Python如何爬取qq音乐歌词到本地
前言
本文的文字及图片来源于网络,仅供学习、交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理。
闲来无事听听歌,听到无聊唠唠嗑,你有没有特别喜欢的音乐,你有没有思考或者尝试过把自己喜欢的歌曲的歌词全部给下载下来呢?
没错,我这么干了,今天我们以QQ音乐为例,使用Python爬虫的方式把自己喜欢的音乐的歌词爬取到本地!

下面就来详细讲解如何一步步操作,文末附完整代码。
01
寻找真正的客户端(client_search)(客户端搜索)
搜索网站:https://y.qq.com/,打开QQ音乐网站。

然后搜索想要的歌手,右击鼠标,点击检查。

然后选中Network,并点击蓝色底纹的页面

02
找到真正的url

瞧见是不是很头疼,别担心,你只需要这些(https://c.y.qq.com/soso/fcgi-bin/client_search_cp),后面的都是参数(说法不是很准确)
03
写入参数

在这个位置下的所有参数复制过来,就像这样

我们不难发现,p代表的是页数(我这里使用了循环,详情看一下代码),w的话代表歌手名字(可以进行更改)
然后我们可以获取到歌手的名字,歌曲专辑,音频时间,播放链接(这一部分的代码在parse_page这个函数中)

然后就到了最要命的歌词环节,shit,头疼
04
1、点击歌词,Network

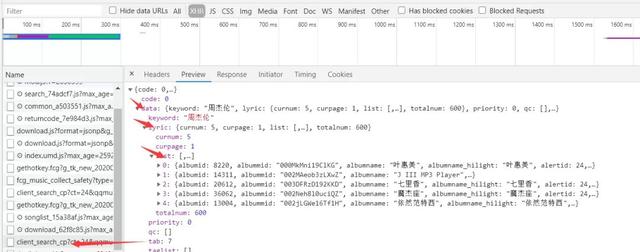
我们可以看到一页只有5首歌的歌词,然后我们进行爬取(在lyric_a代码中)
2、我们需要更改params参数,同样在最下面,与上面寻找一致
3、使用openyxl放入excel表格中
(1)导入openyxl模块

(2)创建

(3)放入并命名excel
这是例图
这里不用csv是因为初学,技术太菜,出来全是逗号(真·逗号分隔符)

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python爬取网易云音乐上评论火爆的歌曲
前言 网易云音乐这款音乐APP本人比较喜欢,用户量也比较大,而网易云音乐之所以用户众多和它的歌曲评论功能密不可分,很多歌曲的评论非常有意思,其中也不乏很多感人的评论.但是,网易云音乐并没有提供热评排行榜和按评论排序的功能,没关系,本文就使用爬虫给大家爬一爬网易云音乐上那些热评的歌曲. 结果 对过程没有兴趣的童鞋直接看这里啦. 评论数大于五万的歌曲排行榜 首先恭喜一下我最喜欢的歌手(之一)周杰伦的<晴天>成为网易云音乐第一首评论数过百万的歌曲! 通过结果发现目前评论数过十万的歌曲正好十首,通过这
-
用Python爬取QQ音乐评论并制成词云图的实例
环境:Ubuntu16.4 python版本:3.6.4 库:wordcloud 这次我们要讲的是爬取QQ音乐的评论并制成云词图,我们这里拿周杰伦的等你下课来举例. 第一步:获取评论 我们先打开QQ音乐,搜索周杰伦的<等你下课>,直接拉到底部,发现有5000多页的评论. 这时候我们要研究的就是怎样获取每页的评论,这时候我们可以先按下F12,选择NetWork,我们可以先点击小红点清空数据,然后再点击一次,开始监控,然后点击下一页,看每次获取评论的时候访问获取的是哪几条数据.最后我们就能看到下图
-
python爬取酷狗音乐排行榜
本文为大家分享了python爬取酷狗音乐排行榜的具体代码,供大家参考,具体内容如下 #coding=utf-8 from pymongo import MongoClient import time import requests from lxml import etree client = MongoClient() #连接mongo hello = client.hello #连接数据库 user = hello.song #连接表 headers = { 'User-Agent': 'M
-
Python爬取网易云音乐热门评论
最近在研究文本挖掘相关的内容,所谓巧妇难为无米之炊,要想进行文本分析,首先得到有文本吧.获取文本的方式有很多,比如从网上下载现成的文本文档,或者通过第三方提供的API进行获取数据.但是有的时候我们想要的数据并不能直接获取,因为并不提供直接的下载渠道或者API供我们获取数据.那么这个时候该怎么办呢?有一种比较好的办法是通过网络爬虫,即编写计算机程序伪装成用户去获得想要的数据.利用计算机的高效,我们可以轻松快速地获取数据. 那么该如何写一个爬虫呢?有很多种语言都可以写爬虫,比如Java,php,py
-
Python爬取qq music中的音乐url及批量下载
前言 qq music上的音乐还是不少的,有些时候想要下载好听的音乐,但有每次在网页下载都是烦人的登录什么的.于是,来了个qqmusic的爬虫.至少我觉得for循环爬虫,最核心的应该就是找到待爬元素所在url吧.下面开始找吧(讲的不对不要笑我) 实现如下 #寻找url: 这个url可不想其他的网站那么好找.把我给累得不轻,关键是数据多,从那么多数据里面挑出有用的数据,最后组合为music真正的music.昨天做的时候整理的几个中间url: #url1:https://c.y.qq.com/sos
-
Python使用Beautiful Soup爬取豆瓣音乐排行榜过程解析
前言 要想学好爬虫,必须把基础打扎实,之前发布了两篇文章,分别是使用XPATH和requests爬取网页,今天的文章是学习Beautiful Soup并通过一个例子来实现如何使用Beautiful Soup爬取网页. 什么是Beautiful Soup Beautiful Soup是一款高效的Python网页解析分析工具,可以用于解析HTL和XML文件并从中提取数据. Beautiful Soup输入文件的默认编码是Unicode,输出文件的编码是UTF-8. Beautiful Soup具有将
-
python爬虫之爬取百度音乐的实现方法
在上次的爬虫中,抓取的数据主要用到的是第三方的Beautifulsoup库,然后对每一个具体的数据在网页中的selecter来找到它,每一个类别便有一个select方法.对网页有过接触的都知道很多有用的数据都放在一个共同的父节点上,只是其子节点不同.在上次爬虫中,每一类数据都要从其父类(包括其父节点的父节点)上往下寻找ROI数据所在的子节点,这样就会使爬虫很臃肿,因为很多数据有相同的父节点,每次都要重复的找到这个父节点.这样的爬虫效率很低. 因此,笔者在上次的基础上,改进了一下爬取的策略,笔者以
-
python爬取网易云音乐评论
本文实例为大家分享了python爬取网易云音乐评论的具体代码,供大家参考,具体内容如下 import requests import bs4 import json def get_hot_comments(res): comments_json = json.loads(res.text) hot_comments = comments_json['hotComments'] with open("hotcmments.txt", 'w', encoding = 'utf-8') a
-
Python如何爬取qq音乐歌词到本地
前言 本文的文字及图片来源于网络,仅供学习.交流使用,不具有任何商业用途,版权归原作者所有,如有问题请及时联系我们以作处理. 闲来无事听听歌,听到无聊唠唠嗑,你有没有特别喜欢的音乐,你有没有思考或者尝试过把自己喜欢的歌曲的歌词全部给下载下来呢? 没错,我这么干了,今天我们以QQ音乐为例,使用Python爬虫的方式把自己喜欢的音乐的歌词爬取到本地! 下面就来详细讲解如何一步步操作,文末附完整代码. 01 寻找真正的客户端(client_search)(客户端搜索) 搜索网站:https://y.q
-
Python爬取qq空间说说的实例代码
具体代码如下所示: #coding:utf-8 #!/usr/bin/python3 from selenium import webdriver import time import re import importlib2 import sys importlib2.reload(sys) def startSpider(): driver = webdriver.Chrome('/Users/zachary/zachary/chromedriver.exe') #这个是chormedriv
-
详解python selenium 爬取网易云音乐歌单名
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错. 结果: 一共37页,爬取完毕后关闭浏览器 完整代码: url = 'https://music.163.com/#/discover/playlist/' from selenium import webdriver import time # 创建浏览器对象 window = webdriver.Chrome('./chromedriver') win
-
python爬虫爬取监控教务系统的思路详解
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我. 脚本运行效果: 服务器: 发送邮件通知: 代码如下: import datetime import time from email.header import Header impor
-
python 爬虫爬取京东ps4售卖情况
代码 #!/usr/bin/env python # -*- coding: utf-8 -*- # @File : HtmlParser.py # @Author: 赵路仓 # @Date : 2020/3/17 # @Desc : # @Contact : 398333404@qq.com import json from lxml import etree import requests from bs4 import BeautifulSoup url="https://search.j
-
Python爬虫爬取ts碎片视频+验证码登录功能
目标:爬取自己账号中购买的课程视频. 一.实现登录账号 这里采用的是手动输入验证码的方式,有能力的盆友也可以通过图像识别的方式自动填写验证码.登录后,采用session保持登录. 1.获取验证码地址 第一步:首先查看验证码对应的代码,可以从图中看到验证码图片的地址是:https://per.enetedu.com/Common/CreateImage?tmep_seq=1613623257608 颜色标红的部分tmep_seq=1613623257608,是为了解决浏览器缓存问题加的时间戳,因此
-
Python爬虫爬取全球疫情数据并存储到mysql数据库的步骤
思路:使用Python爬虫对腾讯疫情网站世界疫情数据进行爬取,封装成一个函数返回一个 字典数据格式的对象,写另一个方法调用该函数接收返回值,和数据库取得连接后把 数据存储到mysql数据库. 一.mysql数据库建表 CREATE TABLE world( id INT(11) NOT NULL AUTO_INCREMENT, dt DATETIME NOT NULL COMMENT '日期', c_name VARCHAR(35) DEFAULT NULL COMMENT '国家'