详解JVM栈溢出和堆溢出
一、栈溢出StackOverflowError
栈是线程私有的,生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口等信息。
栈溢出:方法执行时创建的栈帧个数超过了栈的深度。
原因举例:方法递归
【示例】:
public class StackError {
private int i = 0;
public void fn() {
System.out.println(i++);
fn();
}
public static void main(String[] args) {
StackError stackError = new StackError();
stackError.fn();
}
}
【输出】:

解决方法:调整JVM栈的大小:-Xss
-Xss size
Sets the thread stack size (in bytes). Append the letter
korKto indicate KB,morMto indicate MB, andgorGto indicate GB. The default value depends on the platform:Linux/x64 (64-bit): 1024 KBmacOS (64-bit): 1024 KBOracle Solaris/x64 (64-bit): 1024 KBWindows: The default value depends on virtual memory
The following examples set the thread stack size to 1024 KB in different units:
-Xss1m
-Xss1024k
-Xss1048576This option is similar to
-XX:ThreadStackSize.
在IDEA中点击Run菜单的Edit Configuration如下图:
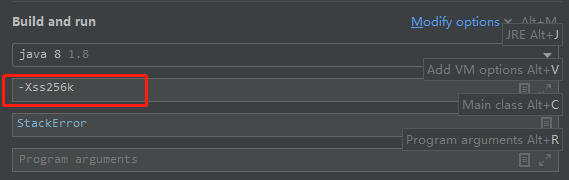
设置后,再次运行,会发现i的值变小,这是因为设置的-Xss值比原来的小:

二、堆溢出OutOfMemoryError:Java heap space
堆中主要存放的是对象。
堆溢出:不断的new对象会导致堆中空间溢出。如果虚拟机的栈内存允许动态扩展,当扩展栈容量无法申请到足够的内存时。
【示例】:
public class HeapError {
public static void main(String[] args) {
List<String> list = new ArrayList<>();
try {
while (true) {
list.add("Floweryu");
}
} catch (Throwable e) {
System.out.println(list.size());
e.printStackTrace();
}
}
}
【输出】:

解决方法:调整堆的大小:Xmx
-Xmx size
Specifies the maximum size (in bytes) of the memory allocation pool in bytes. This value must be a multiple of 1024 and greater than 2 MB. Append the letter
korKto indicate kilobytes,morMto indicate megabytes, andgorGto indicate gigabytes. The default value is chosen at runtime based on system configuration. For server deployments,-Xmsand-Xmxare often set to the same value. The following examples show how to set the maximum allowed size of allocated memory to 80 MB by using various units:-Xmx83886080
-Xmx81920k
-Xmx80mThe
-Xmxoption is equivalent to-XX:MaxHeapSize.
设置-Xmx256M后,输入如下,比之前小:

到此这篇关于详解JVM栈溢出和堆溢出的文章就介绍到这了,更多相关栈溢出和堆溢出内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

详解JVM中的GC调优
那些GC的默认值 其实GC或者说JVM的参数非常非常的多,有控制内存使用的: 有控制JIT的: 有控制分代比例的,也有控制GC并发的: 当然,大部分的参数其实并不需要我们自行去调整,JVM会很好的动态帮我们设置这些变量的值. 如果我们不去设置这些值,那么对GC性能比较有影响的参数和他们的默认值有哪些呢? GC的选择 我们知道JVM中的GC有很多种,不同的GC选择对java程序的性能影响还是比较大的. 在JDK9之后,G1已经是默认的垃圾回收器了. 我们看一下G1的调优参数. G1是基于分代技术的
-
记一次公司JVM堆溢出抽丝剥茧定位的过程解析
背景 公司线上有个tomcat服务,里面合并部署了大概8个微服务,之所以没有像其他微服务那样单独部署,其目的是为了节约服务器资源,况且这8个服务是属于边缘服务,并发不高,就算宕机也不会影响核心业务. 因为并发不高,所以线上一共部署了2个tomcat进行负载均衡. 这个tomcat刚上生产线,运行挺平稳.大概过了大概1天后,运维同事反映2个tomcat节点均挂了.无法接受新的请求了.CPU飙升到100%. 排查过程一 接手这个问题后.首先大致看了下当时的JVM监控. CPU的确居高不下 FULL
-
java内存溢出示例(堆溢出、栈溢出)
堆溢出: 复制代码 代码如下: /** * @author LXA * 堆溢出 */ public class Heap { public static void main(String[] args) { ArrayList list=new ArrayList(); while(true) { list.add(new Heap()); } } } 报错: java.lang.OutOfMemoryError: Java heap space 栈溢出: 复制代码 代码如下: /** * @a
-
详解JVM栈溢出和堆溢出
一.栈溢出StackOverflowError 栈是线程私有的,生命周期与线程相同,每个方法在执行的时候都会创建一个栈帧,用来存储局部变量表,操作数栈,动态链接,方法出口等信息. 栈溢出:方法执行时创建的栈帧个数超过了栈的深度. 原因举例:方法递归 [示例]: public class StackError { private int i = 0; public void fn() { System.out.println(i++); fn(); } public static void mai
-
详解JVM系列之内存模型
1. 内存模型和运行时数据区 这一章学习java虚拟机内存模型(Java Virtual machine menory model),可以这样理解,jvm运行时数据库是一种规范,而JVM内存模型是对改规范的实现 java虚拟机重点存储数据的是堆和方法区,所以本章节也重点从这两个方面进行比较详细描述.堆和方法区是内存共享的,而java虚拟机栈.Native方法栈.程序计数器是线程私有的 2.思维导图和图例 一个是非堆区(方法区),方法区也一般被称之为"永久代".另外一个是堆区,分为you
-
详解jvm中的标量替换
概述 通常在java中创建一个对象,大家都认为是在堆中创建. 在jdk6开始有逃逸分析,标量替换等技术,关于在堆中创建对象不再绝对. 关于标量替换,通过以下几点进行概述: 逃逸分析 标量替换是什么 测试标量替换 逃逸分析 逃逸分析是一种分析技术,分析对象的动态作用域,供其他优化措施提供依据.比如分析一个对象不会逃逸到方法之外或线程之外,其它优化措施(栈上分配,标量替换等)根据逃逸程度进行优化. 逃逸分析示例 public class EscapeAnalysis { public Person
-
详解JVM的分代模型
前言 上篇文章我们一起对jvm的内存模型有了比较清晰的认识,小伙伴们可以参考JVM内存模型不再是秘密这篇文章做一个复习. 本篇文章我们将针对jvm堆内存的分代模型做一个详细的解析,和大家一起轻松理解jvm的分代模型. 相信看过其他文章的小伙伴们可能都知道,jvm的分代模型包括:年轻代.老年代.永久代. 那么它们分别代表着什么角色呢?我们先来看一段代码 public class Main { public static void main(String[] args) { while (true)
-
详解jvm对象的创建和分配
对象的创建 创建方式 1. new 关键字直接创建. new ObjectName(). 2.通过 Class 反射对象的 newInstance() 方法.ObjectName obj = ObjectName.class.newInstance(). 3.通过 Class 反射对象获取 Constructor 类,再调用其 newInstance() 方法. ObjectName obj = ObjectName.class.getConstructor.newInstance().
-
详解C语言之缓冲区溢出
一.缓冲区溢出原理 栈帧结构的引入为高级语言中实现函数或过程调用提供直接的硬件支持,但由于将函数返回地址这样的重要数据保存在程序员可见的堆栈中,因此也给系统安全带来隐患.若将函数返回地址修改为指向一段精心安排的恶意代码,则可达到危害系统安全的目的.此外,堆栈的正确恢复依赖于压栈的EBP值的正确性,但EBP域邻近局部变量,若编程中有意无意地通过局部变量的地址偏移窜改EBP值,则程序的行为将变得非常危险. 由于C/C++语言没有数组越界检查机制,当向局部数组缓冲区里写入的数据超过为其分配的大小时,就
-
详解Jvm中时区设置方式
这篇文章memo一下Jvm中关于时区设定的基础操作. Java的时区设定 这里列出如下三种方式 方式 说明 TimeZone.setDefault方式 通过java的utils下的TimeZone进行动态设定 user.timezone传递方式 运行时通过传递-Duser.timezone=xxx进行设定 TZ环境变量方式 通过export的TZ环境变量进行设定 TimeZone.setDefault方式 Sample代码如下: sh-4.2# cat TestTimeZone.java imp
-
详解JVM之运行时常量池
class文件中的常量池 之前我们在讲class文件的结构时,提到了每个class文件都有一个常量池,常量池中存了些什么东西呢? 字符串常量,类和接口名字,字段名,和其他一些在class中引用的常量. 运行时常量池 但是只有class文件中的常量池肯定是不够的,因为我们需要在JVM中运行起来. 这时候就需要一个运行时常量池,为JVM的运行服务. 运行时常量池和class文件的常量池是一一对应的,它就是class文件的常量池来构建的. 运行时常量池中有两种类型,分别是symbolic refere
-
详解JVM系列之对象的锁状态和同步
java对象头 Java的锁状态其实可以分为三种,分别是偏向锁,轻量级锁和重量级锁. 在Java HotSpot VM中,每个对象前面都有一个class指针和一个Mark Word. Mark Word存储了哈希值以及分代年龄和标记位等,通过这些值的变化,JVM可以实现对java对象的不同程度的锁定. 还记得我们之前分享java对象的那张图吗? javaObject对象的对象头大小根据你使用的是32位还是64位的虚拟机的不同,稍有变化.这里我们使用的是64位的虚拟机为例. Object的对象头,