python 如何对Series中的每一个数据做运算
问题描述
最近~ 发现对series里的元素操作挺复杂的,用for loop + Series.iloc[i]会发生卡死的状况,那么,lambda是解决办法:
error 1
ratings['timestamp'] = ratings['timestamp'].apply(ratings['timestamp'].iloc[i].strftime("%Y-%m-%d %H:%M:%S", ts) for i in range(len(ratings)))
TypeError: 'generator' object is not callable
用lambda直接apply,就相当于对每一行的每个元素,逐一apply:
ratings_sub['timestamp'] = ratings_sub['timestamp'].apply(lambda x:time.strftime('%Y/%m/%d',time.localtime(x)))
补充:DataFrame与Series数值的运算
原则一:
运算结果返回全部出现的索引
原则二:
相同索引相加
原则三:
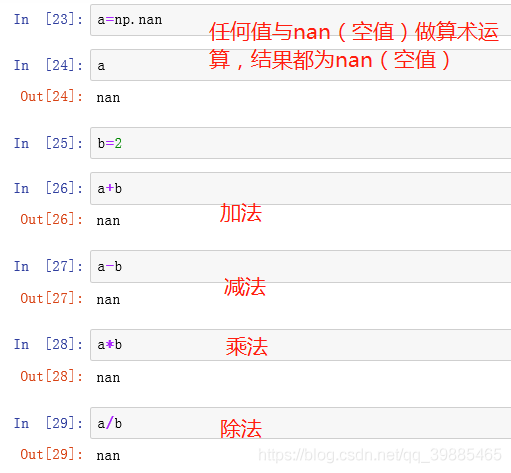
任何值与nan做算术运算 结果为nan
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
浅谈python的dataframe与series的创建方法
如下所示: # -*- coding: utf-8 -*- import numpy as np import pandas as pd def main(): s = pd.Series([i*2 for i in range(1,11)]) print type(s) print (s) dates = pd.date_range("20170301",periods=8) df = pd.DataFrame(np.random.randn(8,5),index=dates,col
-

python-pandas创建Series数据类型的操作
1.什么是pandas 2.查看pandas版本信息 print(pd.__version__) 输出: 0.24.1 3.常见数据类型 常见的数据类型: - 一维: Series - 二维: DataFrame - 三维: Panel - - 四维: Panel4D - - N维: PanelND - 4.pandas创建Series数据类型对象 1). 通过列表创建Series对象 array = ["粉条", "粉丝", "粉带"] # 如
-
在python中pandas的series合并方法
如下所示: In [3]: import pandas as pd In [4]: a = pd.Series([1,2,3]) In [5]: b = pd.Series([2,3,4]) In [6]: c = pd.DataFrame([a,b]) In [7]: c Out[7]: 0 1 2 0 1 2 3 1 2 3 4 不过pandas直接用列表生成dataframe只能按行生成,如果是字典可以按列生成,比如: In [8]: c = pd.DataFrame({'a':a,'b'
-
python pandas中对Series数据进行轴向连接的实例
有时候我们想要的数据合并结果是数据的轴向连接,在pandas中这可以通过concat来实现.操作的对象通常是Series. Ipython中的交互代码如下: In [17]: from pandas import Series,DataFrame In [18]: series1 = Series(range(2),index = ['a','b']) In [19]: series2 = Series(range(3),index = ['c','d','e']) In [20]: serie
-
Python3.5 Pandas模块之Series用法实例分析
本文实例讲述了Python3.5 Pandas模块之Series用法.分享给大家供大家参考,具体如下: 1.Pandas模块引入与基本数据结构 2.Series的创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu #模块引入 import numpy as np import pandas as pd from pandas import Series,DataFrame #1.Series通过numpy一
-
Python Series从0开始索引的方法
如下所示: b.reset_index(drop=True) reset_index代表重新设置索引,drop=True为删除原索引. 以上这篇Python Series从0开始索引的方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
python pandas 对series和dataframe的重置索引reindex方法
reindex更多的不是修改pandas对象的索引,而只是修改索引的顺序,如果修改的索引不存在就会使用默认的None代替此行.且不会修改原数组,要修改需要使用赋值语句. series.reindex() import pandas as pd import numpy as np obj = pd.Series(range(4), index=['d', 'b', 'a', 'c']) print obj d 0 b 1 a 2 c 3 dtype: int64 print obj.reinde
-
python 遍历pd.Series的index和value
遍历pd.Series的index和value的方法如下,python built-in list的enumerate方法不管用 for i, v in s.items(): print('index: ', i, 'value: ', v) #index: a value: 1 #index: b value: 2 #index: c value: 3 #index: d value: 4 for i, v in s.iteritems(): print('index: ', i, 'valu
-
python 如何对Series中的每一个数据做运算
问题描述 最近- 发现对series里的元素操作挺复杂的,用for loop + Series.iloc[i]会发生卡死的状况,那么,lambda是解决办法: error 1 ratings['timestamp'] = ratings['timestamp'].apply(ratings['timestamp'].iloc[i].strftime("%Y-%m-%d %H:%M:%S", ts) for i in range(len(ratings))) TypeError: 'ge
-
Python批量删除mysql中千万级大量数据的脚本分享
场景描述 线上mysql数据库里面有张表保存有每天的统计结果,每天有1千多万条,这是我们意想不到的,统计结果咋有这么多.运维找过来,磁盘占了200G,最后问了运营,可以只保留最近3天的,前面的数据,只能删了.删,怎么删? 因为这是线上数据库,里面存放有很多其它数据表,如果直接删除这张表的数据,肯定不行,可能会对其它表有影响.尝试每次只删除一天的数据,还是卡顿的厉害,没办法,写个Python脚本批量删除吧. 具体思路是: 每次只删除一天的数据: 删除一天的数据,每次删除50000条: 一天的数据删
-
在Python的Django框架中获取单个对象数据的简单方法
相对列表来说,有些时候我们更需要获取单个的对象, `` get()`` 方法就是在此时使用的: >>> Publisher.objects.get(name="Apress") <Publisher: Apress> 这样,就返回了单个对象,而不是列表(更准确的说,QuerySet). 所以,如果结果是多个对象,会导致抛出异常: >>> Publisher.objects.get(country="U.S.A.") T
-
使用python采集Excel表中某一格数据
安装并导入模块 打开命令行窗口,输入: pip install -i https://mirrors.aliyun.com/pypi/simple/ openpyxl 导入: from openpyxl import load_workbook 打开表格有两种方式: 1.sheet = workbook.active 打开活跃的/唯一的表格 2.sheet = workbook['sheet1'] 打开表格sheet1 选择某一格也有两种方式: 1.cell = sheet['A1'] 获取A1
-
在sql中对两列数据进行运算作为新的列操作
如下所示: select a1,a2,a1+a2 a,a1*a2 b,a1*1.0/a2 c from bb_sb 把a表的a1,a2列相加作为新列a,把a1,a2相乘作为新列b,注意: 相除的时候得进行类型转换处理,否则结果为0. select a.a1,b.b1,a.a1+b.b1 a from bb_sb a ,bb_cywzbrzb b 这是两个不同表之间的列进行运算. 补充知识:Sql语句实现不同记录同一属性列的差值计算 所使用的表的具体结构如下图所示 Table中主键是(plateN
-
详解Python数据结构与算法中的顺序表
目录 0. 学习目标 1. 线性表的顺序存储结构 1.1 顺序表基本概念 1.2 顺序表的优缺点 1.3 动态顺序表 2. 顺序表的实现 2.1 顺序表的初始化 2.2 获取顺序表长度 2.3 读取指定位置元素 2.4 查找指定元素 2.5 在指定位置插入新元素 2.6 删除指定位置元素 2.7 其它一些有用的操作 3. 顺序表应用 3.1 顺序表应用示例 3.2 利用顺序表基本操作实现复杂操作 0. 学习目标 线性表在计算机中的表示可以采用多种方法,采用不同存储方法的线性表也有着不同的名称和特
-
Python实现将目录中TXT合并成一个大TXT文件的方法
本文实例讲述了Python实现将目录中TXT合并成一个大TXT文件的方法.分享给大家供大家参考.具体如下: 在网上下了一个dota的英雄攻略,TXT格式,每个英雄一个文件,看得疼,就写了一个小东西,合并一下. #coding=gbk import os import sys import glob def dirTxtToLargeTxt(dir,outputFileName): '''从dir目录下读入所有的TXT文件,将它们写到outputFileName里去''' #如果dir不是目录返回
-
Python 实现在文件中的每一行添加一个逗号
步骤1:读取每行(每行的类型是str) 步骤2:对每行列表化 步骤3:弹出每行的/n两个字符 步骤4:追加,/n三个字符 代码实现如下: #import os From_file=open('D:\\python\\A\\tianqi.txt') f=open('niuniu1.txt','w') count=0 huancun=[] for each_line in From_file: #print(type(each_line)) each_line 是字符类型 Delstr=list(e
-
在Python中分别打印列表中的每一个元素方法
Python版本 3.0以上 分别打印列表中的元素有两种: 方法一 a = [1,2,3,4] print(*a,sep = '\n') #结果 1 2 3 4 方法二 a = [1,2,3,4] [print(i) for i in a] #结果 1 2 3 4 [None, None, None, None] 以上这篇在Python中分别打印列表中的每一个元素方法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-
Python 从一个文件中调用另一个文件的类方法
如果是在同一个 module中(也就是同一个py文件里),直接用就可以 如果在不同的module里,例如 a.py里有 class A: b.py 里有 class B: 如果你要在class B里用class A 需要在 b.py的开头写上 from a import A 举个例子: 比如我在文件lingkingtables.py的文件中构造了三个类,在另一个文件中想要引用这三个类,那么用如下语句即可 from lingkingtables import Lnode from lingking