pandas groupby + unstack的使用说明
概述
groupby()可以根据DataFrame中的某一列或者多列内容进行分组聚合,当DataFrame聚合后为两列索引时,可以使用unstack()将聚合的两列中一列值调整为行索引,另一列的值调整为列索引。
代码说明
test_df = pd.DataFrame({ 'col_1':['a', 'a', 'b', 'a', 'a', 'b', 'c', 'a', 'c'],
'col_2':['d', 'd', 'd', 'e', 'f', 'e', 'd', 'f', 'f'],
'col_3':[ 1, 2, 3, 1, 4, 5, 6, 4, 5]})
1.仅对数据进行分组聚合
df1=test_df.groupby(['col_1', 'col_2']).count()
df1:
col_3
col_1 col_2
a d 2
e 1
f 2
b d 1
e 1
c d 1
f 1
df.index:
MultiIndex(levels=[['a', 'b', 'c'], ['d', 'e', 'f']],
labels=[[0, 0, 0, 1, 1, 2, 2], [0, 1, 2, 0, 1, 0, 2]],
names=['col_1', 'col_2'])
df1.columns:
Index(['col_3'], dtype='object')
2.对分组聚合后的数据进行unstack
df2=test_df.groupby(['col_1', 'col_2']).count().unstack()
df2:
col_3
col_2 d e f
col_1
a 2.0 1.0 2.0
b 1.0 1.0 NaN
c 1.0 NaN 1.0
df2.index:
Index(['a', 'b', 'c'], dtype='object', name='col_1')
df2.columns:
MultiIndex(levels=[['col_3'], ['d', 'e', 'f']],
labels=[[0, 0, 0], [0, 1, 2]],
names=[None, 'col_2'])
3.对分组聚合后的某列进行unstack
df3=test_df.groupby(['col_1', 'col_2']).count()['col_3'].unstack() df3: col_2 d e f col_1 a 2.0 1.0 2.0 b 1.0 1.0 NaN c 1.0 NaN 1.0 df.index: Index(['a', 'b', 'c'], dtype='object', name='col_1') de.columns: Index(['d', 'e', 'f'], dtype='object', name='col_2')
补充:pandas中pivot()方法和groupby()方法的说明和对比
pandas中有两个很有用的方法,pivot()或者pivot_table()和groupby(),其中pivot()方法是指定相应的列分别作为行标签和列标签,并指定相应的列作为值,然后重新生成一个新的DataFrame对象,这样的好处是使得数据更加的直观和容易分析,俗称数据透视;而groupby()方法是指定相应的列进行分组,把这列中具有相同值的行分为同一组,这个过程称为分组,返回一个groupby对象,一般的,分组之后会伴有聚合运算,即对每组进行需要的聚合运算(比如求和求积等)。
因此,pivot()方法是为了让数据重新排列组合,使其更直观,数据透视;而groupby()方法则是对数据进行分组聚合运算;两者实际上功能特点很明显,并没有什么可比性,只是在利用这两种方法时,原数据的结构是有些相似的,仅此而已;anyway,本文硬是把两者放在一起比较确实有些牵强的。
但实际上本文的目的是通过使用这两种不同的方法达成一个相同的目的,由此明晰两种方法的用法和优劣势,并由此更好的掌握它们。
首先我们构造一个DataFrame对象,如图。
其中reindex方法是为了调换name和date两列的顺序。
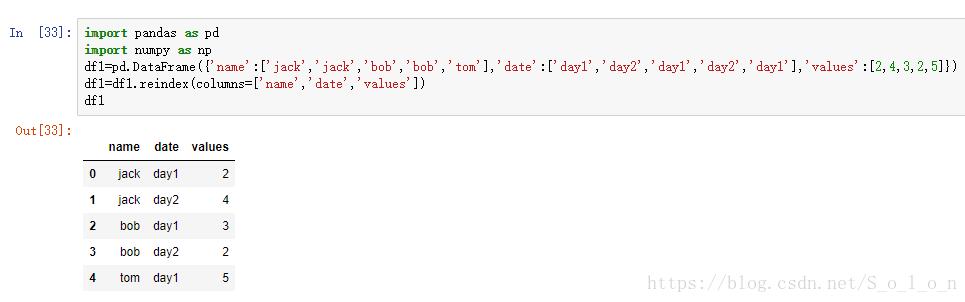
现在我们有一个目标是去计算每个人在所有日期的总的value,对此,我们先用pivot()方法看看如何实现。
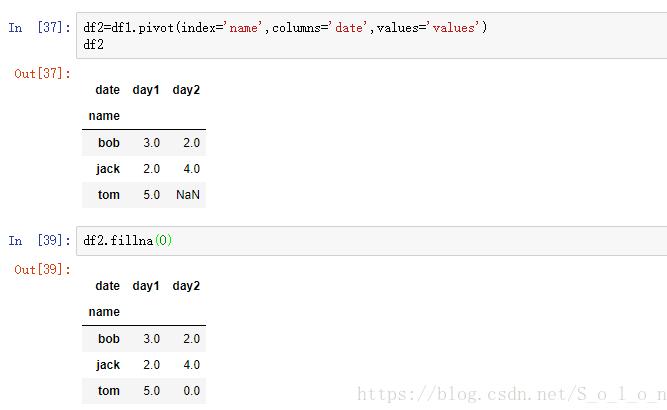
如下图,首先对df1利用pivot()方法进行重新排列,具体的参数如图,以name为行标签,date为列标签,values为值,其中在原表中没有对应值,则显示NaN。
经过重新排列,我们可以很直观的看出在原表中name和data两列对应值的对应关系,这更有助于我们分析name、date、values这三列的关系,这才是pivot()方法的主要功能。
当然,对于我们最初的目标,我们可以通过对NaN填充0值,然后再对每列求和即可,即df2.sum(axis=1)。
然后,我们再用groupby()方法来实现我们的目标,具体代码如图。
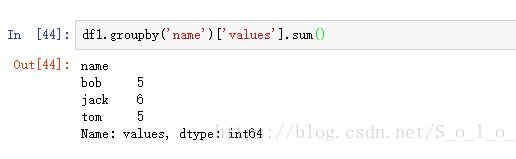
这里,我们只要对name列进行分组,得到分组后的groupby对象,然后再对values列进行求和,最后就会返回每个名字对应的总的value。
通过以上论述,可知要达成我们的最初的目标,显然groupby()方法要简单的多,这当然是由于pivot()和grouby()的功能特性所决定的,因为这本来就是groupby()所擅长的。
这里用pivot()来实现我们的目标虽然是可以,但是明显大材小用了。
我们通过这些例子就是想说明两者的用法,以及不同的功能特点,以此更好的掌握和理解这两种方法。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
pandas之分组groupby()的使用整理与总结
前言 在使用pandas的时候,有些场景需要对数据内部进行分组处理,如一组全校学生成绩的数据,我们想通过班级进行分组,或者再对班级分组后的性别进行分组来进行分析,这时通过pandas下的groupby()函数就可以解决.在使用pandas进行数据分析时,groupby()函数将会是一个数据分析辅助的利器. groupby的作用可以参考 超好用的 pandas 之 groupby 中作者的插图进行直观的理解: 准备 读入的数据是一段学生信息的数据,下面将以这个数据为例进行整理grouby()函数的
-

pandas数据分组groupby()和统计函数agg()的使用
数据分组 使用 groupby() 方法进行分组 group.size()查看分组后每组的数量 group.groups 查看分组情况 group.get_group('名字') 根据分组后的名字选择分组数据 准备数据 # 一个Series其实就是一条数据,Series方法的第一个参数是data,第二个参数是index(索引),如果没有传值会使用默认值(0-N) # index参数是我们自定义的索引值,注意:参数值的个数一定要相同. # 在创建Series时数据并不一定要是列表,也可以将一个字典
-
Pandas之groupby( )用法笔记小结
groupby官方解释 DataFrame.groupby(by=None, axis=0, level=None, as_index=True, sort=True, group_keys=True, squeeze=False, **kwargs) Group series using mapper (dict or key function, apply given function to group, return result as series) or by a series of
-
pandas groupby + unstack的使用说明
概述 groupby()可以根据DataFrame中的某一列或者多列内容进行分组聚合,当DataFrame聚合后为两列索引时,可以使用unstack()将聚合的两列中一列值调整为行索引,另一列的值调整为列索引. 代码说明 test_df = pd.DataFrame({ 'col_1':['a', 'a', 'b', 'a', 'a', 'b', 'c', 'a', 'c'], 'col_2':['d', 'd', 'd', 'e', 'f', 'e', 'd', 'f', 'f'], 'col
-
pandas groupby 分组取每组的前几行记录方法
直接上例子. import pandas as pd df = pd.DataFrame({'class':['a','a','b','b','a','a','b','c','c'],'score':[3,5,6,7,8,9,10,11,14]}) df: class score 0 a 3 1 a 5 2 b 6 3 b 7 4 a 8 5 a 9 6 b 10 7 c 11 8 c 14 df.sort_values(['class','score'],ascending=[1,0],inp
-
Pandas GroupBy对象 索引与迭代方法
如下所示: import pandas as pd df = pd.DataFrame({'性别' : ['男', '女', '男', '女', '男', '女', '男', '男'], '成绩' : ['优秀', '优秀', '及格', '差', '及格', '及格', '优秀', '差'], '年龄' : [15,14,15,12,13,14,15,16]}) GroupBy=df.groupby("性别") GroupBy.iter() GroupBy对象是一个迭代对象,每次迭代
-
pandas groupby 用法实例详解
目录 1.分组groupby 2.groupby的数据结构 4.transform的用法 项目github地址:bitcarmanlee easy-algorithm-interview-and-practice欢迎大家star,留言,一起学习进步 1.分组groupby 在日常数据分析过程中,经常有分组的需求.具体来说,就是根据一个或者多个字段,将数据划分为不同的组,然后进行进一步分析,比如求分组的数量,分组内的最大值最小值平均值等.在sql中,就是大名鼎鼎的groupby操作.pandas中
-
Python pandas轴旋转stack和unstack的使用说明
摘要 前面给大家分享了pandas做数据合并的两篇[pandas.merge]和[pandas.cancat]的用法.今天这篇主要讲的是pandas的DataFrame的轴旋转操作,stack和unstack的用法. 首先,要知道以下五点: 1.stack:将数据的列"旋转"为行 2.unstack:将数据的行"旋转"为列 3.stack和unstack默认操作为最内层 4.stack和unstack默认旋转轴的级别将会成果结果中的最低级别(最内层) 5.stack
-
Pandas groupby apply agg 的区别 运行自定义函数说明
agg 方法将一个函数使用在一个数列上,然后返回一个标量的值.也就是说agg每次传入的是一列数据,对其聚合后返回标量. 对一列使用三个函数: 对不同列使用不同函数 apply 是一个更一般化的方法:将一个数据分拆-应用-汇总.而apply会将当前分组后的数据一起传入,可以返回多维数据. 实例: 1.数据如下: lawsuit2[['EID','LAWAMOUNT','LAWDATE']] 2.groupby后应用apply传入函数数据如下: lawsuit2[['EID','LAWAMOUNT'
-
pandas groupby分组对象的组内排序解决方案
问题: 根据数据某列进行分组,选择其中另一列大小top-K的的所在行数据 解析: 求解思路很清晰,即先用groupby对数据进行分组,然后再根据分组后的某一列进行排序,选择排序结果后的top-K结果 案例: 取一下dataframe中B列各对象中C值最高所在的行 df = pd.DataFrame({"A": [2, 3, 5, 4], "B": ['a', 'b', 'b', 'a'], "C": [200801, 200902, 200704
-
Pandas高级教程之Pandas中的GroupBy操作
目录 简介 分割数据 多index get_group dropna groups属性 index的层级 group的遍历 聚合操作 通用聚合方法 可以同时指定多个聚合方法: NamedAgg 不同的列指定不同的聚合方法 转换操作 过滤操作 Apply操作 简介 pandas中的DF数据类型可以像数据库表格一样进行groupby操作.通常来说groupby操作可以分为三部分:分割数据,应用变换和和合并数据. 本文将会详细讲解Pandas中的groupby操作. 分割数据 分割数据的目的是将DF分