Redis高级数据类型Hyperloglog、Bitmap的使用
前言
很多小伙伴在面试中都会被问道 Redis的常用数据结构有哪些?
可能很大一部分回答都是 string、hash、list、set、zset。当然啦,这个答案肯定是没有错的,但是相信这个答案,面试官已经听的耳朵都起茧了。
本身我们选择的这个行业竞争就极强,学历拼不过难道还要知识都拼不过吗???
希望进来的小伙伴能好好看完这篇文章,也希望你以后的回答能是 常用的数据结构有string、hash、list、set、zset,但我平时可能还会用到 Hyperloglog和Bitmap。相信面试官听到你的回答,会有眼前一亮的感觉!
话不多说,开始吧,⬇
Hyperloglog
Hyperloglog简介
HyperLogLog是一种概率数据结构,用来估算数据的基数。
基数:可简单理解为集合中不同元素的个数,也可以理解为Set
对于一个集合 1、2、3、4,那么它的基数为 4
对于一个集合 1、2、3、4、1,那么它的基数也是 4
Hyperloglog作用
我们可以使用它来统计 UV。
UV即:UniqueVisitor,UV指的是独立访客的数量,一台电脑被视为一个独立访客。一台电脑早上访问了一次,下午又访问了一次,两次访问的都是同一个网站,只能被计算一次。
那可能有小伙伴问了,及刚才都说了可以理解为一个Set,那我为什么要用它来统计UV?
Redis 的 HyperLogLog 通过牺牲准确率来减少内存空间的消耗,只需要12K内存,在标准误差0.81%的前提下,能够统计2^64个数据。而Set就需要消耗大量空间
所以 HyperLogLog 是否适合在比如统计区间活跃度这样对精度要求不高的场景。
为什么能这么存储,主要依赖于伯努利试验,各位小伙伴可以去百度了解了解。
命令行中的使用
- pfadd <key> [element]:添加数据
- pfcount <key>:统计数量
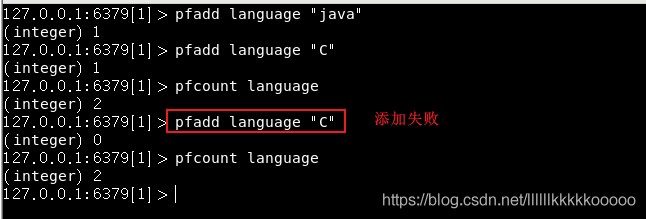

SpringBoot中的使用
@Test
public void testHyperloglog() {
String key = "language";
for (int i = 1; i <= 10000; i++) {
redisTemplate.opsForHyperLogLog().add(key,i);
}
for (int i = 5000; i <= 15000; i++) {
redisTemplate.opsForHyperLogLog().add(key,i);
}
for (int i = 10000; i <= 20000; i++) {
redisTemplate.opsForHyperLogLog().add(key,i);
}
long size = redisTemplate.opsForHyperLogLog().size(key);
System.out.println(size);
}

可以看到结果值为:19891与真实值:20000相差不了多少,虽说有误差,但相比于set已经是很好了!
除此之外,在SpringBoot中还可以对多个key进行合并,统计合并之后的数据量
@Test
public void testHyperloglog() {
String key1 = "language1";
String key2 = "language2";
String key3 = "language3";
String unionKey = "language";
for (int i = 1; i <= 10000; i++) {
redisTemplate.opsForHyperLogLog().add(key1,i);
}
for (int i = 5000; i <= 15000; i++) {
redisTemplate.opsForHyperLogLog().add(key2,i);
}
for (int i = 10000; i <= 20000; i++) {
redisTemplate.opsForHyperLogLog().add(key3,i);
}
redisTemplate.opsForHyperLogLog().union(unionKey,key1,key2,key3);
long size = redisTemplate.opsForHyperLogLog().size(unionKey);
System.out.println(size);
}

可见,数据还是19891
Bitmap
Bitmap简介
位图不是特殊的数据结构,它其实就是普通的字符串,也就是 byte 数组(有了解布隆过滤器的小伙伴可展开联想一下)
通过一个bit位来表示某个元素对应的值或者状态,其中的key就是对应元素本身。
位操作分为两组:
- 固定时间的单个位操作(如将一个位设置为1或0或获取其值)
- 对位组的操作,例如计算给定位范围内设置的位的数量(例如,人口计数)。
位图的最大优点之一是,在存储信息时,它们通常可以节省大量空间。例如,在以增量用户ID表示不同用户的系统中,仅使用512 MB内存就可以记住40亿用户的一位信息
Bitmap作用
使用场景
- 各种实时分析。
- 存储与对象ID相关联的空间高效但高性能的布尔信息。
我们可以使用它来统计 DAU。
日均活跃用户数量(Daily Active User,DAU)是用于反映网站、互联网应用或网络游戏的运营情况的统计指标。日活跃用户数量通常统计一日(统计日)之内,登录或使用了某个产品的用户数(去除重复登录的用户)。
命令行使用Bitmap
使用 setbit 和 getbit 命令设置和检索位:
- setbit命令将位号作为其第一个参数,将其设置为1或0的值作为其第二个参数。如果所寻址的位超出当前字符串长度,则该命令将自动放大字符串。
- getbit 只是返回指定索引处的位的值。超出范围的位(寻址超出存储在目标键中的字符串长度的位)始终被视为零。

在位组上还有以下三个命令:
- bitop 在不同的字符串之间执行按位运算。提供的运算为AND,OR,XOR和NOT。
- bitcount 执行填充计数,报告设置为1的位数。
- bitpos 查找具有指定值0或1的第一位。

SpringBoot使用Bitmap
@Test
public void testBitmap() {
String key = "bitmap";
redisTemplate.opsForValue().setBit(key,1,true);
redisTemplate.opsForValue().setBit(key,4,true);
redisTemplate.opsForValue().setBit(key,2,true);
redisTemplate.opsForValue().setBit(key,5,true);
System.out.println(redisTemplate.opsForValue().getBit(key,2));
System.out.println(redisTemplate.opsForValue().getBit(key,3));
System.out.println(redisTemplate.opsForValue().getBit(key,5));
}

尾言
到此这篇关于Redis高级数据类型Hyperloglog、Bitmap的使用的文章就介绍到这了,更多相关Redis Hyperloglog、Bitmap内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Redis中3种特殊的数据类型(BitMap、Geo和HyperLogLog)
前言 Reids 在 Web 应用的开发中使用非常广泛,几乎所有的后端技术都会有涉及到 Redis 的使用.Redis 种除了常见的字符串 String.字典 Hash.列表 List.集合 Set.有序集合 SortedSet 等等之外,还有一些不常用的数据类型,这里着重介绍三个.下面话不多说了,来一起看看详细的介绍吧. BitMap BitMap 就是通过一个 bit 位来表示某个元素对应的值或者状态, 其中的 key 就是对应元素本身,实际上底层也是通过对字符串的操作来实现.Redis 从
-

Redis高级数据类型Hyperloglog、Bitmap的使用
前言 很多小伙伴在面试中都会被问道 Redis的常用数据结构有哪些? 可能很大一部分回答都是 string.hash.list.set.zset.当然啦,这个答案肯定是没有错的,但是相信这个答案,面试官已经听的耳朵都起茧了. 本身我们选择的这个行业竞争就极强,学历拼不过难道还要知识都拼不过吗??? 希望进来的小伙伴能好好看完这篇文章,也希望你以后的回答能是 常用的数据结构有string.hash.list.set.zset,但我平时可能还会用到 Hyperloglog和Bitmap.相信面试官听
-
Redis特殊数据类型HyperLogLog基数统计算法讲解
目录 Redis HyperLogLog基数统计 一.pfadd 二.pfcount 三.pfmerge Redis HyperLogLog基数统计 HyperLogLog 是用来做基数统计的算法. 先了解下什么是基数. 比如数据集{1, 3, 5, 7, 5, 7, 8},那么这个数据集的基数集为{1, 3, 5 ,7, 8},基数(不重复元素)为5. 如果,现在需要统计一下网页的UV,那么就会涉及到去重了,这种场景就很适合用HyperLogLog. 这不就是set集合嘛?我用set来得出不重
-
Redis特殊数据类型bitmap位图
目录 Redis数据类型bitmap位图 一.setbit 二.getbit 三.bitcount Redis数据类型bitmap位图 bitmap数据结构,是基于二进制位来进行操作记录的,只有0 和 1两个状态.可以想象成一个数组,里面只有0或者1. 能干嘛呢? 现实中会有这些场景,比如统计用户信息,活跃用户和非活跃用户.登录的.未登录的用户,打卡的.未打卡的,像这种只有2个状态,并且数据量非常大的,就适合使用bitmap. 网上找了一个对比,可以帮助记忆下bitmap的优点. 一.setbi
-
聊一聊redis奇葩数据类型与集群知识
目录 多样的数据类型 搞懂集群 复制过程的细节 需要一个管理者 更强的横向伸缩性 总结 多样的数据类型 string 类型简单方便,支持空间预分配,也就是每次会多分配点空间,这样 string 如果下次变长的话,就不需要额外的申请空了,当然前提是剩余的空间够用. List 类型可以实现简单的消息队列,但是注意可能存在消息丢失哦,它并不持 ACK 模式. Hash 表有点像关系型数据库,但是当 hash 表越来越大的时候,请注意,避免使用 hgetall 之类的语句,因为请求大量的数据会导致red
-
Redis高级玩法之利用SortedSet实现多维度排序的方法
说明:本次实践基于Redis版本3.2.11. 关于SortedSet 首先,我们都知道Redis的SortedSet是可以根据score进行排序的,以手机应用商店的热门榜单排序为例,根据下载量倒序排列,其简单用法如下: 127.0.0.1:6379> zadd TopApp 12000000 wechat (integer) 1 127.0.0.1:6379> zadd TopApp 8000000 taobao 10000000 alipay (integer) 2 127.0.0.1:6
-
redis中数据类型命令整理
redis是键值对的数据库,有5中主要数据类型: 字符串类型(string),散列类型(hash),列表类型(list),集合类型(set),有序集合类型(zset) 几个基本的命令: 函数 说明 keys * 获得当前数据库的所有键 exists key [key ...] 判断键是否存在,返回个数,如果key有一样的也是叠加数 del key [key ...] 删除键,返回删除的个数 type key 获取减值的数据类型(string,hash,list,set,zset) flush
-
浅谈Redis存储数据类型及存取值方法
Redis支持五种数据类型:string(字符串),hash(哈希),list(列表),set(集合)及zset(sorted set:有序集合) String存取值: 是 redis 最基本的类型 一个 key 对应一个 value.value其实不仅是String,也可以是数字.string 类型是二进制安全的.意思是 redis 的 string 可以包含任何数据.比如jpg图片或者序列化的对象.string 类型是 Redis 最基本的数据类型,string 类型的值最大能存储 512M
-
python中必会的四大高级数据类型(字符,元组,列表,字典)
一. 字符串 生活中我们经常坐大巴车,每个座位一个编号,一个位置对应一个下标. 字符串中也有下标,要取出字符串中的部分数据,可以用下标取. python中使用切片来截取字符串其中的一段内容,切片截取的内容不包含结束下标对应的数据. 切片使用语法:[起始下标:结束下标:步长] ,步长指的是隔几个下标获取一个字符. 注意:下标会越界,切片不会 常用函数 练习: Test='rodma ' print(type(Test)) print('Test的一个字符串%s'%Test[0])#跟数组差不多 #
-
Redis基本数据类型Zset有序集合常用操作
目录 Redis数据类型Zset有序集合 一.zadd 二.zrange 三.zrevrange 四.zrangebyscore 五. zrem 六.zcard 七.zcount Redis数据类型Zset有序集合 有序集合和集合一样也是 string 类型元素的集合,且不允许重复的成员. 不同的是有序集合每个元素都会关联一个 double 类型的分数.redis 正是通过分数来为集合中的成员进行从小到大的排序. 有序集合的成员是唯一的,但分数(score)却可以重复. 集合是通过哈希表实现的,
-
Redis特殊数据类型Geospatial地理空间
目录 Redis特殊数据类型Geospatial地理空间 一.geoadd 二.geopos 三.geodist 四.georadius 五.georadiusbymember 六.geohash Redis特殊数据类型Geospatial地理空间 这是在redis 3.2版本推出的,推算地理位置的信息,两地之间的距离,周围方圆的人等等场景都可以用它实现. 一.geoadd 将指定的地理空间位置(纬度.经度.名称)添加到指定的key中. 这里可以借助网上的一些查询经纬度的工具来获取数据. geo