1782种.我真
-
Python标准库之多进程(multiprocessing包)介绍
在初步了解Python多进程之后,我们可以继续探索multiprocessing包中更加高级的工具.这些工具可以让我们更加便利地实现多进程. 进程池 进程池 (Process Pool)可以创建多个进程.这些进程就像是随时待命的士兵,准备执行任务(程序).一个进程池中可以容纳多个待命的士兵. "三个进程的进程池" 比如下面的程序: 复制代码 代码如下: import multiprocessing as mul def f(x): return x**2 pool = mul.
-
Python多进程multiprocessing.Pool类详解
multiprocessing模块 multiprocessing包是Python中的多进程管理包.它与 threading.Thread类似,可以利用multiprocessing.Process对象来创建一个进程.该进程可以允许放在Python程序内部编写的函数中.该Process对象与Thread对象的用法相同,拥有is_alive().join([timeout]).run().start().terminate()等方法.属性有:authkey.daemon(要通过start()设置)
-
Python多进程multiprocessing用法实例分析
本文实例讲述了Python多进程multiprocessing用法.分享给大家供大家参考,具体如下: mutilprocess简介 像线程一样管理进程,这个是mutilprocess的核心,他与threading很是相像,对多核CPU的利用率会比threading好的多. 简单的创建进程: import multiprocessing def worker(num): """thread worker function""" print 'Wor
-
Python3多进程 multiprocessing 模块实例详解
本文实例讲述了Python3多进程 multiprocessing 模块.分享给大家供大家参考,具体如下: 多进程 Multiprocessing 模块 multiprocessing 模块官方说明文档 Process 类 Process 类用来描述一个进程对象.创建子进程的时候,只需要传入一个执行函数和函数的参数即可完成 Process 示例的创建. star() 方法启动进程, join() 方法实现进程间的同步,等待所有进程退出. close() 用来阻止多余的进程涌入进程池 Pool 造
-
详解python之多进程和进程池(Processing库)
环境:win7+python2.7 一直想学习多进程或多线程,但之前只是单纯看一点基础知识还有简单的介绍,无法理解怎么去应用,直到前段时间看了github的一个爬虫项目涉及到多进程,多线程相关内容,一边看一边百度相关知识点,现在把一些相关知识点和一些应用写下来做个记录. 首先说下什么是进程:进程是程序在计算机上的一次执行活动,当运行一个程序的时候,就启动了一个进程.而进程又分为系统进程和用户进程.只要是用于完成操作系统的各种功能的进程就是系统进程,它们就是处于运行状态下的操作系统本身;而所有由你
-
python multiprocessing多进程变量共享与加锁的实现
python多进程和多线程是大家会重点了解的部分,因为很多工作如果并没有前后相互依赖关系的话其实顺序并不是非常的重要,采用顺序执行的话就必定会造成无谓的等待,任凭cpu和内存白白浪费,这是我们不想看到的. 为了解决这个问题,我们就可以采用多线程或者多进程的方式,(多线程我们之后再讲),而这两者之间是有本质区别的.就内存而言,已知进程是在执行过程中有独立的内存单元的,而多个线程是共享内存的,这是多进程和多线程的一大区别. 利用Value在不同进程中同步变量 在多进程中,由于进程之间内存相互是隔离的
-
Python multiprocessing多进程原理与应用示例
本文实例讲述了Python multiprocessing多进程原理与应用.分享给大家供大家参考,具体如下: multiprocessing包是Python中的多进程管理包,可以利用multiprocessing.Process对象来创建进程,Process对象拥有is_alive().join([timeout]).run().start().terminate()等方法. multprocessing模块的核心就是使管理进程像管理线程一样方便,每个进程有自己独立的GIL,所以不存在进程间争抢
-
python基于multiprocessing的多进程创建方法
本文实例讲述了python基于multiprocessing的多进程创建方法.分享给大家供大家参考.具体如下: import multiprocessing import time def clock(interval): while True: print ("the time is %s"% time.time()) time.sleep(interval) if __name__=="__main__": p = multiprocessing.Process
-
Python多进程并发(multiprocessing)用法实例详解
本文实例讲述了Python多进程并发(multiprocessing)用法.分享给大家供大家参考.具体分析如下: 由于Python设计的限制(我说的是咱们常用的CPython).最多只能用满1个CPU核心. Python提供了非常好用的多进程包multiprocessing,你只需要定义一个函数,Python会替你完成其他所有事情.借助这个包,可以轻松完成从单进程到并发执行的转换. 1.新建单一进程 如果我们新建少量进程,可以如下: import multiprocessing import t