Python3之乱码\xe6\x97\xa0\xe6\xb3\x95处理方式
查看字符编码:
import chardet
response = chardet.detect(b'\xe5\xbd\x93\xe5\x89\x8d\xe7\x9b\xae\xe5\xbd\x95\xe4\xb8\x8b\xe6\x89\x80\xe6\x9c\x89\xe6\x96\x87\xe4\xbb\xb6\xe5\x90\x8d\xe6\xb1\x87\xe6\x80\xbb\xe5\x88\x97\xe8\xa1\xa8')
print(response)
{'encoding': 'utf-8', 'confidence': 0.99, 'language': ''}
乱码字符转换:
response = b'\xe5\xbd\x93\xe5\x89\x8d\xe7\x9b\xae\xe5\xbd\x95\xe4\xb8\x8b\xe6\x89\x80\xe6\x9c\x89\xe6\x96\x87\xe4\xbb\xb6\xe5\x90\x8d\xe6\xb1\x87\xe6\x80\xbb\xe5\x88\x97\xe8\xa1\xa8'
print(response.decode('utf8'))
# def decode_char(*args):
# response = args[0]
# print(response.decode('utf8'))
#
# c = b'\a8\xe5\x90\xa7\xef\xbc\x81'
#
# decode_char(c)
补充知识:python3 中怎么把类似这样的'\xe5\xae\x9d\xe9\xb8\xa1\xe5\xb8\x82'转换成汉字输出
在编程的过程中遇到了类似的困扰,网上查了很多解决思路,终于算是明白了一些,这里和大家分享 一下。
python3相对于python2最重要的新特性之一就是对字符串(文本)和二进制数据流做了明确的区分,文本总是Unicode,由字符类型表示,而二进制数据则由bytes类型表示,python3不会以任意隐式方式混用字节型和字符型,也不能拼接字符串和字节流(python2中可以,会自动进行转换),也不能在字节流中搜索字符串,也不能将字符串传入参数为字节流的函数。
str和bytes类型之间的相互转换
字符串类str有一个encode()方法,它是字符串向比特流的编码过程。
bytes类则有一个decode()方法,它是比特流向字符串的解码过程
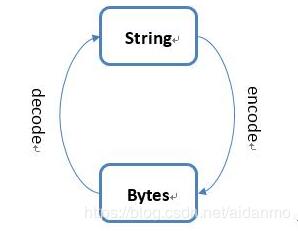
encode过程
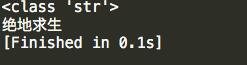
s = '绝地求生' ss = s.encode() print(type(ss)) print(ss)
运行结果:

decode过程
s = b'\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f' ss = s.decode() print(type(ss)) print(ss)
运行结果:
了解过基本的转化过程,下面回到主题,如何将'\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f'转换成汉字输出呢?
要解决的问题是将bytes类型的内容以汉字的形式输出,但是该部分内容是字符串类型。因此首先需要将该str转换成bytes类型,再decode解码为str输出。这里需要用到的方法是encode(‘raw_unicode_escape')。当然,也可以使用decode(‘raw_unicode_escape')方法输出内容为bytes形式的字符串
s = '\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f'
ss = s.encode('raw_unicode_escape')
print(type(ss))
print(ss)
sss = ss.decode()
print(sss)
结果:

方法补充:如果我们直接定义bytes类型的变量,也可以直接使用str(s, ‘utf8')的方式输出汉字
s = b'\xe7\xbb\x9d\xe5\x9c\xb0\xe6\xb1\x82\xe7\x94\x9f' print(type(s)) print(s) ss = str(s, 'utf8') print(ss)
结果:

第二种方法可以输出从网络上直接抓取的网页中包含的中文字符。
我们使用如下代码,抓取网页www.baidu.com。
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
html = response.read()
print(html)
显示的结果中,中文部分会以\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80代替,这里可以使用方法二进行转换。
import urllib.request
response = urllib.request.urlopen('http://www.baidu.com')
html =str(response.read(),'utf-8')
print(html)
结果如下:
以上这篇Python3之乱码\xe6\x97\xa0\xe6\xb3\x95处理方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python3如何解决字符编码问题详解
编码 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节.比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295. 由于计算机是美国人发明的,因此,最早只有127个字母被编码到计算机里,也就是大小写英文字母.数字和一些符号,这个编码表被称为ASC
-
python中文乱码的解决方法
乱码原因:源码文件的编码格式为utf-8,但是window的本地默认编码是gbk,所以在控制台直接打印utf-8的字符串当然是乱码了! 解决方法:1.print mystr.decode('utf-8').encode('gbk')2.比较通用的方法: 复制代码 代码如下: import systype = sys.getfilesystemencoding()print mystr.decode('utf-8').encode(type)
-
解决Python3中的中文字符编码的问题
python3中str默认为Unicode的编码格式 Unicode是一32位编码格式,不适合用来传输和存储,所以必须转换成utf-8,gbk等等 所以在Python3中必须将str类型转换成bytes类型的 在Python中使用encode的方式可以进行字符的编码 实际用法: >>>a = "中国" >>> a.encode("utf-8") b'\xe4\xb8\xad\xe5\x9b\xbd' >>> a.
-
Python3之乱码\xe6\x97\xa0\xe6\xb3\x95处理方式
查看字符编码: import chardet response = chardet.detect(b'\xe5\xbd\x93\xe5\x89\x8d\xe7\x9b\xae\xe5\xbd\x95\xe4\xb8\x8b\xe6\x89\x80\xe6\x9c\x89\xe6\x96\x87\xe4\xbb\xb6\xe5\x90\x8d\xe6\xb1\x87\xe6\x80\xbb\xe5\x88\x97\xe8\xa1\xa8') print(response) {'encoding':
-
python3 中文乱码与默认编码格式设定方法
python默认编码格式是utf-8.在python2.7中,可以通过sys.setdefaultencoding('gbk')设定默认编码格式,而在python3.3中sys.setdefaultencoding()这个函数已经没有了.在python3.3中该如何设置内置的默认编码格式啊!急求!!! (类似于"#coding:gbk"这种就不必来说了.能让import sys print(sys.getdefaultencoding())输出"gbk"的大神请进!
-
python3用PyPDF2解析pdf文件,用正则匹配数据方式
我就废话不多说了,大家还是看代码吧! import PyPDF2 import re pdf_file = open('xxx.pdf', mode='rb') read_pdf = PyPDF2.PdfFileReader(pdf_file) # 获取pdf文件的所有页数 number_of_pages = read_pdf.getNumPages() # print('total_page: ', number_of_pages) line_list = [] # 循环遍历每一页 for i
-
浅谈python下含中文字符串正则表达式的编码问题
前言 Python文件默认的编码格式是ascii ,无法识别汉字,因为ascii码中没有中文. 所以py文件中要写中文字符时,一般在开头加 # -*- coding: utf-8 -*- 或者 #coding=utf-8. 这是指定一种编码格式,意味着用该编码存储中文字符(也可以是gbk.gb2312等). 关于测试的几点注意 -------------------------------------------- 注1:代码中有中文,就要在头部指定编码方式,如果用编辑器写代码,还要注意IDE的
-
Python 16进制与中文相互转换的实现方法
Python中编码问题:u'\xe6\x97\xa0\xe5\x90\x8d' 类型的转为utf-8的解决办法 相信小伙伴们遇到过类似这样的问题,python2中各种头疼的转码,类似u'\xe6\x97\xa0\xe5\x90\x8d' 的编码,直接s.decode()是无法解决编码问题.尝试了无数办法,都无法解决. 最终得到完美的解决办法: s = u'\xe6\x97\xa0\xe5\x90\x8d' s2 = s.encode('raw_unicode_escape') print s2
-
python3.6 如何将list存入txt后再读出list的方法
今天遇到一个需求,就是将一个list文件读取后,存入一个txt配置文件.存入时,发现list文件无法直接存入,必须转为str模式. 但在读取txt时,就无法恢复成list类型来读取了(准确地说,即使强行使用list读取,读出来的也是单个的字符). 查了查资料,发现json.loads和json.dumps这对兄弟提供了一个很好的办法.下面看代码 #python 3.6 #!/usr/bin/env python # -*- coding:utf-8 -*- __author__ = 'BH8AN
-
python中urllib.unquote乱码的原因与解决方法
发现问题 Python中的urllib模块用来处理url相关的操作,unquote方法对应javascript中的urldecode方法,它对url进行解码,把类似"%xx"的字符替换成单个字符,例如:"%E6%B3%95%E5%9B%BD%E7%BA%A2%E9%85%92"解码后会转换成"法国红酒",但是使用过程中,如果姿势不对,最终转换出来的字符会是乱码"法国红é-". 笔者在一个真实的Tornado应用中就
-
python3序列化与反序列化用法实例
本文实例讲述了python3序列化与反序列化用法.分享给大家供大家参考.具体如下: #coding=utf-8 import pickle aa={} aa["title"]="我是好人" aa["num"]=2 t=pickle.dumps(aa)#序列化这个字典 print(t) f=pickle.loads(t)#反序列化,还原原来的状态 print(f) 运行结果如下: (dp0 S'num' p1 I2 sS'title' p2 S'\
-
Python3中编码与解码之Unicode与bytes的讲解
今天玩Python爬虫,下载一个网页,然后把所有内容写入一个txt文件中,出现错误: TypeError: write() argument must be str, not bytes AttributeError: 'URLError' object has no attribute 'code' UnicodeEncodeError: 'gbk' codec can't encode character '\xa0' inposition 5747: illegal multibyte s
-
Python2.x中文乱码问题解决方法
Python中乱码问题是一个很头痛的问题. 在Python3中,对中文进行了全面的支持,但在Python2.x中需要进行相关的设置才能使用中文.否则会出现乱码 [问题原因] 在Python2.x中主要是字符编码的问题,处理不好的话,会导致乱码.Python默认采取的ASCII编码,字母.标点和其他字符只使用一个字节来表示,但对于中文字符来说,一个字节满足不了需求. 复制代码 代码如下: >>> import sys >>> sys.getdefaultencoding