Pytorch - TORCH.NN.INIT 参数初始化的操作
路径:
https://pytorch.org/docs/master/nn.init.html#nn-init-doc
初始化函数:torch.nn.init
# -*- coding: utf-8 -*-
"""
Created on 2019
@author: fancp
"""
import torch
import torch.nn as nn
w = torch.empty(3,5)
#1.均匀分布 - u(a,b)
#torch.nn.init.uniform_(tensor, a=0.0, b=1.0)
print(nn.init.uniform_(w))
# =============================================================================
# tensor([[0.9160, 0.1832, 0.5278, 0.5480, 0.6754],
# [0.9509, 0.8325, 0.9149, 0.8192, 0.9950],
# [0.4847, 0.4148, 0.8161, 0.0948, 0.3787]])
# =============================================================================
#2.正态分布 - N(mean, std)
#torch.nn.init.normal_(tensor, mean=0.0, std=1.0)
print(nn.init.normal_(w))
# =============================================================================
# tensor([[ 0.4388, 0.3083, -0.6803, -1.1476, -0.6084],
# [ 0.5148, -0.2876, -1.2222, 0.6990, -0.1595],
# [-2.0834, -1.6288, 0.5057, -0.5754, 0.3052]])
# =============================================================================
#3.常数 - 固定值 val
#torch.nn.init.constant_(tensor, val)
print(nn.init.constant_(w, 0.3))
# =============================================================================
# tensor([[0.3000, 0.3000, 0.3000, 0.3000, 0.3000],
# [0.3000, 0.3000, 0.3000, 0.3000, 0.3000],
# [0.3000, 0.3000, 0.3000, 0.3000, 0.3000]])
# =============================================================================
#4.全1分布
#torch.nn.init.ones_(tensor)
print(nn.init.ones_(w))
# =============================================================================
# tensor([[1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1.],
# [1., 1., 1., 1., 1.]])
# =============================================================================
#5.全0分布
#torch.nn.init.zeros_(tensor)
print(nn.init.zeros_(w))
# =============================================================================
# tensor([[0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.],
# [0., 0., 0., 0., 0.]])
# =============================================================================
#6.对角线为 1,其它为 0
#torch.nn.init.eye_(tensor)
print(nn.init.eye_(w))
# =============================================================================
# tensor([[1., 0., 0., 0., 0.],
# [0., 1., 0., 0., 0.],
# [0., 0., 1., 0., 0.]])
# =============================================================================
#7.xavier_uniform 初始化
#torch.nn.init.xavier_uniform_(tensor, gain=1.0)
#From - Understanding the difficulty of training deep feedforward neural networks - Bengio 2010
print(nn.init.xavier_uniform_(w, gain=nn.init.calculate_gain('relu')))
# =============================================================================
# tensor([[-0.1270, 0.3963, 0.9531, -0.2949, 0.8294],
# [-0.9759, -0.6335, 0.9299, -1.0988, -0.1496],
# [-0.7224, 0.2181, -1.1219, 0.8629, -0.8825]])
# =============================================================================
#8.xavier_normal 初始化
#torch.nn.init.xavier_normal_(tensor, gain=1.0)
print(nn.init.xavier_normal_(w))
# =============================================================================
# tensor([[ 1.0463, 0.1275, -0.3752, 0.1858, 1.1008],
# [-0.5560, 0.2837, 0.1000, -0.5835, 0.7886],
# [-0.2417, 0.1763, -0.7495, 0.4677, -0.1185]])
# =============================================================================
#9.kaiming_uniform 初始化
#torch.nn.init.kaiming_uniform_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
#From - Delving deep into rectifiers: Surpassing human-level performance on ImageNet classification - HeKaiming 2015
print(nn.init.kaiming_uniform_(w, mode='fan_in', nonlinearity='relu'))
# =============================================================================
# tensor([[-0.7712, 0.9344, 0.8304, 0.2367, 0.0478],
# [-0.6139, -0.3916, -0.0835, 0.5975, 0.1717],
# [ 0.3197, -0.9825, -0.5380, -1.0033, -0.3701]])
# =============================================================================
#10.kaiming_normal 初始化
#torch.nn.init.kaiming_normal_(tensor, a=0, mode='fan_in', nonlinearity='leaky_relu')
print(nn.init.kaiming_normal_(w, mode='fan_out', nonlinearity='relu'))
# =============================================================================
# tensor([[-0.0210, 0.5532, -0.8647, 0.9813, 0.0466],
# [ 0.7713, -1.0418, 0.7264, 0.5547, 0.7403],
# [-0.8471, -1.7371, 1.3333, 0.0395, 1.0787]])
# =============================================================================
#11.正交矩阵 - (semi)orthogonal matrix
#torch.nn.init.orthogonal_(tensor, gain=1)
#From - Exact solutions to the nonlinear dynamics of learning in deep linear neural networks - Saxe 2013
print(nn.init.orthogonal_(w))
# =============================================================================
# tensor([[-0.0346, -0.7607, -0.0428, 0.4771, 0.4366],
# [-0.0412, -0.0836, 0.9847, 0.0703, -0.1293],
# [-0.6639, 0.4551, 0.0731, 0.1674, 0.5646]])
# =============================================================================
#12.稀疏矩阵 - sparse matrix
#torch.nn.init.sparse_(tensor, sparsity, std=0.01)
#From - Deep learning via Hessian-free optimization - Martens 2010
print(nn.init.sparse_(w, sparsity=0.1))
# =============================================================================
# tensor([[ 0.0000, 0.0000, -0.0077, 0.0000, -0.0046],
# [ 0.0152, 0.0030, 0.0000, -0.0029, 0.0005],
# [ 0.0199, 0.0132, -0.0088, 0.0060, 0.0000]])
# =============================================================================
补充:【pytorch参数初始化】 pytorch默认参数初始化以及自定义参数初始化
本文用两个问题来引入
1.pytorch自定义网络结构不进行参数初始化会怎样,参数值是随机的吗?
2.如何自定义参数初始化?
先回答第一个问题
在pytorch中,有自己默认初始化参数方式,所以在你定义好网络结构以后,不进行参数初始化也是可以的。
1.Conv2d继承自_ConvNd,在_ConvNd中,可以看到默认参数就是进行初始化的,如下图所示
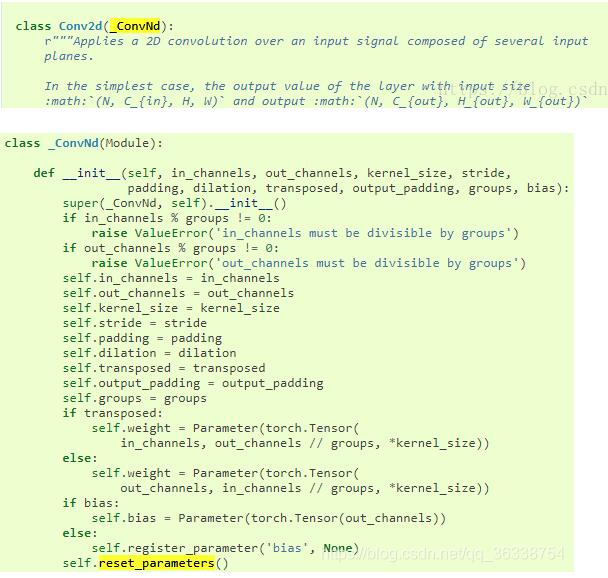
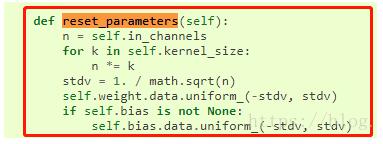
2.torch.nn.BatchNorm2d也一样有默认初始化的方式
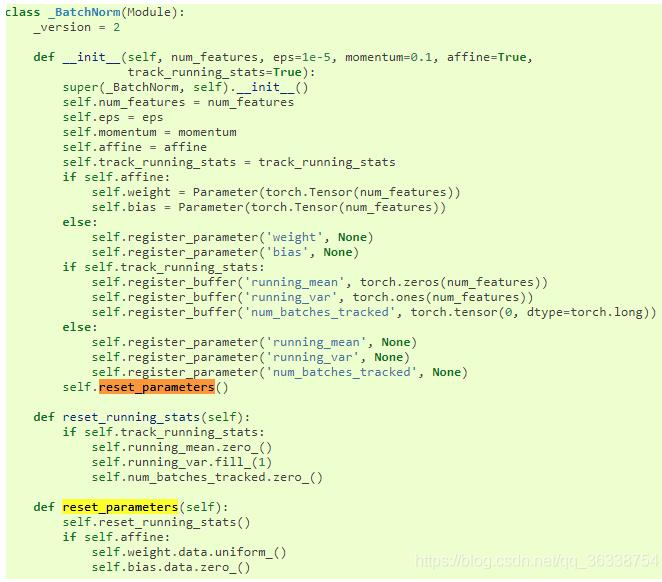
3.torch.nn.Linear也如此

现在来回答第二个问题。
pytorch中对神经网络模型中的参数进行初始化方法如下:
from torch.nn import init
#define the initial function to init the layer's parameters for the network
def weigth_init(m):
if isinstance(m, nn.Conv2d):
init.xavier_uniform_(m.weight.data)
init.constant_(m.bias.data,0.1)
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(1)
m.bias.data.zero_()
elif isinstance(m, nn.Linear):
m.weight.data.normal_(0,0.01)
m.bias.data.zero_()
首先定义了一个初始化函数,接着进行调用就ok了,不过要先把网络模型实例化:
#Define Network model = Net(args.input_channel,args.output_channel) model.apply(weigth_init)
此上就完成了对模型中训练参数的初始化。
在知乎上也有看到一个类似的版本,也相应的贴上来作为参考了:
def initNetParams(net):
'''Init net parameters.'''
for m in net.modules():
if isinstance(m, nn.Conv2d):
init.xavier_uniform(m.weight)
if m.bias:
init.constant(m.bias, 0)
elif isinstance(m, nn.BatchNorm2d):
init.constant(m.weight, 1)
init.constant(m.bias, 0)
elif isinstance(m, nn.Linear):
init.normal(m.weight, std=1e-3)
if m.bias:
init.constant(m.bias, 0)
initNetParams(net)
再说一下关于模型的保存及加载
1.保存有两种方式,第一种是保存模型的整个结构信息和参数,第二种是只保存模型的参数
#保存整个网络模型及参数 torch.save(net, 'net.pkl') #仅保存模型参数 torch.save(net.state_dict(), 'net_params.pkl')
2.加载对应保存的两种网络
# 保存和加载整个模型
torch.save(model_object, 'model.pth')
model = torch.load('model.pth')
# 仅保存和加载模型参数
torch.save(model_object.state_dict(), 'params.pth')
model_object.load_state_dict(torch.load('params.pth'))
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
对Pytorch神经网络初始化kaiming分布详解
函数的增益值 torch.nn.init.calculate_gain(nonlinearity, param=None) 提供了对非线性函数增益值的计算. 增益值gain是一个比例值,来调控输入数量级和输出数量级之间的关系. fan_in和fan_out pytorch计算fan_in和fan_out的源码 def _calculate_fan_in_and_fan_out(tensor): dimensions = tensor.ndimension() if dimensions < 2:
-
pytorch自定义初始化权重的方法
在常见的pytorch代码中,我们见到的初始化方式都是调用init类对每层所有参数进行初始化.但是,有时我们有些特殊需求,比如用某一层的权重取优化其它层,或者手动指定某些权重的初始值. 核心思想就是构造和该层权重同一尺寸的矩阵去对该层权重赋值.但是,值得注意的是,pytorch中各层权重的数据类型是nn.Parameter,而不是Tensor或者Variable. import torch import torch.nn as nn import torch.optim as optim imp
-

python PyTorch参数初始化和Finetune
前言 这篇文章算是论坛PyTorch Forums关于参数初始化和finetune的总结,也是我在写代码中用的算是"最佳实践"吧.最后希望大家没事多逛逛论坛,有很多高质量的回答. 参数初始化 参数的初始化其实就是对参数赋值.而我们需要学习的参数其实都是Variable,它其实是对Tensor的封装,同时提供了data,grad等借口,这就意味着我们可以直接对这些参数进行操作赋值了.这就是PyTorch简洁高效所在. 所以我们可以进行如下操作进行初始化,当然其实有其他的方法,但是这种方法
-
Pytorch - TORCH.NN.INIT 参数初始化的操作
路径: https://pytorch.org/docs/master/nn.init.html#nn-init-doc 初始化函数:torch.nn.init # -*- coding: utf-8 -*- """ Created on 2019 @author: fancp """ import torch import torch.nn as nn w = torch.empty(3,5) #1.均匀分布 - u(a,b) #torch.n
-
pytorch torch.nn.AdaptiveAvgPool2d()自适应平均池化函数详解
如题:只需要给定输出特征图的大小就好,其中通道数前后不发生变化.具体如下: AdaptiveAvgPool2d CLASStorch.nn.AdaptiveAvgPool2d(output_size)[SOURCE] Applies a 2D adaptive average pooling over an input signal composed of several input planes. The output is of size H x W, for any input size.
-
PyTorch中torch.nn.Linear实例详解
目录 前言 1. nn.Linear的原理: 2. nn.Linear的使用: 3. nn.Linear的源码定义: 补充:许多细节需要声明 总结 前言 在学习transformer时,遇到过非常频繁的nn.Linear()函数,这里对nn.Linear进行一个详解.参考:https://pytorch.org/docs/stable/_modules/torch/nn/modules/linear.html 1. nn.Linear的原理: 从名称就可以看出来,nn.Linear表示的是线性变
-
pytorch中的torch.nn.Conv2d()函数图文详解
目录 一.官方文档介绍 二.torch.nn.Conv2d()函数详解 参数dilation——扩张卷积(也叫空洞卷积) 参数groups——分组卷积 总结 一.官方文档介绍 官网 nn.Conv2d:对由多个输入平面组成的输入信号进行二维卷积 二.torch.nn.Conv2d()函数详解 参数详解 torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1,
-
PyTorch中torch.nn.functional.cosine_similarity使用详解
目录 概述 按照dim=0求余弦相似: 按照dim=1求余弦相似: 总结 概述 根据官网文档的描述,其中 dim表示沿着对应的维度计算余弦相似.那么怎么理解呢? 首先,先介绍下所谓的dim: a = torch.tensor([[ [1, 2], [3, 4] ], [ [5, 6], [7, 8] ] ], dtype=torch.float) print(a.shape) """ [ [ [1, 2], [3, 4] ], [ [5, 6], [7, 8] ] ] &qu
-
PyTorch 实现L2正则化以及Dropout的操作
了解知道Dropout原理 如果要提高神经网络的表达或分类能力,最直接的方法就是采用更深的网络和更多的神经元,复杂的网络也意味着更加容易过拟合. 于是就有了Dropout,大部分实验表明其具有一定的防止过拟合的能力. 用代码实现Dropout Dropout的numpy实现 PyTorch中实现dropout import torch.nn.functional as F import torch.nn.init as init import torch from torch.autograd
-
PyTorch中的参数类torch.nn.Parameter()详解
目录 前言 分析 ViT中nn.Parameter()的实验 其他解释 参考: 总结 前言 今天来聊一下PyTorch中的torch.nn.Parameter()这个函数,笔者第一次见的时候也是大概能理解函数的用途,但是具体实现原理细节也是云里雾里,在参考了几篇博文,做过几个实验之后算是清晰了,本文在记录的同时希望给后来人一个参考,欢迎留言讨论. 分析 先看其名,parameter,中文意为参数.我们知道,使用PyTorch训练神经网络时,本质上就是训练一个函数,这个函数输入一个数据(如CV中输
-
Pytorch中torch.nn.Softmax的dim参数用法说明
Pytorch中torch.nn.Softmax的dim参数使用含义 涉及到多维tensor时,对softmax的参数dim总是很迷,下面用一个例子说明 import torch.nn as nn m = nn.Softmax(dim=0) n = nn.Softmax(dim=1) k = nn.Softmax(dim=2) input = torch.randn(2, 2, 3) print(input) print(m(input)) print(n(input)) print(k(inp
-
PyTorch基础之torch.nn.Conv2d中自定义权重问题
目录 torch.nn.Conv2d中自定义权重 torch.nn.Conv2d()用法讲解 用法 参数 相关形状 总结 torch.nn.Conv2d中自定义权重 torch.nn.Conv2d函数调用后会自动初始化weight和bias,本文主要涉及 如何自定义weight和bias为需要的数均分布类型: torch.nn.Conv2d.weight.data以及torch.nn.Conv2d.bias.data为torch.tensor类型,因此只要对这两个属性进行操作即可. [sampl