Python实战之疫苗研发情况可视化
一、安装plotly库
因为这部分内容主要是用plotly库进行数据动态展示,所以要先安装plotly库
pip install plotly
除此之外,我们对数据的处理还用了numpy和pandas库,如果你没有安装的话,可以用以下命令一行安装
pip install plotly numpy pandas
#导入所需库 import pandas as pd import numpy as np import plotly.express as px import plotly.graph_objects as go
二、疫苗研发情况
各国采用的疫苗品牌概览
通过对各国卫生部门确认备案的疫苗品牌,展示各厂商的疫苗在全球的分布
#读取数据 locations=pd.read_csv(r'data/locations.csv')
locations

这里我们的loacation中可以看到各个地方的疫苗和数据的来源与数据来源的网页
三、数据处理
#发现数据中vaccines列中包含了多个品牌的情况,将这类数拆为多条
vaccines_by_country=pd.DataFrame()
for i in locations.iterrows():
df=pd.DataFrame({'Country':i[1].location,'vaccines':i[1].vaccines.split(',')})
vaccines_by_country=pd.concat([vaccines_by_country,df])
vaccines_by_country['vaccines']=vaccines_by_country.vaccines.str.strip()# 去掉空格
vaccines_by_country.vaccines.unique() # 查看疫苗的种类

四、可视化疫苗的分布情况
#绘图
fig=px.choropleth(vaccines_by_country,
locations='Country',
locationmode='country names',
color='vaccines',
facet_col='vaccines',
facet_col_wrap=3)
fig.update_layout(width=1200, height=1000)
fig.show()
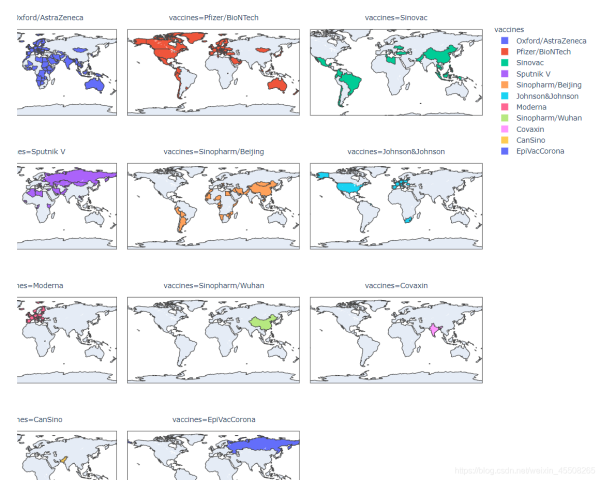
各品牌分布:
- Pfizer/BioNTech 主要分布于北美,南美的智利、厄瓜多尔,欧洲、沙特
- Sputnik V 主要分布于俄罗斯、伊朗、巴基斯坦、非洲的阿尔及利亚以及南美的玻利维亚、阿根廷
- Oxford/AstraZeneca 主要分布于欧洲、南亚、巴西
- Moderna 主要分布在北美和欧洲
- Sinopharm/Beijing 主要分布在中国、北非部分国家和南美的秘鲁
- Sinovac 主要分布在中国、南亚、土耳其和南美
- Sinopharm/Wuhan 主要仅分布于中国
- Covaxin 主要分布于印度
综上可以发现,全球采用最广的仍是Pfizer/BioNTech,国产疫苗中Sinovac(北京科兴疫苗)输出到了较多国家
五、各品牌疫苗上市情况(仅部分国家)
根据数据集中提供的部分国家20年12月以来各品牌疫苗接种情况,分析各品牌上市时间及市场占有情况
#读取数据 vacc_by_manu=pd.read_csv(r'data/vaccinations-by-manufacturer.csv')
#定义函数,用于从原始数据中组织宽表
def query(df,country,date,vaccine):
try:
result=df.loc[(df.location==country)&(df.date==date)&(df.vaccine==vaccine)].total_vaccinations.iloc[0]
except:
result=np.nan
return result
vacc_by_manu

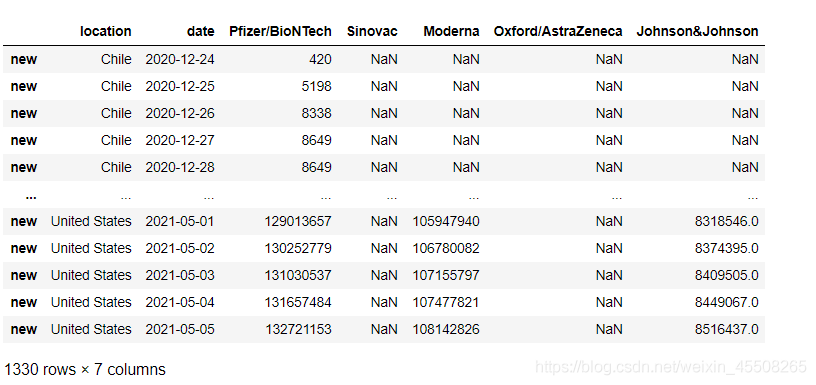
六、组织宽表
#组织宽表
vacc_combined=pd.DataFrame(columns=['location','date','Pfizer/BioNTech', 'Sinovac', 'Moderna', 'Oxford/AstraZeneca'])
for i in vacc_by_manu.location.unique():
for j in vacc_by_manu.date.unique():
for z in vacc_by_manu.vaccine.unique():
result=query(vacc_by_manu,i,j,z)
if vacc_combined.loc[(vacc_combined.location==i)&(vacc_combined.date==j)].empty:
result_df=pd.DataFrame({'location':i,'date':j,z:result},index=['new'])
vacc_combined=pd.concat([vacc_combined,result_df])
else:
vacc_combined.loc[(vacc_combined.location==i)&(vacc_combined.date==j),z]=result
vacc_combined
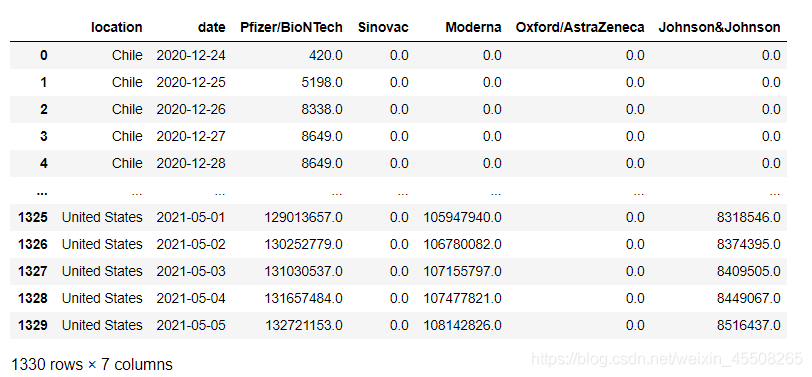
七、补全缺失数据
#补全缺失数据
temp=pd.DataFrame()
for i in vacc_combined.location.unique():#按国家进行不全
r=vacc_combined.loc[vacc_combined.location==i]
r=r.fillna(method='ffill',axis=0)#先按最近一次的数据进行补全
temp=pd.concat([temp,r])#若没有最近的数据,认为该项为0
temp=temp.fillna(0).reset_index(drop=True)
temp
八、绘制堆叠柱状图
#绘制堆叠柱状图
fig=px.bar(temp,
x='location',
y=vacc_by_manu.vaccine.unique(),
animation_frame='date',
color_discrete_sequence=['#636efa','#19d3f3','#ab63fa','#00cc96']#为了查看方便,品牌颜色与前一部分对应
)
fig.show()
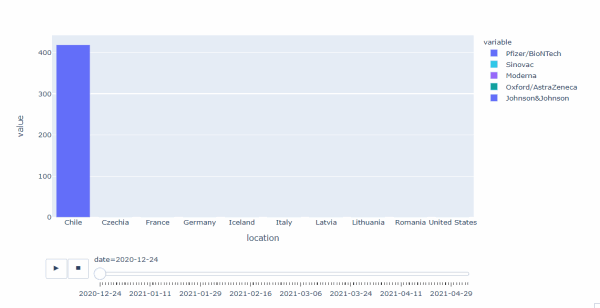
数据中主要涉及Pfizer/BioNTech、Sinovac、Moderna、Oxford/AstraZeneca 4个品牌,其中:
- Pfizer/BioNTech 上市时间最早,20年12月24日时即已经开始在智利接种了,之后在12月底开始在欧洲接种,21年1月12日开始在美国接种
- Sinovac 21年2月2日开始在智利接种Moderna 21年1月8日先在意大利开始接种,随后12日即开始在美国大量接种,最终在欧洲及美国均大量接种
- Oxford/AstraZeneca 21年2月2日先在意大利开始接种,随后即在欧洲开始接种
- 整体上看,Pfizer/BioNTech上市最早,且在全球占有份额最大,Moderna 随后上市,主要占据美国和欧洲市场,Sinovac、Oxford/AstraZeneca上市均较晚,其中Sinovac占据了智利的大部分市场份额,而Oxford/AstraZeneca主要分布于欧洲,且占份额很小
到此这篇关于Python实战之疫苗研发情况可视化的文章就介绍到这了,更多相关Python疫苗研发情况可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python 数据分析实现长宽格式的转换
我就废话不多说了,大家还是直接看代码吧! # encoding=utf-8 import numpy as np import pandas as pd # 长宽格式的转换 # 1 data = pd.read_csv('d:data/macrodata.csv') print 'data:=\n', data print 'data.to_records():=\n', data.to_records() print 'data.year:=\n', data.year print 'data
-
用Python 爬取猫眼电影数据分析《无名之辈》
前言 作者: 罗昭成 PS:如有需要Python学习资料的小伙伴可以加点击下方链接自行获取 http://note.youdao.com/noteshare?id=3054cce4add8a909e784ad934f956cef 获取猫眼接口数据 作为一个长期宅在家的程序员,对各种抓包简直是信手拈来.在 Chrome 中查看原代码的模式,可以很清晰地看到接口,接口地址即为:http://m.maoyan.com/mmdb/comments/movie/1208282.json?_v_=yes&o
-

Python数据分析之彩票的历史数据
一.需求介绍 该需求主要是分析彩票的历史数据 客户的需求是根据彩票的前两期的情况,如果存在某个斜着的两个数字相等,那么就买第三期的同一个位置处的彩票 对于1.,如果相等的数字是:1-5,那就买6-10,如果相等的数字是:6-10,那就买1-5: 对于2.,如果相等的数字是:1-5,那就买1-5,如果相等的数字是:6-10,,那就买6-10. 然后,根据这个方案,有可能会买中,但是也有可能买不中,于是,客户希望我可以统计出来在100天中,按照这种方法,连续6次以及6次以上的购买彩票才能够命中一次奖
-
Python编写可视化界面的全过程(Python+PyCharm+PyQt)
最近开始学习Python,但只限于看理论,编几行代码,觉得没有意思,就想能不能用Python编写可视化的界面.遂查找了相关资料,发现了PyQt,由于前一段时间刚看过Qt,而且对Qt的印象很好,于是觉得用PyQt应该是一个比较愉快的选择. 1.前言 PyQt的版本需要与Python的版本保持一致,在这里我用的PyQT的版本是 PyQt5-5.6-gpl-Py3.5-Qt5.6.0-x64.exe,具体下载方式,请直接搜索.由于该版本需要v3.5版本的Python,所以首先需要安装Python3.5
-
大数据分析用java还是Python
大数据学java还是Python? 大数据开发既要学习Python,也要学习java. 学习大数据开发,java语言是基础,主流的大数据软件基本都是java实现的,所以java是必学的, python也是重要的爬取数据的工具,也是大数据后续提高部分需要学习的. Python简介: python是一种面向对象的,解释型的计算机语言,它的特点是语法简介,优雅,简单易学.1989年诞生,Guido(龟叔)开发. 编译型语言:代码在编译之后,编译成2进制的文件,然后计算机就可用运行了.(C,C++,C#
-
Python Pandas数据分析工具用法实例
1.介绍 Pandas是基于Numpy的专业数据分析工具,可以灵活高效的处理各种数据集,也是我们后期分析案例的神器.它提供了两种类型的数据结构,分别是DataFrame和Series,我们可以简单粗暴的把DataFrame理解为Excel里面的一张表,而Series就是表中的某一列 2.创建DataFrame # -*- encoding=utf-8 -*- import pandas if __name__ == '__main__': pass test_stu = pandas.DataF
-
python用pyecharts实现地图数据可视化
有的时候,我们需要对不同国家或地区的某项指标进行比较,可简单通过直方图加以比较.但直方图在视觉上并不能很好突出地区间的差异,因此考虑地理可视化,通过地图上位置(地理位置)和颜色(颜色深浅代表数值差异)两个元素加以体现.在本文案例中,基于第三方库pyecharts,对中国各省2010-2019年的GDP进行绘制. 我们先来看看最终效果: 关于绘图数据 基于时间和截面两个维度,可把数据分为截面数据.时间序列及面板数据.在本文案例中,某一年各省的GDP属于截面数据,多年各省的GDP属于面板数据.因此,
-
python 可视化库PyG2Plot的使用
G2 是蚂蚁金服开源一个基于图形语法,面向数据分析的统计图表引擎.G2Plot 是在 G2 基础上,屏蔽复杂概念的前提下,保留 G2 强大图形能力,封装出业务上常用的统计图表库. G2Plot 是一个基于配置.体验优雅.面向数据分析的统计图表库,帮助开发者以最小成本绘制高质量统计图表. 那么对于很多 Python 语言环境的同学,如何使用 G2Plot 在进行数据分析之后的可视化呢?也就是 如何将 G2Plot 和 Python 结合起来?这里给出的就是基于 G2Plot 封装出 PyG2Plo
-
Python 数据分析之逐块读取文本的实现
背景 <利用Python进行数据分析>,第 6 章的数据加载操作 read_xxx,有 chunksize 参数可以进行逐块加载. 经测试,它的本质就是将文本分成若干块,每次处理 chunksize 行的数据,最终返回一个TextParser 对象,对该对象进行迭代遍历,可以完成逐块统计的合并处理. 示例代码 文中的示例代码分析如下: from pandas import DataFrame,Series import pandas as pd path='D:/AStudy2018/pyda
-
Python数据分析库pandas高级接口dt的使用详解
Series对象和DataFrame的列数据提供了cat.dt.str三种属性接口(accessors),分别对应分类数据.日期时间数据和字符串数据,通过这几个接口可以快速实现特定的功能,非常快捷. 今天翻阅pandas官方文档总结了以下几个常用的api. 1.dt.date 和 dt.normalize(),他们都返回一个日期的 日期部分,即只包含年月日.但不同的是date返回的Series是object类型的,normalize()返回的Series是datetime64类型的. 这里先简单
-
python爬取各省降水量及可视化详解
在具体数据的选取上,我爬取的是各省份降水量实时数据 话不多说,开始实操 正文 1.爬取数据 使用python爬虫,爬取中国天气网各省份24时整点气象数据 由于降水量为动态数据,以js形式进行存储,故采用selenium方法经xpath爬取数据-ps:在进行数据爬取时,最初使用的方法是漂亮汤法(beautifulsoup)法,但当输出爬取的内容(<class = split>时,却空空如也.在源代码界面Ctrl+Shift+F搜索后也无法找到降水量,后查询得知此为动态数据,无法用该方法进行爬取
-
PyCharm设置Ipython交互环境和宏快捷键进行数据分析图文详解
使用Python进行数据分析,大家都会多少学习一本经典教材<利用Python进行数据分析>,书中作者使用了Ipython的交互环境进行了书中所有代码的案例演示,而书中的Ipython交互环境用的是原生Python开发环境,在原生环境里,由于没有代码提示.自动格式等智能辅助给你,导致编码效率有点低下,之前就有很多人在问,能不能在PyCharm这款目前最流行最智能的python IDE里设置Ipython的交互环境,我自己也做了尝试,经过自己不断摸索和实践,总结出了在PyCharm设置Ipytho
-
Python绘制K线图之可视化神器pyecharts的使用
K线图 概念 股市及期货市bai场中的K线图的du画法包含四个zhi数据,即开盘dao价.最高价.最低价zhuan.收盘价,所有的shuk线都是围绕这四个数据展开,反映大势的状况和价格信息.如果把每日的K线图放在一张纸上,就能得到日K线图,同样也可画出周K线图.月K线图.研究金融的小伙伴肯定比较熟悉这个,那么我们看起来比较复杂的K线图,又是这样画出来的,本文我们将一起探索K线图的魅力与神奇之处吧! K线图 用处 K线图用处于股票分析,作为数据分析,以后的进入大数据肯定是一个趋势和热潮,K线图的专
-
关于Python可视化Dash工具之plotly基本图形示例详解
Plotly Express是对 Plotly.py 的高级封装,内置了大量实用.现代的绘图模板,用户只需调用简单的API函数,即可快速生成漂亮的互动图表,可满足90%以上的应用场景. 本文借助Plotly Express提供的几个样例库进行散点图.折线图.饼图.柱状图.气泡图.桑基图.玫瑰环图.堆积图.二维面积图.甘特图等基本图形的实现. 代码示例 import plotly.express as px df = px.data.iris() #Index(['sepal_length', '
-
python数据分析之员工个人信息可视化
一.实验目的 (1)熟练使用Counter类进行统计 (2)掌握pandas中的cut方法进行分类 (3)掌握matplotlib第三方库,能熟练使用该三方库库绘制图形 二.实验内容 采集到的数据集如下表格所示: 三.实验要求 1.按照性别进行分类,然后分别汇总男生和女生总的收入,并用直方图进行展示. 2.男生和女生各占公司总人数的比例,并用扇形图进行展示. 3.按照年龄进行分类(20-29岁,30-39岁,40-49岁),然后统计出各个年龄段有多少人,并用直方图进行展示. import pan
-
Python实现K-means聚类算法并可视化生成动图步骤详解
K-means算法介绍 简单来说,K-means算法是一种无监督算法,不需要事先对数据集打上标签,即ground-truth,也可以对数据集进行分类,并且可以指定类别数目 牧师-村民模型 K-means 有一个著名的解释:牧师-村民模型: 有四个牧师去郊区布道,一开始牧师们随意选了几个布道点,并且把这几个布道点的情况公告给了郊区所有的村民,于是每个村民到离自己家最近的布道点去听课. 听课之后,大家觉得距离太远了,于是每个牧师统计了一下自己的课上所有的村民的地址,搬到了所有地址的中心地带,并且在海
-
Python绘制词云图之可视化神器pyecharts的方法
自定义图片生成词云图的多种方法 有时候我们会根据具体的场景来结合图片展示词云,比如我分析的是美团评论,那么最好的展示方法就是利用美团的logo来做词云图的底图展示,下面我们就介绍几种常用的方法! 根据喜爱的图片生成词云轮廓 from wordcloud import WordCloud import jieba import matplotlib.pyplot as plt import numpy as np import PIL.Image as Image text = open(u'da