Python scrapy爬取起点中文网小说榜单
一、项目需求
爬取排行榜小说的作者,书名,分类以及完结或连载
二、项目分析
目标url:“https://www.qidian.com/rank/hotsales?style=1&page=1”
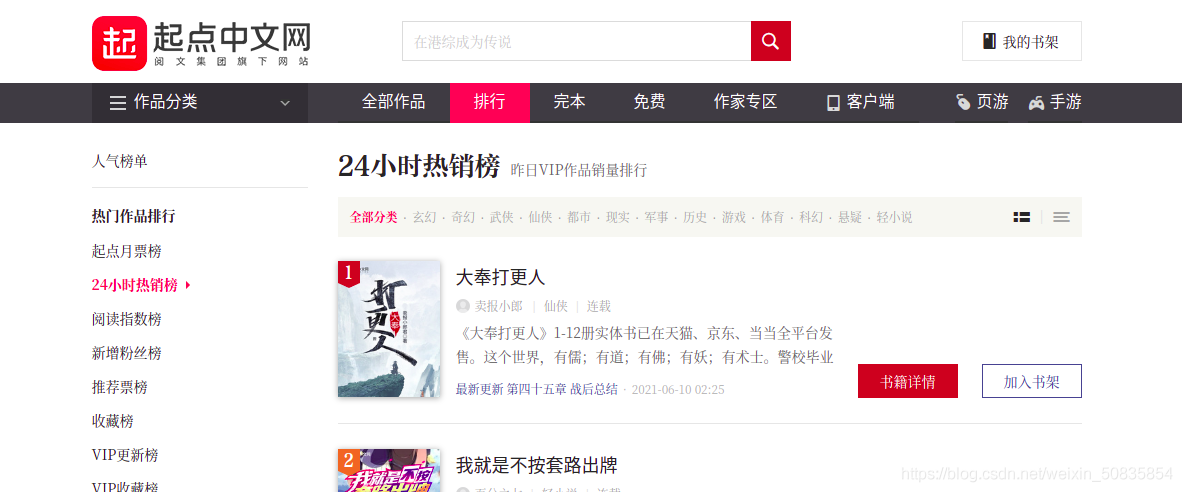
通过控制台搜索发现相应信息均存在于html静态网页中,所以此次爬虫难度较低。

通过控制台观察发现,需要的内容都在一个个li列表中,每一个列表代表一本书的内容。
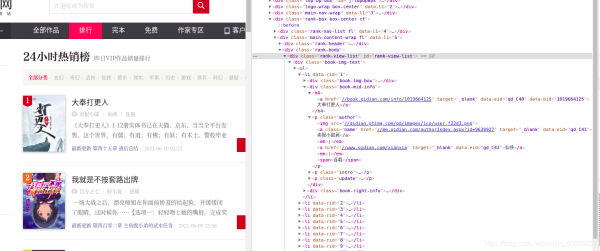
在li中找到所需的内容

找到第两页的url
“https://www.qidian.com/rank/hotsales?style=1&page=1”
“https://www.qidian.com/rank/hotsales?style=1&page=2”
对比找到页数变化
开始编写scrapy程序。
三、程序编写
创建项目太简单,不说了
1.编写item(数据存储)
import scrapy
class QidianHotItem(scrapy.Item):
name = scrapy.Field() #名称
author = scrapy.Field() #作者
type = scrapy.Field() #类型
form= scrapy.Field() #是否完载
2.编写spider(数据抓取(核心代码))
#coding:utf-8
from scrapy import Request
from scrapy.spiders import Spider
from ..items import QidianHotItem
#导入下需要的库
class HotSalesSpider(Spider):#设置spider的类
name = "hot" #爬虫的名称
qidian_header={"user-agent":"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.93 Safari/537.36"} #设置header
current_page = 1 #爬虫起始页
def start_requests(self): #重写第一次请求
url="https://www.qidian.com/rank/hotsales?style=1&page=1"
yield Request(url,headers=self.qidian_header,callback=self.hot_parse)
#Request发起链接请求
#url:目标url
#header:设置头部(模拟浏览器)
#callback:设置页面抓起方式(空默认为parse)
def hot_parse(self, response):#数据解析
#xpath定位
list_selector=response.xpath("//div[@class='book-mid-info']")
#获取所有小说
for one_selector in list_selector:
#获取小说信息
name=one_selector.xpath("h4/a/text()").extract()[0]
#获取作者
author=one_selector.xpath("p[1]/a[1]/text()").extract()[0]
#获取类型
type=one_selector.xpath("p[1]/a[2]/text()").extract()[0]
# 获取形式
form=one_selector.xpath("p[1]/span/text()").extract()[0]
item = QidianHotItem()
#生产存储器,进行信息存储
item['name'] = name
item['author'] = author
item['type'] = type
item['form'] = form
yield item #送出信息
# 获取下一页URL,并生成一个request请求
self.current_page += 1
if self.current_page <= 10:#爬取前10页
next_url = "https://www.qidian.com/rank/hotsales?style=1&page="+str(self.current_page)
yield Request(url=next_url,headers=self.qidian_header,callback=self.hot_parse)
def css_parse(self,response):
#css定位
list_selector = response.css("[class='book-mid-info']")
for one_selector in list_selector:
# 获取小说信息
name = one_selector.css("h4>a::text").extract()[0]
# 获取作者
author = one_selector.css(".author a::text").extract()[0]
# 获取类型
type = one_selector.css(".author a::text").extract()[1]
# 获取形式
form = one_selector.css(".author span::text").extract()[0]
# 定义字典
item=QidianHotItem()
item['name']=name
item['author'] = author
item['type'] = type
item['form'] = form
yield item
3.start.py(代替命令行)
在爬虫项目文件夹下创建start.py。
from scrapy import cmdline
#导入cmd命令窗口
cmdline.execute("scrapy crawl hot -o hot.csv" .split())
#运行爬虫并生产csv文件
出现类似的过程代表爬取成功。
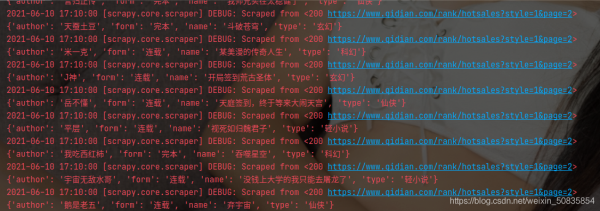
hot.csv
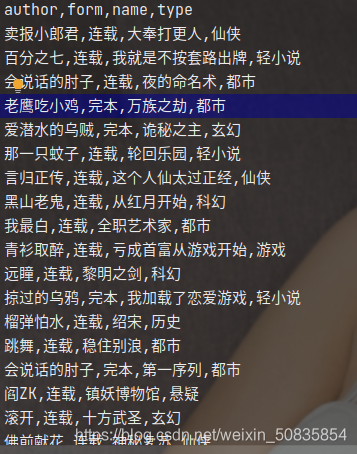
总结
本次爬虫内容还是十分简单的因为只用了spider和item,这几乎是所有scrapy都必须调用的文件,后期还会有middlewarse.py,pipelines.py,setting.py需要编写和配置,以及从javascript和json中提取数据,难度较大。
到此这篇关于Python scrapy爬取起点中文网小说榜单的文章就介绍到这了,更多相关Python爬取起点中文网内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python 爬取小说并下载的示例
代码 import requests import time from tqdm import tqdm from bs4 import BeautifulSoup """ Author: Jack Cui Wechat: https://mp.weixin.qq.com/s/OCWwRVDFNslIuKyiCVUoTA """ def get_content(target): req = requests.get(url = target) r
-
Python爬取365好书中小说代码实例
需要转载的小伙伴转载后请注明转载的地址 需要用到的库 from bs4 import BeautifulSoup import requests import time 365好书链接:http://www.365haoshu.com/ 爬取<我以月夜寄相思>小说 首页进入到目录:http://www.365haoshu.com/Book/Chapter/List.aspx?NovelId=3026 获取小说的每个章节的名称和章节链接 打开浏览器的开发者工具,查找一个章节:如下图,找到第一章的
-
python 爬取国内小说网站
原理先行 作为一个资深的小说爱好者,国内很多小说网站如出一辙,什么
-
Python爬虫入门教程02之笔趣阁小说爬取
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,如有问题请及时联系我们以作处理. 前文 01.python爬虫入门教程01:豆瓣Top电影爬取 基本开发环境 Python 3.6 Pycharm 相关模块的使用 request sparsel 安装Python并添加到环境变量,pip安装需要的相关模块即可. 单章爬取 一.明确需求 爬取小说内容保存到本地 小说名字 小说章节名字 小说内容 # 第一章小说url地址 url = 'http://www.biquges.co
-
python爬虫之爬取笔趣阁小说
前言 为了上班摸鱼方便,今天自己写了个爬取笔趣阁小说的程序.好吧,其实就是找个目的学习python,分享一下. 一.首先导入相关的模块 import os import requests from bs4 import BeautifulSoup 二.向网站发送请求并获取网站数据 网站链接最后的一位数字为一本书的id值,一个数字对应一本小说,我们以id为1的小说为示例. 进入到网站之后,我们发现有一个章节列表,那么我们首先完成对小说列表名称的抓取 # 声明请求头 headers = { 'Use
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
Python实现的爬取小说爬虫功能示例
本文实例讲述了Python实现的爬取小说爬虫功能.分享给大家供大家参考,具体如下: 想把顶点小说网上的一篇持续更新的小说下下来,就写了一个简单的爬虫,可以爬取爬取各个章节的内容,保存到txt文档中,支持持续更新保存.需要配置一些信息,设置文档保存路径,书名等.写着玩,可能不大规范. # coding=utf-8 import requests from lxml import etree from urllib.parse import urljoin import re import os #
-
Python scrapy爬取起点中文网小说榜单
一.项目需求 爬取排行榜小说的作者,书名,分类以及完结或连载 二.项目分析 目标url:"https://www.qidian.com/rank/hotsales?style=1&page=1" 通过控制台搜索发现相应信息均存在于html静态网页中,所以此次爬虫难度较低. 通过控制台观察发现,需要的内容都在一个个li列表中,每一个列表代表一本书的内容. 在li中找到所需的内容 找到第两页的url "https://www.qidian.com/rank/hotsale
-
Python实现爬取逐浪小说的方法
本文实例讲述了Python实现爬取逐浪小说的方法.分享给大家供大家参考.具体分析如下: 本人喜欢在网上看小说,一直使用的是小说下载阅读器,可以自动从网上下载想看的小说到本地,比较方便.最近在学习Python的爬虫,受此启发,突然就想到写一个爬取小说内容的脚本玩玩.于是,通过在逐浪上面分析源代码,找出结构特点之后,写了一个可以爬取逐浪上小说内容的脚本. 具体实现功能如下:输入小说目录页的url之后,脚本会自动分析目录页,提取小说的章节名和章节链接地址.然后再从章节链接地址逐个提取章节内容.现阶段只
-
Python scrapy爬取苏州二手房交易数据
一.项目需求 使用Scrapy爬取链家网中苏州市二手房交易数据并保存于CSV文件中 要求: 房屋面积.总价和单价只需要具体的数字,不需要单位名称. 删除字段不全的房屋数据,如有的房屋朝向会显示"暂无数据",应该剔除. 保存到CSV文件中的数据,字段要按照如下顺序排列:房屋名称,房屋户型,建筑面积,房屋朝向,装修情况,有无电梯,房屋总价,房屋单价,房屋产权. 二.项目分析 流程图 通过控制台发现所有房屋信息都在一个ul中其中每一个li里存储一个房屋的信息. 找了到需要的字段,这里以房屋名
-
Python异步爬取知乎热榜实例分享
目录 一.错误代码:摘要和详细的url获取不到 二.查看JS代码 一.错误代码:摘要和详细的url获取不到 import asyncio from bs4 import BeautifulSoup import aiohttp headers={ 'user-agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.198 Safa
-
使用python scrapy爬取天气并导出csv文件
目录 爬取xxx天气 安装 创建scray爬虫项目 文件说明 开始爬虫 补充:scrapy导出csv时字段的一些问题 1.字段顺序问题: 2.输出csv有空行的问题 总结 爬取xxx天气 爬取网址:https://tianqi.2345.com/today-60038.htm 安装 pip install scrapy 我使用的版本是scrapy 2.5 创建scray爬虫项目 在命令行如下输入命令 scrapy startproject name name为项目名称如,scrapy start
-
Python scrapy爬取小说代码案例详解
scrapy是目前python使用的最广泛的爬虫框架 架构图如下 解释: Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递等. Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎. Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Respon
-
python实现Scrapy爬取网易新闻
1. 新建项目 在命令行窗口下输入scrapy startproject scrapytest, 如下 然后就自动创建了相应的文件,如下 2. 修改itmes.py文件 打开scrapy框架自动创建的items.py文件,如下 # Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import s
-
python使用XPath解析数据爬取起点小说网数据
1. xpath 的介绍 xpath是一门在XML文档中查找信息的语言 优点: 可以在xml中找信息 支持HTML的查找 可以通过元素和属性进行导航 但是Xpath需要依赖xml的库,所以我们需要去安装lxml的库. 安装lxml库 我们先要安装lxml的库,直接在pycharm里安装即可: XML的树形结构: 元素-元素-属性-文本 使用XPath选取节点: nodename: 选取此节点的所有节点 /从根节点选择 // 从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置 . 选择当前节
-
Python 详解通过Scrapy框架实现爬取CSDN全站热榜标题热词流程
目录 前言 环境部署 实现过程 创建项目 定义Item实体 关键词提取工具 爬虫构造 中间件代码构造 制作自定义pipeline settings配置 执行主程序 执行结果 总结 前言 接着我的上一篇:Python 详解爬取并统计CSDN全站热榜标题关键词词频流程 我换成Scrapy架构也实现了一遍.获取页面源码底层原理是一样的,Scrapy架构更系统一些.下面我会把需要注意的问题,也说明一下. 提供一下GitHub仓库地址:github本项目地址 环境部署 scrapy安装 pip insta
-
Python下使用Scrapy爬取网页内容的实例
上周用了一周的时间学习了Python和Scrapy,实现了从0到1完整的网页爬虫实现.研究的时候很痛苦,但是很享受,做技术的嘛. 首先,安装Python,坑太多了,一个个爬.由于我是windows环境,没钱买mac, 在安装的时候遇到各种各样的问题,确实各种各样的依赖. 安装教程不再赘述.如果在安装的过程中遇到 ERROR:需要windows c/c++问题,一般是由于缺少windows开发编译环境,晚上大多数教程是安装一个VisualStudio,太不靠谱了,事实上只要安装一个WindowsS