opencv-python+yolov3实现目标检测
因为最近的任务有用到目标检测,所以昨天晚上、今天上午搞了一下,快速地了解了目标检测这一任务,并且实现了使用opencv进行目标检测。
网上资料挺乱的,感觉在搜资源上浪费了我不少时间,所以我写这篇博客,把我这段时间了解到的东西整理起来,供有缘的读者参考学习。
目标检测概况
目标检测是?
目标检测,粗略来说就是:输入图片/视频,经过处理,得到:目标的位置信息(比如左上角和右下角的坐标)、目标的预测类别、目标的预测置信度(confidence)。
拿Faster R-CNN这个算法举例:输入一个batch(batch size也可以为1)的图片或者视频,网络直接的outputs是这样的:
[batchId, classId, confidence, left, top, right, bottom],batchId, classId, confidence, left, top, right, bottom都是标量。
batchId表示这一个batch中,这张图片的id(也即index),后四个标量即目标的位置信息:左上角像素点和右下角像素点的坐标。
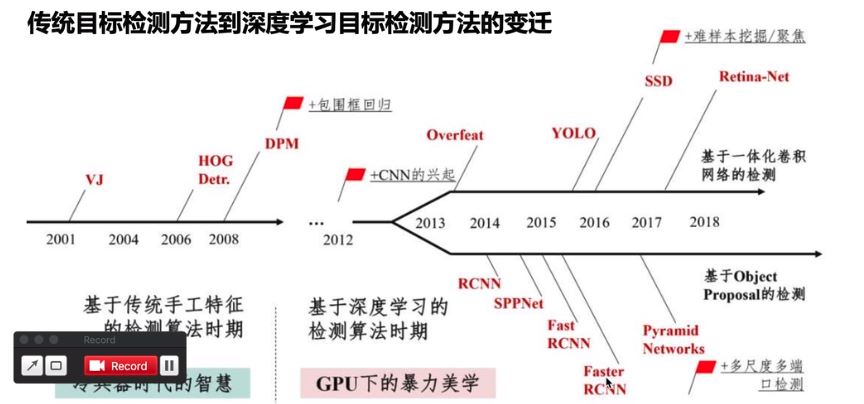
目标检测算法?
按照历史脉络来谈:
手工特征提取算法,如VJ、HOG、DPM
R-CNN算法(2014),最早的基于深度学习的目标检测器之一,其结构是两级网络:1)首先需要诸如选择性搜索之类的算法来提出可能包含对象的候选边界框;2)然后将这些区域传递到CNN算法进行分类;
R-CNN算法存在的问题是其仿真很慢,并且不是完整的端到端的目标检测器。
Fast R-CNN算法(2014末),对原始R-CNN进行了相当大的改进:提高准确度,并减少执行正向传递所花费的时间。
但是,该模型仍然依赖于外部区域搜索算法。
faster R-CNN算法(2015),真正的端到端深度学习目标检测器。删除了选择性搜索的要求,而是依赖于
(1)完全卷积的区域提议网络(RPN, Region Purpose Network),可以预测对象边界框和“对象”分数(量化它是一个区域的可能性的分数)。
(2)然后将RPN的输出传递到R-CNN组件以进行最终分类和标记。
R-CNN系列算法,都采取了two-stage策略。特点是:虽然检测结果一般都非常准确,但仿真速度非常慢,即使是在GPU上也仅获得5 FPS。
one-stage方法有:yolo(2015)、SSD(2015末),以及在这两个算法基础上改进的各论文提出的算法。这些算法的基本思路是:均匀地在图片的不同位置进行密集抽样,抽样时可以采用不同尺度和长宽比,然后利用CNN提取特征后直接进行分类与回归。
整个过程只需要一步,所以其优势是速度快,但是训练比较困难。
yolov3(2018)是yolo作者提出的第三个版本(之前还提过yolov2和它们的tinny版本,tinny版本经过压缩更快但是也降低了准确率)。yolov3支持80类物体的目标检测,完整列表[戳这里]: https://github.com/pjreddie/darknet/blob/master/data/coco.names
时间线:
yolov3模型简介
性能介绍
首先,套路,yolov3很强大(不强大我用它干啥呢)。速度上,它比 R-CNN 快 1000 倍,比 Fast R-CNN 快 100 倍。检测准确率上,它不是最准的:YOLOv3-608比 DSSD 更高,接近 FPN。但是它的速度不到后二者的1/3。
从下图也可以看出:

架构介绍

可以看出,他是一系列卷积、残差、上采样组成的。特点在于,它将预测分在三个尺度(Scale)进行(见图中三个彩色框),也在三个scale分别输出。
opencv-python实现
why opencv?
opencv( 3.4.2+版本)的dnn(Deep Neural Network-DNN)模块封装了Darknet框架,这个框架是
自己写的,它由封装了yolo算法。因为这么一层关系,我们可以使用opencv方便地使用yolo的各个版本,而且有数据(见下)证明OpenCV的DNN模块在 CPU的实现速度比使用 OpenML 的 Darknet 快9倍。

正文
我会先结合脚本片段讲解,再给出该脚本的完整代码,讲解。
先
引库
import numpy as np import cv2 as cv import os import time
参数:
yolo_dir = '/home/hessesummer/github/NTS-Net-my/yolov3' # YOLO文件路径 weightsPath = os.path.join(yolo_dir, 'yolov3.weights') # 权重文件 configPath = os.path.join(yolo_dir, 'yolov3.cfg') # 配置文件 labelsPath = os.path.join(yolo_dir, 'coco.names') # label名称 imgPath = os.path.join(yolo_dir, 'test.jpg') # 测试图像 CONFIDENCE = 0.5 # 过滤弱检测的最小概率 THRESHOLD = 0.4 # 非最大值抑制阈值
权重文件、配置文件、label名称的下载地址:
wget https://pjreddie.com/media/files/yolov3.weights wget https://github.com/pjreddie/darknet/blob/master/cfg/yolov3.cfg wget https://github.com/pjreddie/darknet/blob/master/data/coco.names
简单来说:
过滤弱检测的最小概率:置信度小于这个值的输出都不要了;
非最大值抑制阈值:允许框框重叠的程度(多框框检测同一个物体),供下面的NMS算法使用,该算法会根据该值将有重叠的框框合并。值为0时,不允许框框重叠。默认值是0.3。
详细来说:
我没查。您自己感兴趣再了解吧。
重头戏1:
# 加载网络、配置权重
net = cv.dnn.readNetFromDarknet(configPath, weightsPath) ## 利用下载的文件
# print("[INFO] loading YOLO from disk...") ## 可以打印下信息
# 加载图片、转为blob格式、送入网络输入层
img = cv.imread(imgPath)
blobImg = cv.dnn.blobFromImage(img, 1.0/255.0, (416, 416), None, True, False) ## net需要的输入是blob格式的,用blobFromImage这个函数来转格式
net.setInput(blobImg) ## 调用setInput函数将图片送入输入层
# 获取网络输出层信息(所有输出层的名字),设定并前向传播
outInfo = net.getUnconnectedOutLayersNames() ## 前面的yolov3架构也讲了,yolo在每个scale都有输出,outInfo是每个scale的名字信息,供net.forward使用
# start = time.time()
layerOutputs = net.forward(outInfo) # 得到各个输出层的、各个检测框等信息,是二维结构。
# end = time.time()
# print("[INFO] YOLO took {:.6f} seconds".format(end - start)) ## 可以打印下信息
layerOutputs是二维结构,第0维代表哪个输出层,第1维代表各个检测框。
其他的我都在注释里讲解了。
重头戏2:
# 拿到图片尺寸 (H, W) = img.shape[:2]
供下面使用:
# 过滤layerOutputs
# layerOutputs的第1维的元素内容: [center_x, center_y, width, height, objectness, N-class score data]
# 过滤后的结果放入:
boxes = [] # 所有边界框(各层结果放一起)
confidences = [] # 所有置信度
classIDs = [] # 所有分类ID
# # 1)过滤掉置信度低的框框
for out in layerOutputs: # 各个输出层
for detection in out: # 各个框框
# 拿到置信度
scores = detection[5:] # 各个类别的置信度
classID = np.argmax(scores) # 最高置信度的id即为分类id
confidence = scores[classID] # 拿到置信度
# 根据置信度筛查
if confidence > CONFIDENCE:
box = detection[0:4] * np.array([W, H, W, H]) # 将边界框放会图片尺寸
(centerX, centerY, width, height) = box.astype("int")
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# # 2)应用非最大值抑制(non-maxima suppression,nms)进一步筛掉
idxs = cv.dnn.NMSBoxes(boxes, confidences, CONFIDENCE, THRESHOLD) # boxes中,保留的box的索引index存入idxs
这里的NMS算法就是前面提到的NMS算法。
应用检测结果,这里是画出框框。
# 得到labels列表
with open(labelsPath, 'rt') as f:
labels = f.read().rstrip('\n').split('\n')
供下面使用:
# 应用检测结果
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(labels), 3), dtype="uint8") # 框框显示颜色,每一类有不同的颜色,每种颜色都是由RGB三个值组成的,所以size为(len(labels), 3)
if len(idxs) > 0:
for i in idxs.flatten(): # indxs是二维的,第0维是输出层,所以这里把它展平成1维
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in COLORS[classIDs[i]]]
cv.rectangle(img, (x, y), (x+w, y+h), color, 2) # 线条粗细为2px
text = "{}: {:.4f}".format(labels[classIDs[i]], confidences[i])
cv.putText(img, text, (x, y-5), cv.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # cv.FONT_HERSHEY_SIMPLEX字体风格、0.5字体大小、粗细2px
cv.imshow('目标检测结果', img)
cv.waitKey(0)
第一部分讲解结束,下面放完整代码:
再
import numpy as np
import cv2 as cv
import os
import time
yolo_dir = '/home/hessesummer/github/NTS-Net-my/yolov3' # YOLO文件路径
weightsPath = os.path.join(yolo_dir, 'yolov3.weights') # 权重文件
configPath = os.path.join(yolo_dir, 'yolov3.cfg') # 配置文件
labelsPath = os.path.join(yolo_dir, 'coco.names') # label名称
imgPath = os.path.join(yolo_dir, 'test.jpg') # 测试图像
CONFIDENCE = 0.5 # 过滤弱检测的最小概率
THRESHOLD = 0.4 # 非最大值抑制阈值
# 加载网络、配置权重
net = cv.dnn.readNetFromDarknet(configPath, weightsPath) # # 利用下载的文件
print("[INFO] loading YOLO from disk...") # # 可以打印下信息
# 加载图片、转为blob格式、送入网络输入层
img = cv.imread(imgPath)
blobImg = cv.dnn.blobFromImage(img, 1.0/255.0, (416, 416), None, True, False) # # net需要的输入是blob格式的,用blobFromImage这个函数来转格式
net.setInput(blobImg) # # 调用setInput函数将图片送入输入层
# 获取网络输出层信息(所有输出层的名字),设定并前向传播
outInfo = net.getUnconnectedOutLayersNames() # # 前面的yolov3架构也讲了,yolo在每个scale都有输出,outInfo是每个scale的名字信息,供net.forward使用
start = time.time()
layerOutputs = net.forward(outInfo) # 得到各个输出层的、各个检测框等信息,是二维结构。
end = time.time()
print("[INFO] YOLO took {:.6f} seconds".format(end - start)) # # 可以打印下信息
# 拿到图片尺寸
(H, W) = img.shape[:2]
# 过滤layerOutputs
# layerOutputs的第1维的元素内容: [center_x, center_y, width, height, objectness, N-class score data]
# 过滤后的结果放入:
boxes = [] # 所有边界框(各层结果放一起)
confidences = [] # 所有置信度
classIDs = [] # 所有分类ID
# # 1)过滤掉置信度低的框框
for out in layerOutputs: # 各个输出层
for detection in out: # 各个框框
# 拿到置信度
scores = detection[5:] # 各个类别的置信度
classID = np.argmax(scores) # 最高置信度的id即为分类id
confidence = scores[classID] # 拿到置信度
# 根据置信度筛查
if confidence > CONFIDENCE:
box = detection[0:4] * np.array([W, H, W, H]) # 将边界框放会图片尺寸
(centerX, centerY, width, height) = box.astype("int")
x = int(centerX - (width / 2))
y = int(centerY - (height / 2))
boxes.append([x, y, int(width), int(height)])
confidences.append(float(confidence))
classIDs.append(classID)
# # 2)应用非最大值抑制(non-maxima suppression,nms)进一步筛掉
idxs = cv.dnn.NMSBoxes(boxes, confidences, CONFIDENCE, THRESHOLD) # boxes中,保留的box的索引index存入idxs
# 得到labels列表
with open(labelsPath, 'rt') as f:
labels = f.read().rstrip('\n').split('\n')
# 应用检测结果
np.random.seed(42)
COLORS = np.random.randint(0, 255, size=(len(labels), 3), dtype="uint8") # 框框显示颜色,每一类有不同的颜色,每种颜色都是由RGB三个值组成的,所以size为(len(labels), 3)
if len(idxs) > 0:
for i in idxs.flatten(): # indxs是二维的,第0维是输出层,所以这里把它展平成1维
(x, y) = (boxes[i][0], boxes[i][1])
(w, h) = (boxes[i][2], boxes[i][3])
color = [int(c) for c in COLORS[classIDs[i]]]
cv.rectangle(img, (x, y), (x+w, y+h), color, 2) # 线条粗细为2px
text = "{}: {:.4f}".format(labels[classIDs[i]], confidences[i])
cv.putText(img, text, (x, y-5), cv.FONT_HERSHEY_SIMPLEX, 0.5, color, 2) # cv.FONT_HERSHEY_SIMPLEX字体风格、0.5字体大小、粗细2px
cv.imshow('detected image', img)
cv.waitKey(0)
结果:

到此这篇关于opencv-python+yolov3实现目标检测的文章就介绍到这了,更多相关opencv yolov3目标检测内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python opencv根据颜色进行目标检测的方法示例
颜色目标检测就是根据物体的颜色快速进行目标定位.使用cv2.inRange函数设定合适的阈值,即可以选出合适的目标. 建立项目colordetect.py,代码如下: #! /usr/bin/env python # -*- coding: utf-8 -*- import numpy as np import cv2 def colorDetect(): image = cv2.imread('./1.png') # 使用RGB颜色空间检测红 蓝 黄 灰,设置合适的阈值 boundaries
-
Python+OpenCV目标跟踪实现基本的运动检测
目标跟踪是对摄像头视频中的移动目标进行定位的过程,有着非常广泛的应用.实时目标跟踪是许多计算机视觉应用的重要任务,如监控.基于感知的用户界面.增强现实.基于对象的视频压缩以及辅助驾驶等. 有很多实现视频目标跟踪的方法,当跟踪所有移动目标时,帧之间的差异会变的有用:当跟踪视频中移动的手时,基于皮肤颜色的均值漂移方法是最好的解决方案:当知道跟踪对象的一方面时,模板匹配是不错的技术. 本文代码是做一个基本的运动检测 考虑的是"背景帧"与其它帧之间的差异 这种方法检测结果还是挺不错的,但是需要
-
Python Opencv任意形状目标检测并绘制框图
opencv 进行任意形状目标识别,供大家参考,具体内容如下 工作中有一次需要在简单的图上进行目标识别,目标的形状不固定,并且存在一定程度上的噪声影响,但是噪声影响不确定.这是一个简单的事情,因为图像并不复杂,现在将代码公布如下: import cv2 def otsu_seg(img): ret_th, bin_img = cv2.threshold(img, 0, 255, cv2.THRESH_BINARY+cv2.THRESH_OTSU) return ret_th, bin_img d
-
OpenCV+python实现实时目标检测功能
环境安装 安装Anaconda,官网链接Anaconda 使用conda创建py3.6的虚拟环境,并激活使用 conda create -n py3.6 python=3.6 //创建 conda activate py3.6 //激活 3.安装依赖numpy和imutils //用镜像安装 pip install -i https://pypi.tuna.tsinghua.edu.cn/simple numpy pip install -i https://pypi.tuna.tsinghua
-
Python 使用Opencv实现目标检测与识别的示例代码
在上章节讲述到图像特征检测与匹配 ,本章节是讲述目标检测与识别.后者是在前者的基础上进一步完善. 在本章中,我们使用HOG算法,HOG和SIFT.SURF同属一种类型的描述符.功能代码如下: import cv2 def is_inside(o, i): ox, oy, ow, oh = o ix, iy, iw, ih = i # 如果符合条件,返回True,否则返回False return ox > ix and oy > iy and ox + ow < ix + iw and o
-
Python Opencv实现单目标检测的示例代码
一 简介 目标检测即为在图像中找到自己感兴趣的部分,将其分割出来进行下一步操作,可避免背景的干扰.以下介绍几种基于opencv的单目标检测算法,算法总体思想先尽量将目标区域的像素值全置为1,背景区域全置为0,然后通过其它方法找到目标的外接矩形并分割,在此选择一张前景和背景相差较大的图片作为示例. 环境:python3.7 opencv4.4.0 二 背景前景分离 1 灰度+二值+形态学 轮廓特征和联通组件 根据图像前景和背景的差异进行二值化,例如有明显颜色差异的转换到HSV色彩空间进行分割. 1
-
python opencv检测目标颜色的实例讲解
实例如下所示: # -*- coding:utf-8 -*- __author__ = 'kingking' __version__ = '1.0' __date__ = '14/07/2017' import cv2 import numpy as np import time if __name__ == '__main__': Img = cv2.imread('example.png')#读入一幅图像 kernel_2 = np.ones((2,2),np.uint8)#2x2的卷积核
-
python+opencv+caffe+摄像头做目标检测的实例代码
首先之前已经成功的使用Python做图像的目标检测,这回因为项目最终是需要用摄像头的, 所以实现摄像头获取图像,并且用Python调用CAFFE接口来实现目标识别 首先是摄像头请选择支持Linux万能驱动兼容V4L2的摄像头, 因为之前用学ARM的时候使用的Smart210,我已经确认我的摄像头是支持的, 我把摄像头插上之後自然就在 /dev 目录下看到多了一个video0的文件, 这个就是摄像头的设备文件了,所以我就没有额外处理驱动的部分 一.检测环境 再来在开始前因为之前按着国嵌的指导手册安
-
python利用opencv调用摄像头实现目标检测
目录 使用到的库 实现思路 实现代码 2020/4/26更新:FPS计算 FPS记录的原理 FPS实现代码 使用到的库 好多人都想了解一下如何对摄像头进行调用,然后进行目标检测,于是我做了这个小BLOG. opencv-python==4.1.2.30 Pillow==6.2.1 numpy==1.17.4 这些都是通用的库,版本不同问题应该也不大. 实现思路 利用opencv调用摄像头,读取每一帧传入目标检测网络检测,将检测结果呈现. 由于本文所用的检测格式为RGB格式,CV2读取的时候会使用
-
opencv-python+yolov3实现目标检测
因为最近的任务有用到目标检测,所以昨天晚上.今天上午搞了一下,快速地了解了目标检测这一任务,并且实现了使用opencv进行目标检测. 网上资料挺乱的,感觉在搜资源上浪费了我不少时间,所以我写这篇博客,把我这段时间了解到的东西整理起来,供有缘的读者参考学习. 目标检测概况 目标检测是? 目标检测,粗略来说就是:输入图片/视频,经过处理,得到:目标的位置信息(比如左上角和右下角的坐标).目标的预测类别.目标的预测置信度(confidence). 拿Faster R-CNN这个算法举例:输入一个bat
-
如何基于OpenCV&Python实现霍夫变换圆形检测
简述 基于python使用opencv实现在一张图片中检测出圆形,并且根据坐标和半径标记出圆.不涉及理论,只讲应用. 霍夫变换检测圆形的原理 其实检测圆形和检测直线的原理差别不大,只不过直线是在二维空间,因为y=kx+b,只有k和b两个自由度.而圆形的一般性方程表示为(x-a)²+(y-b)²=r².那么就有三个自由度圆心坐标a,b,和半径r.这就意味着需要更多的计算量,而OpenCV中提供的cvHoughCircle()函数里面可以设定半径r的取值范围,相当于有一个先验设定,在每一个r来说,在
-
利用ImageAI库只需几行python代码实现目标检测
什么是目标检测 目标检测关注图像中特定的物体目标,需要同时解决解决定位(localization) + 识别(Recognition).相比分类,检测给出的是对图片前景和背景的理解,我们需要从背景中分离出感兴趣的目标,并确定这一目标的描述(类别和位置),因此检测模型的输出是一个列表,列表的每一项使用一个数组给出检出目标的类别和位置(常用矩形检测框的坐标表示). 通俗的说,Object Detection的目的是在目标图中将目标用一个框框出来,并且识别出这个框中的是啥,而且最好的话是能够将图片的所
-
opencv调用yolov3模型深度学习目标检测实例详解
目录 引言 建立相关目录 代码详解 附源代码 引言 opencv调用yolov3模型进行深度学习目标检测,以实例进行代码详解 对于yolo v3已经训练好的模型,opencv提供了加载相关文件,进行图片检测的类dnn. 下面对怎么通过opencv调用yolov3模型进行目标检测方法进行详解,付源代码 建立相关目录 在训练结果backup文件夹下,找到模型权重文件,拷到win的工程文件夹下 在cfg文件夹下,找到模型配置文件,yolov3-voc.cfg拷到win的工程文件夹下 在data文件夹下