python实现PDF中表格转化为Excel的方法
这几天想统计一下《中国人文社会科学期刊 AMI 综合评价报告(2018 年):A 刊评价报告》中的期刊,但是只找到了该报告的PDF版,对于表格的编辑不太方便,于是想到用Python将表格转成Excel格式。
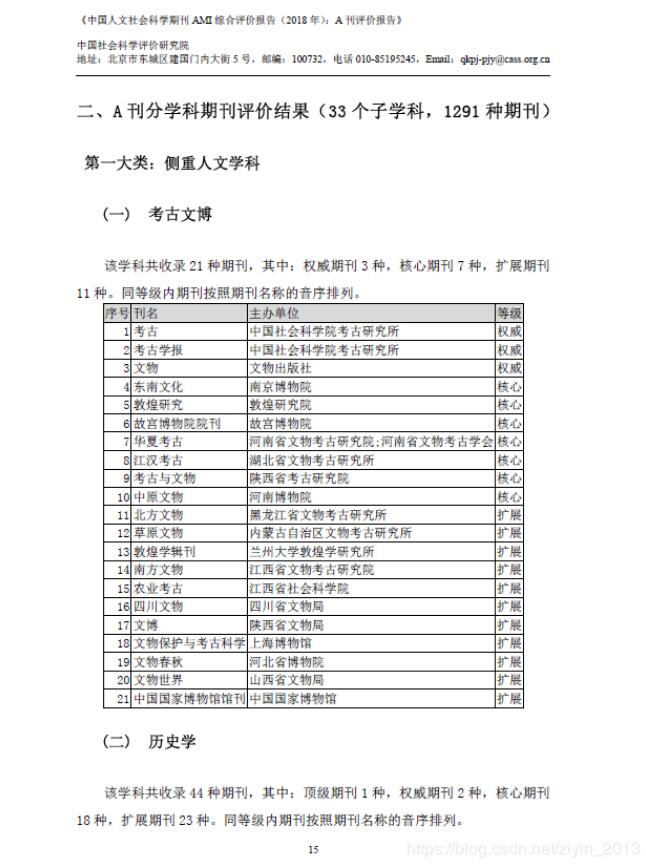
看过别人写的博客,发现Python解析PDF有以下四种方式:
-pdfminer:擅长文字的解析,把表格解析成普通的文本,没有格式;
-pdf2html:把pdf解析成html,但html的标签并没有规律,解析一个表格还可以,多个表格的话不太好提取;
-tabula:对于简单的表格,即单元格中没有换行的,表头表尾形式不复杂的,使用比较方便。但是单脑需要Java环境;
-pdfplumber:是一个可以处理pdf格式信息的库。可以查找关于每个文本字符、矩阵、和行的详细信息,也可以对表格进行提取并进行可视化调试。
本文采用pdfplumber库读取PDF中的表格,运行环境:Python3.5.2,Anaconda4.2.0。首先简单介绍一下pdfplumber库:
-pdfplumber.pdf中包含了.metadata和.pages两个属性:
.metadata是一个包含pdf信息的字典。
.pages是一个包含页面信息的列表。
-pdfplumber.page的类中包含的主要的属性:
.page_number 页码。
.width 页面宽度。
.height 页面高度。
.objects/.chars/.lines/.rects 这些属性中每一个都是一个列表,每个列表都包含一个字典,每个字典用于说明页面中的对象信息, 包括直线,字符, 方格等位置信息。
-一些常用的方法:
.extract_text() 用来提页面中的文本,将页面的所有字符对象整理为的那个字符串。
.extract_words() 返回的是所有的单词及其相关信息。
.extract_tables() 提取页面的表格。
.to_image() 用于可视化调试时,返回PageImage类的一个实例。
import pdfplumber
import pandas as pd
path = 'test.pdf'
pdf = pdfplumber.open(path)
i=1
#writer=pd.ExcelWriter('output.xlsx')
df=pd.DataFrame(columns=['序号','刊名','主办单位','等级'])
sheetname=['考古文博','历史学','马克思主义理论','民族学与文化学','文学-外国文学','文学-中国文学','艺术学','语言学','哲学','宗教学','法学'
,'管理学','环境科学','教育学','经济学-财政科学','经济学-工业经济','经济学-金融','经济学-经济管理','经济学-经济综合','经济学-贸易经济'
,'经济学-农业经济','经济学-世界经济','人文地理学','社会学','体育学','统计学','图书馆情报与档案学','心理学','新闻学与传播学'
,'政治学-国际政治','政治学-中国政治','综合-高校综合性学报','综合-综合性人文社科期刊']
##由于存在一个表格跨页的情况,先将所有表格存放在一个DataFrame中,再根据序号拆分。
for page in pdf.pages[17:59]:
print (page)
# 获取当前页面的全部文本信息,包括表格中的文字
# print(page.extract_text())
for table in page.extract_tables():
#print(table)
df=df.append(pd.DataFrame(table[1:],columns=table[0]),ignore_index=True)
print (df)
writer=pd.ExcelWriter('output3.xlsx')
new_df=pd.DataFrame()
j=1
index=[]
#记录序号==1的行索引,用于后面的表格拆分
for i in range(len(df)):
if df.ix[i,0]=='1':
index.append(i)
print ("################")
index.append(len(df))
#print (index)
#按行索引将内容切片并逐个添加到表中
for t in range(len(index)-1):
new_df=df.ix[index[t]:index[t+1]-1,:]
#print (new_df)
new_df.to_excel(writer,sheet_name=sheetname[t],encoding='gb2312',index=None)
writer.save()
pdf.close()
print('finished')
最终保存为Excel。

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
windows下Python实现将pdf文件转化为png格式图片的方法
本文实例讲述了windows下Python实现将pdf文件转化为png格式图片的方法.分享给大家供大家参考,具体如下: 最近工作中需要把pdf文件转化为图片,想用Python来实现,于是在网上找啊找啊找啊找,找了半天,倒是找到一些代码. 1.第一个找到的代码,我试了一下好像是反了,只能实现把图片转为pdf,而不能把pdf转为图片... 参考链接:https://zhidao.baidu.com/question/745221795058982452.html 代码如下: #!/usr/bin/e
-
Python实现将doc转化pdf格式文档的方法
本文实例讲述了Python实现将doc转化pdf格式文档的方法.分享给大家供大家参考,具体如下: #-*- coding:utf-8 -*- # doc2pdf.py: python script to convert doc to pdf with bookmarks! # Requires Office 2007 SP2 # Requires python for win32 extension import sys, os from win32com.client import Dispa
-
python实现PDF中表格转化为Excel的方法
这几天想统计一下<中国人文社会科学期刊 AMI 综合评价报告(2018 年):A 刊评价报告>中的期刊,但是只找到了该报告的PDF版,对于表格的编辑不太方便,于是想到用Python将表格转成Excel格式. 看过别人写的博客,发现Python解析PDF有以下四种方式: -pdfminer:擅长文字的解析,把表格解析成普通的文本,没有格式: -pdf2html:把pdf解析成html,但html的标签并没有规律,解析一个表格还可以,多个表格的话不太好提取: -tabula:对于简单的表格,即单元
-

Python实现将Word表格嵌入到Excel中
今日需求 其实就是把Word中的表格转到Excel中,顺便做一个调整.这个需求在实际工作中,很多人还是经常碰到的! 如果单单是两个表格,那只要简单的复制黏贴即可,但如果上百了呢?那就得考虑自动化了.好在今天碰到的需求中的原文件格式是比较有规律的,那直接来尝试一下. # 首先要pip install python-docx # 如果原文件是doc格式,那就先转成docx from docx import Document import pandas as pd path = "./word表格转e
-
python从PDF中提取数据的示例
01 前言 数据是数据科学中任何分析的关键,大多数分析中最常用的数据集类型是存储在逗号分隔值(csv)表中的干净数据.然而,由于可移植文档格式(pdf)文件是最常用的文件格式之一,因此每个数据科学家都应该了解如何从pdf文件中提取数据,并将数据转换为诸如"csv"之类的格式,以便用于分析或构建模型. 在本文中,我们将重点讨论如何从pdf文件中提取数据表.类似的分析可以用于从pdf文件中提取其他类型的数据,如文本或图像.我们将说明如何从pdf文件中提取数据表,然后将其转换为适合于进一步分
-
Python提取PDF中的图片的实现示例
目录 1.导入相关库 2.具体实现 2.1.使用正则表达式查找PDF中的图片 2.2.打印PDF的相关信息 2.3.遍历PDF中的对象,遇到是图像才进行下一步,不然就continue 2.4.将图像存为png格式 2.5.输入pdf路径,即可运行 3.结果预览 3.1.程序结果 3.2.原本的pdf 3.3.提取出来的图片 1.导入相关库 import fitz import time import re import os 2.具体实现 为了方便和其他模块组合,我直接写了个函数完成这个功能,实
-
Python实现读取txt文件并转换为excel的方法示例
本文实例讲述了Python实现读取txt文件并转换为excel的方法.分享给大家供大家参考,具体如下: 这里的txt文件内容格式为: 892天平天国定都在?A开封B南京C北京(B) Python代码如下: # coding=utf-8 ''''' main function:主要实现把txt中的每行数据写入到excel中 ''' ################# #第一次执行的代码 import xlwt #写入文件 import xlrd #打开excel文件 import os txtFi
-
python删除列表中特定元素的几种方法
目录 前言 思路 方法1 方法2:使用while循环 方法3:for循环倒序删除空字符串 方法4:拷贝原列表 前言 题目如下: 给定一个仅包含大小写字母和空格 ’ ’ 的字符串 s,返回其最后一个单词的长度.如果字符串从左向右滚动显示,那么最后一个单词就是最后出现的单词. 如果不存在最后一个单词,请返回 0 . 说明:一个单词是指仅由字母组成.不包含任何空格字符的 最大子字符串. 示例: 输入: "Hello World"输出: 5 思路 题目要求给一个字符串s,s仅包含字母和空格字符
-
vue2.0 + element UI 中 el-table 数据导出Excel的方法
1.安装相关依赖 主要是两个依赖 npm install --save xlsx file-saver 如果想详细看着两个插件使用,请移步github. https://github.com/SheetJS/js-xlsx https://github.com/eligrey/FileSaver.js 2.组件里头引入 import FileSaver from 'file-saver' import XLSX from 'xlsx' 3.组件methods里写一个方法 exportExcel
-
Python在不同场景合并多个Excel的方法
目录 前言 01 合并多个同字段的excel 02 拼接多个不同字段的excel 03 合并一个excel的多个sheet 前言 三种场景: 多个同字段的excel文件合并成一个excel 多个不同字段的excel文件拼接成一个excel 一个excel的多个sheet合并成一个sheet 辰哥目前想到的仅是辰哥遇到的这三种情况 01 合并多个同字段的excel 这里辰哥先新建三个excel文件:11.xlsx:12.xlsx:13.xlsx:并往里填充数据,数据如下: 1.xlsx 1.xls
-
Yii中使用PHPExcel导出Excel的方法
本文实例讲述了Yii中使用PHPExcel导出Excel的方法.分享给大家供大家参考.具体分析如下: 最近在研究PHP的Yii框架,很喜欢,碰到导出Excel的问题,研究了一下,就有了下面的方法. 1.首先在cofig/main.php中添加对PHPExcel的引用,我的方法是这样,代码如下: 复制代码 代码如下: // autoloading model and component classes 'import'=>array( /*'application.modu
-
Python统计日志中每个IP出现次数的方法
本文实例讲述了Python统计日志中每个IP出现次数的方法.分享给大家供大家参考.具体如下: 这脚本可用于多种日志类型,本人测试MDaemon的all日志文件大小1.23G左右,分析用时2~3分钟 代码很简单,很适合运维人员,有不足的地方请大家指出哦 #-*- coding:utf-8 -*- import re,time def mail_log(file_path): global count log=open(file_path,'r') C=r'\.'.join([r'\d{1,3}']