浅谈python数据类型及其操作
一、 Number 数字

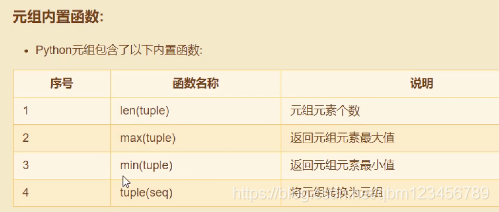
1.内置函数:需要导入math
2.随机数函数:需要导入random 模块
3.三角函数:需要导入math模块
4.数学常量:需要导入math模块
#1.数据函数的使用 #========================== #内置函数 print(abs(-10)) #10绝对值 print(round(4.56789,2)) #4.57 使用四舍五入的方式保留小数点后两位 a = [10,30,20,80,50] print(max(a)) #80 最大值 print(min(a)) #10 最小值 #需要导入math import math print(math.ceil(2.3)) #3 进一取整 print(math.floor(2.99999)) #2 舍去取整
10
4.57
80
10
3
#2.随机数函数 #============================= #需要导入random 模块 import random print(random.random()) #随机一个0~1的小数 print(random.choice(['aaa','bbb','cccc'])) #随机获取一个值 #指定范围的随机 print(random.randrange(10)) #随机0~9的一个值 print(random.randrange(4,10)) #随机4~9的一个值 print(random.randrange(0,10,2)) #随机4~9的一个值 b = [1,2,3,4,5,6] random.shuffle(b) #将容器内的值顺序打乱 print(b)
0.6045140519996484
cccc
3
4
0
[1, 3, 4, 6, 5, 2]
#3.三角函数 #需要导入math模块 print(math.sin(90)) print(math.cos(0))
0.8939966636005579
1.0
#4.数学常量 #需要导入math模块 print(math.pi) #圆周率 print(math.e) #自然常数
3.141592653589793
2.718281828459045
二、String 字符串

# 1.字符流(str 字符串) <=> 字节流(bytes 字符串、二进制)之间的转换 #字符流转换为字节流 str = "zhangsan" b1 = str.encode(encoding="utf-8") print(b1) b2 = bytes(str,encoding="utf+8") #结果中,只要是b开头的都叫字节流 print(b2) #字节流转成字符流 print(b1.decode(encoding="utf-8")) #由字节转成字符 print(bytes.decode(b2,encoding="utf-8"))
b'zhangsan'
b'zhangsan'
zhangsan
zhangsan
#2.转义符的使用
print("ab\\cde\n\rfg\thijk\"lmnopq")
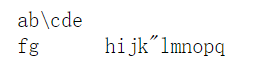
#3. 字符串的格式化:format %
print("a={};b={}".format(10,20)) #用括号作占位符。
print("a={1};b={0}".format(10,20)) # 指定索引号代表第几参数
print("a={0};b={0}".format(10))
print("name={name:10};age={age}".format(age=20,name="lisi")) #name:10 表示占10个宽度。
print("name={name:<10};age={age}".format(age=20,name="lisi")) #小于号:靠左边;大于号:靠右边。
print("{:.2f}".format(5.6789)) # .2f表示保留小数后两位
name="zhangsan"
print(f"name={name}")
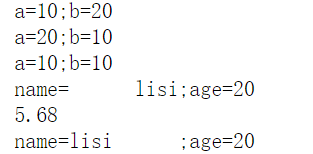
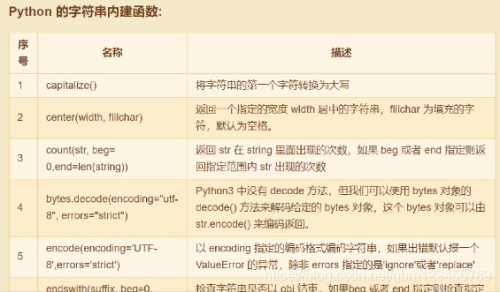
#4.字符串的内建函数
#==============================
name = "ZhangSan"
print(name,name.upper(),name.lower()) #字符串的大小写
print("字符串长度:",len(name))
print("统计字符串中an出现的次数:",name.count('an'))
print("字符串替换: ",name.replace("San","wuji"))
print("10:20:30:40".split(":")) #字符串拆分(列表)

# 字符串查找
str = "zhangsanfang"
print(str.find("an")) #从头开始查找 ,找不到返回-1
print(str.rfind("an")) #从末尾开始查找 ,找不到返回-1
print(str.index("an")) #从头查找,找不到报错
print(" aaa ".strip()) #去除字符串两侧多余空格(或指定字符)
print(" aaa ".lstrip()) #去除字符串左侧多余空格(或指定字符)
print(" aaa ".rstrip()) #去除字符串右侧多余空格(或指定字符)



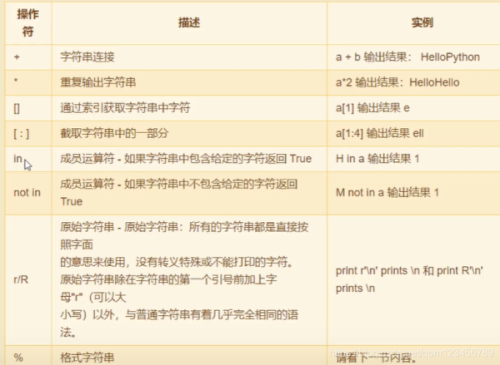

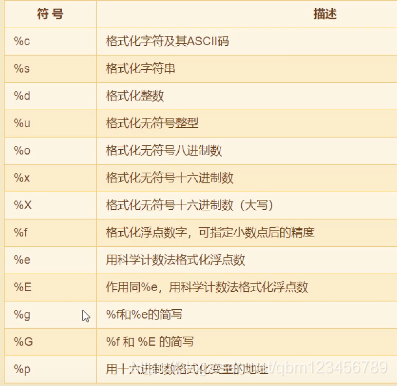
三、List 列表

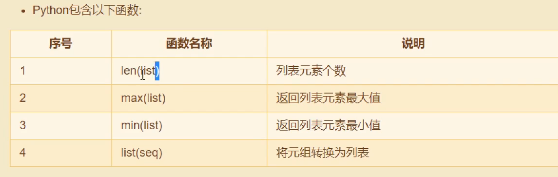
# 1. 列表的定义 list1 = [] #定义一个空列表 list2 = list() #定义一个空列表 list3 = ['python','java','php',10,20] #定义列表 list4 = [1,2,3,4,5,6,7] #定义列表 print(list4) list4[3] = 400 #修改 print(list4) del list4[5] #删除 print(list4)
[1, 2, 3, 4, 5, 6, 7]
[1, 2, 3, 400, 5, 6, 7]
[1, 2, 3, 400, 5, 7]
10 20 30 40 50
10 20 30 40 50
# 2.列表的遍历
a = [10,20,30,40,50]
#使用for ... in 遍历
for i in a:
print(i,end= " ")
print()
#使用while循环遍历
i = 0
while i <len(a):
print(a[i],end= " ")
i += 1
print()
10 20 30 40 50
10 20 30 40 50
#遍历等长的二阶列表
b = [["aa","AAA"],["bb","BBB"],["cc","CCC"]]
for v1,v2 in b:
print(v1,v2)
#遍历不规则二阶列表
c = [[10,20],[30,40,50],[60,70],[80,90,100,110,120]]
for v in c:
for i in v:
print(i,end=" ")
print()

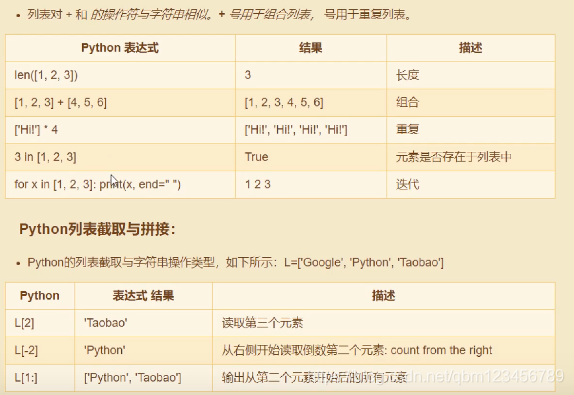
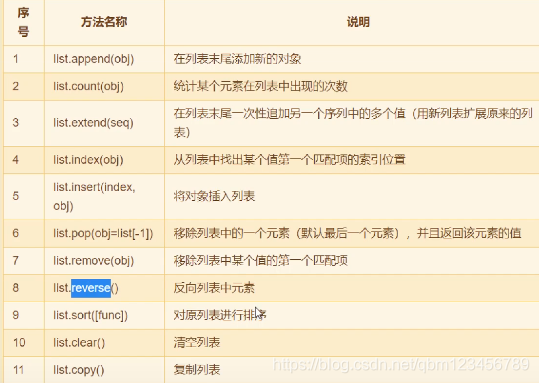
# 4. 列表的方法 (非常重要)
a = ['zhangsan','lisi']
a.append('wangwu') #在列表的尾部新增值
a.extend(['zhaoliu','xiaolin']) #在列表尾部添加多个值
a.insert(3,"qqq") #在指定位置插入一个值
print(a)
b = [1,2,3,3,2,1,4,5]
print(b.count(1)) #统计1在列表中出现的次数
print(b.index(5)) #5出现的位置
print(a.pop()) #最后一个值
a.remove("zhangsan") #删除指定值
print(a)
a.reverse() #颠倒顺序
print(a)
b.sort() #升序
print(b)
b.clear() #清空
print(b)

a = [10,20,30] b = a c = a.copy() #浅复制:复制一个列表 print(id(a),id(b),id(c)) a[1] = 200 print(a) print(b) print(c)
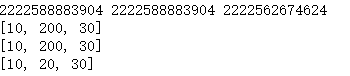
四、Tuple 元组

#========================================
#1. 定义元组的方式
tup0 = () #定义一个空元组 或者变量 = tuple() (没有意义,因为元组不能被修改)
tup1 = ('Google','Python',1997,2000)
tup2 = (1,2,3,4,5)
tup3 = "a","b","c","d"
#输出元组:
print("tup1[0]: ",tup1[0])
print("tup2[1:5]:",tup2[1:5])
#注意下面这种定义下不加逗号,类型为整型
tup4 = (50)
print(type(tup4))
#以下修改元组元素操作是非法的。
#tup1[0] = 100
#元组中的元素值是不允许删除的,但可使用del语句来删除整个元组
del tup0;
tup1[0]: Google
tup2[1:5]: (2, 3, 4, 5)
<class ‘int'>
#2. 元组的遍历
#===========================
a = (10,20,30,40,50)
#使用for ... in 遍历
for i in a:
print(i)
# 使用while遍历
i = 0
while i<len(a):
print(a[i])
i += 1
10
20
30
40
50
10
20
30
40
50
10 20
30 40
50 60
#遍历等长二级元组
b = ((10,20),(30,40),(50,60))
for v1,v2 in b:
print(v1,v2)
#遍历不等长二级元组
b = ((10,20),(30,40,50,60),(70,80,90))
for v in b:
for i in v:
print(i,end=" ")
print()
10 20
30 40
50 60
10 20
30 40 50 60
70 80 90
# 4. 元组的操作符: #==================================== a = (1,2,3) b = (4,5,6,7) print(len(a)) print(a+b) print(a*2) print(6 in b) #判断一个值是否在一个元组中 #获取 print(b[2]) print(b[-2]) print(b[1:]) print(b[1:3])
3
(1, 2, 3, 4, 5, 6, 7)
(1, 2, 3, 1, 2, 3)
True
6
6
(5, 6, 7)
(5, 6)

五、Sets集合

# 1.集合的基础操作
#====================================
#定义集合的方式:
#集合的定义
set1 = set() #定义一个空的集合
set2 = {1,2,3}
#增加一个元素
set1.add(5)
#增加多个:参数可以是列表或元组
set1.update([5,6,7,8])
#删除某个值(参数为元素值,没有会报错)
set2.remove(1)
set2.discard(50) #删除不存在的值不会报错
#查:无法通过下标索引
#改:不可变类型无法修改元素
#清空集合
set2.clear()
a = {10,20,30}
b = {20,50}
print(a - b) #a和b的差集
print(a | b) #a和b的并集
print(a & b) #a和b的交集
print(a ^ b) #a和b中不同时存在的元素
# 2. 集合的遍历
#======================================
a = {10,20,30,40,50}
#使用for ... in 遍历
for i in a:
print(i)
#注:没有while遍历,因为没有排序,
#遍历等长二级集合
b = {(10,20),{30,40},(50,60)}
for v1,v2 in b:
print(v1,v2)

# 4. 集合的操作符
a = {1,2,3}
print(len(a)) #3 集合长度
print(6 in a) #判断一个值是否在一个集合中
3
False

六、Dictionary 字典 (非常重要)

#字典是另一种可变容器模型,且可存储任意类型对象
# 1. 字典的基础操作:
#==============================
#定义字典的方式:
#字典的定义
d0 = {} #或dict() #定义一个空的字典
d1 = {'name':'python','age':17,'class':'first'}
#输出子字典中的信息
print("d1['name']: ",d1['name']) #python
print("d1['age']: ",d1['age']) #17
#输出错误信息:KeyError
# print("d1['alice']:",d1['alice'])
#修改和添加内容
d1['age'] = 18; #key存在则更新age
d1['school'] = '云课堂' # 不存在则添加信息
print(d1)
#删除信息
del d1['name'] #删除键'name'一个元素值
d1.clear() #清空字典
del d1

#2. 字典的遍历
#===================================
d1 = {'name':'python','age':17,'class':'first'}
#使用for...in 遍历(默认遍历键)
for k in d1:
print(k,"=>",d1[k])
#遍历键和值(使用items())
for k,v in d1.items():
print(k,"===>",v)

# 3. 推倒式的使用 #================================ a = [1,2,3,4,5,6,7,8] #遍历列表a中的值i ,并判断是否是偶数,并形成新的列表保留下来 b = [i for i in a if i%2==0] #for i in a ,循环a列表,拿这个列表的值; if i%2==0 这个值若能被2整除,拿出来; 前面的i表示新生成一个列表 print(b)
[2, 4, 6, 8]
stu = {'name':'zhangsan','age':20,'sex':'man'}
#将当前stu字典遍历形成一个新的字典,去掉了age
s1 = {k:v for k,v in stu.items()} #for k ,v in stu.items()遍历字典;k:v形成新的字典;if k != "age" 作判断
s2 = {k:v for k,v in stu.items() if k !="age"} #for k ,v in stu.items()遍历字典;k:v形成新的字典;if k != "age" 作判断
print(s1)
print(s2)

# 字典的操作方法
#=================================
stu = {'name':'zhangsan','age':20,'sex':'man'}
print(stu.items()) #以列表方式返回当前字典的键值对
print(stu.keys())
print(stu.values())
print(stu.get("name")) #
print(stu.get("iphone",None)) #获取指定key的值,若无返回None
print(stu.pop('age')) #弹出指定key的值,表示字典中没有了此内容
print(stu)
print(stu.popitem()) #随机弹出一对信息(移除了),默认最后一个。
print(stu)
stu.clear()

#容器的拷贝(浅拷贝和深度拷贝)
#浅拷贝
a = {"name":"zhanngsan","data":[10,20,30]}
b = a.copy() #浅拷贝
a["name"] = 'lisi'
a["data"][1] = 200
print(a)
print(b)

#导入一个深度拷贝模块
import copy
a = {"name":"zhanngsan","data":[10,20,30]}
b = copy.deepcopy(a) #深度拷贝
a["name"] = 'lisi'
a["data"][1] = 200
print(a)
print(b)
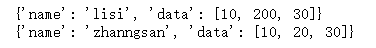

到此这篇关于浅谈python数据类型及其操作的文章就介绍到这了,更多相关python数据类型内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python-pandas创建Series数据类型的操作
1.什么是pandas 2.查看pandas版本信息 print(pd.__version__) 输出: 0.24.1 3.常见数据类型 常见的数据类型: - 一维: Series - 二维: DataFrame - 三维: Panel - - 四维: Panel4D - - N维: PanelND - 4.pandas创建Series数据类型对象 1). 通过列表创建Series对象 array = ["粉条", "粉丝", "粉带"] # 如
-
Python数据类型之Number数字操作实例详解
本文实例讲述了Python数据类型之Number数字操作.分享给大家供大家参考,具体如下: 一.Number(数字) 数据类型 为什么会有不同的数据类型? 计算机是用来做数学计算的机器,因此它可以处理各种数值,但是计算机能够处理的远远不止是数值,它还可以处理文本.图形.音频.视频等各种各样的数据,不同的数据要定义不同的数据类型. python的数据类型分为几种? 1.Number(数字) a.整数 :python可以处理任意大小的整数,当然包括负整数,在程序的表示方法和数学上的写法是一模一样的,
-
python数据类型_元组、字典常用操作方法(介绍)
元组 Python的元组与列表类似,不同之处在于元组的元素不能修改. 元组使用小括号,列表使用方括号. 元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可. tp=(1,2,3,'a','b') a = 'hello world' #这样定义是str类型 b = ('hello world') #定义元组时,如果只有一个元素,那么b的类型就是str c = ('hello world',) print(type(c)) 元组只有count和index方法,如下: tp = ('127.0
-
Python常见数据类型转换操作示例
本文实例讲述了Python常见数据类型转换操作.分享给大家供大家参考,具体如下: 类型转换 主要针对几种存储工具:list.tuple.dict.set 特殊之处:dict是用来存储键值对的. 1.list 转换为set l1 = [1, 2, 4, 5] s1 = set(l1) print(type(s1)) print(s1) 输出: <class 'set'> {1, 2, 4, 5} 2.set转换为list s1 = set([1, 2, 3, 4]) l1 = list(s1)
-
python数据类型_字符串常用操作(详解)
这次主要介绍字符串常用操作方法及例子 1.python字符串 在python中声明一个字符串,通常有三种方法:在它的两边加上单引号.双引号或者三引号,如下: name = 'hello' name1 = "hello bei jing " name2 = '''hello shang hai haha''' python中的字符串一旦声明,是不能进行更改的,如下: #字符串为不可变变量,即不能通过对某一位置重新赋值改变内容 name = 'hello' name[0] = 'k' #通
-
浅谈Python数据类型判断及列表脚本操作
数据类型判断 在python(版本3.0以上)使用变量,并进行值比较时.有时候会出现以下错误: TypeError: unorderable types: NoneType() < int() 或者类似的类型错误. 这是因为一方变量的数据类型不明(python无法判断),所以出错. 在一般情况下,可以提前对要使用的变量进行定义并赋值,例如: var=' ' 或者 var=0 等等. 但是,若变量在比较前,是通过调用函数或者其他表达式赋值的,以上方法可能行不通,因为如果调用的函数如果存在错误或者没
-
Python 分布式缓存之Reids数据类型操作详解
1.Redis API 1.安装redis模块 $ pip3.8 install redis 2.使用redis模块 import redis # 连接redis的ip地址/主机名,port,password=None r = redis.Redis(host="127.0.0.1",port=6379,password="gs123456") 3.redis连接池 redis-py使用connection pool来管理对一个redis server的所有连接,避
-
Python数据类型中的“冒号“[::]——分片与步长操作示例
本文实例讲述了Python数据类型中的"冒号"[::]--分片与步长操作.分享给大家供大家参考,具体如下: 例如有如下字符串: string = "welcome to jb51^_^" 可以使用分片符和步长符:来给字符串进行分片和定义步长 string = "welcome to jb51^_^" #默认返回全部 print string[:] #返回1到9结果 print string[1:9] #返回1到9结果,步长为1 print str
-
python内置数据类型之列表操作
数据类型是一种值的集合以及定义在这种值上的一组操作.一切语言的基础都是数据结构,所以打好基础对于后面的学习会有百利而无一害的作用. python内置的常用数据类型有:数字.字符串.Bytes.列表.元组.字典.集合.布尔等 1.什么是列表 lst[#] 通过下标访问,从0开始. ps:如果#超过下标的范围时候会出现IndexError的错误. 如果#为负号,则索引从右边开始,#无论为正负均有范围,超过范围会报错. lst = list(range(0,9)) #生产列表 l1 = lst[3]
-
浅谈python数据类型及其操作
一. Number 数字 1.内置函数:需要导入math 2.随机数函数:需要导入random 模块 3.三角函数:需要导入math模块 4.数学常量:需要导入math模块 #1.数据函数的使用 #========================== #内置函数 print(abs(-10)) #10绝对值 print(round(4.56789,2)) #4.57 使用四舍五入的方式保留小数点后两位 a = [10,30,20,80,50] print(max(a)) #80 最大值 prin
-
浅谈Python数据类型之间的转换
Python数据类型之间的转换 函数 描述 int(x [,base]) 将x转换为一个整数 long(x [,base] ) 将x转换为一个长整数 float(x) 将x转换到一个浮点数 complex(real [,imag]) 创建一个复数 str(x) 将对象 x 转换为字符串 repr(x) 将对象 x 转换为表达式字符串 eval(str) 用来计算在字符串中的有效Python表达式,并返回一个对象 tuple(s) 将序列 s 转换为一个元组 list(s) 将序列 s 转换为一个
-
浅谈python数据类型及类型转换
Python中核心的数据类型有哪些? 变量(数字.字符串.元组.列表.字典) 什么是数据的不可变性?哪些数据类型具有不可变性 数据的不可变是指数据不可更改,比如: a = ("abc",123) #定义元组 a[0]=234 #把第一位更改为345 print(a) #打印时会报错 不可变:数字.字符.元组 可变:列表和字典 Python中常见数据类型 赋值 counter = 100 miles = 1000 name = "nan" print(counter,
-
浅谈python opencv对图像颜色通道进行加减操作溢出
由于opencv读入图片数据类型是uint8类型,直接加减会导致数据溢出现象 (1)用Numpy操作 可以先将图片数据类型转换成int类型进行计算, data=np.array(image,dtype='int') 经过处理后(如:遍历,将大于255的置为255,小于0的置为0) 再将图片还原成uint8类型 data=np.array(image,dtype='uint8') 注意: (1)如果直接相加,那么 当像素值 > 255时,结果为对256取模的结果,例如:(240+66) % 256
-
浅谈python中列表、字符串、字典的常用操作
列表操作如此下: a = ["haha","xixi","baba"] 增:a.append[gg] a.insert[1,gg] 在下标为1的地方,新增 gg 删:a.remove(haha) 删除列表中从左往右,第一个匹配到的 haha del a.[0] 删除下标为0 对应的值 a.pop(0) 括号里不写内容,默认删除最后一个,写了,就删除对应下标的内容 改:a.[0] = "gg" 查:a[0] a.index(&q
-
浅谈Python中用datetime包进行对时间的一些操作
1. 计算给出两个时间之间的时间差 import datetime as dt # current time cur_time = dt.datetime.today() # one day pre_time = dt.date(2016, 5, 20) # eg: 2016.5.20 delta = cur_time - pre_time # if you want to get discrepancy in days print delta.days # if you want to get
-
浅谈Python 集合(set)类型的操作——并交差
阅读目录 •介绍 •基本操作 •函数操作 介绍 python的set是一个无序不重复元素集,基本功能包括关系测试和消除重复元素. 集合对象还支持并.交.差.对称差等. sets 支持 x in set. len(set).和 for x in set.作为一个无序的集合,sets不记录元素位置或者插入点.因此,sets不支持 indexing, slicing, 或其它类序列(sequence-like)的操作. 基本操作 >>> x = set("jihite")
-
浅谈Python中os模块及shutil模块的常规操作
如下所示: #os.listdir() 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表.这个列表以字母顺序. 它不包括 '.' 和'..' 即使它在文件夹中. #只支持在 Unix, Windows 下使用 import os, sys # 打开文件 path=r'C:\Users\Administrator.SKY-20180518VHY\Desktop\rx\ore' dirs = os.listdir( path ) print(dirs) # 输出所有文件和文件夹 for fil
-
浅谈Python 命令行参数argparse写入图片路径操作
什么是命令行参数? 命令行参数是在运行时给予程序/脚本的标志.它们包含我们程序的附加信息,以便它可以执行. 并非所有程序都有命令行参数,因为并非所有程序都需要它们. 为什么我们使用命令行参数? 如上所述,命令行参数在运行时为程序提供附加信息. 这允许我们在不改变代码的情况下动态地为我们的程序提供不同的输入 . 您可以绘制命令行参数类似于函数参数的类比.如果你知道如何在各种编程语言中声明和调用函数,那么当你发现如何使用命令行参数时,你会立刻感到宾至如归. 鉴于这是计算机视觉和图像处理博客,您在这里