R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解
R语言dplyr包的数据整理、分析函数用法文章连载NO.01
在日常数据处理过程中难免会遇到些难处理的,选取更适合的函数分割、筛选、合并等实在是大快人心!
利用dplyr包中的函数更高效的数据清洗、数据分析,及为后续数据建模创造环境;本篇涉及到的函数为filter、filter_all()、filter_if()、filter_at()、mutate、group_by、select、summarise。
1、数据筛选函数:
#可使用filter()函数筛选/查找特定条件的行或者样本
#filter(.data=,condition_1,condition_2)#将返回相匹配的数据
#同时可以多条件匹配multiple condition,当采用多条件匹配时可直接condition1,condition2或者condition1&condition2
#其他逻辑表达还有:==,>,>=等,&,|,!,xor(),is.na,between,near
#filter延展的相关函数filter_all()、filter_if()、filter_at()
#以iris数据集为例:
filter(.data=iris,Sepal.Length>3,Sepal.Width<3.5) filter(.data=iris,Sepal.Length>3,Species=="virginica")
输出情况: 输出情况:


#要使用filter_all()、filter_if()、filter_at()需要先去掉Species列(非数值型列)
iris_data<-iris%>% select(-Species)
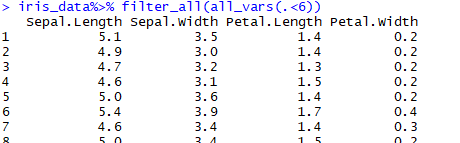
#筛选所有属性小于6的行
iris_data%>% filter_all(all_vars(.<6))
部分输出情况:
#筛选任意一个属性大于3的行
iris_data%>% filter_all(any_vars(.>3))
#筛选以sep开头的属性任一大于3的行
iris_data%>% filter_at(vars(starts_with("Sep")), any_vars(. >3))
#R中自带数据集mtcars,筛选任意一个属性大于150的行
filter_all(mtcars, any_vars(. > 150))
#筛选以d开头的属性任一可被2整除的行
filter_at(mtcars, vars(starts_with("d")), any_vars((. %% 2) == 0))
2、数据分组、汇总函数group_by、summarise
其他延展函数 group_by_all、group_by_if、group_by_at(将在后续文章中解析)
group_by函数按照某个变量分组,对于数据集本身并不会发生什么变化,只有在与mutate(), arrange() 和 summarise() 函数结合应用的时候会体现出它的优越性,将会对这些 tbl 类数据执行分组操作 (R语言泛型函数的优越性).
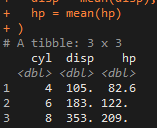
mtcars_cyl <- mtcars %>% group_by(cyl) mtcars_cyl %>% summarise( disp = mean(disp), hp = mean(hp) )
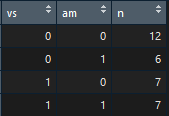
mtcars_vs_am <- mtcars %>% group_by(vs, am) mtcars_vs <- mtcars_vs_am %>% summarise(n = n())
3、新增列函数mutate,在数据集的基础上新增列,不对原数据作更改
可用的相关参数、逻辑:
• +, - 等等
• log()
• lead(), lag()
• dense_rank(), min_rank(), percent_rank(), row_number(), cume_dist(), ntile()
• cumsum(), cummean(), cummin(), cummax(), cumany(), cumall()
• na_if(), coalesce()
• if_else(), recode(), case_when()
相关延展函数:transmute、mutate_all、mutate_if、mutate_at(后期文章分享)
mtcars %>% as_tibble() %>% mutate( cyl2 = cyl*3, cyl4 = cyl2+2 )

到此这篇关于R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解的文章就介绍到这了,更多相关R语言dplyr包数据处理函数内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

R语言利用loess如何去除某个变量对数据的影响详解
R语言介绍 R语言是用于统计分析,图形表示和报告的编程语言和软件环境. R语言由Ross Ihaka和Robert Gentleman在新西兰奥克兰大学创建,目前由R语言开发核心团队开发. R语言的核心是解释计算机语言,其允许分支和循环以及使用函数的模块化编程. R语言允许与以C,C ++,.Net,Python或FORTRAN语言编写的过程集成以提高效率. R语言在GNU通用公共许可证下免费提供,并为各种操作系统(如Linux,Windows和Mac)提供预编译的二进制版本. R是一个在GNU
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
详解R语言中的PCA分析与可视化
1. 常用术语 (1)标准化(Scale) 如果不对数据进行scale处理,本身数值大的基因对主成分的贡献会大.如果关注的是变量的相对大小对样品分类的贡献,则应SCALE,以防数值高的变量导入的大方差引入的偏见.但是定标(scale)可能会有一些负面效果,因为定标后变量之间的权重就是变得相同.如果我们的变量中有噪音的话,我们就在无形中把噪音和信息的权重变得相同,但PCA本身无法区分信号和噪音.在这样的情形下,我们就不必做定标. (2)特征值 (eigen value) 特征值与特征向量均为矩阵分
-
R语言 vs Python对比:数据分析哪家强?
什么是R语言? R语言,一种自由软件编程语言与操作环境,主要用于统计分析.绘图.数据挖掘.R本来是由来自新西兰奥克兰大学的罗斯·伊哈卡和罗伯特·杰特曼开发(也因此称为R),现在由"R开发核心团队"负责开发.R基于S语言的一个GNU计划项目,所以也可以当作S语言的一种实现,通常用S语言编写的代码都可以不作修改的在R环境下运行.R的语法是来自Scheme. R的源代码可自由下载使用,亦有已编译的可执行文件版本可以下载,可在多种平台下运行,包括UNIX(也包括FreeBSD和Linux).W
-
详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
R语言dplyr包之高效数据处理函数(filter、group_by、mutate、summarise)详解
R语言dplyr包的数据整理.分析函数用法文章连载NO.01 在日常数据处理过程中难免会遇到些难处理的,选取更适合的函数分割.筛选.合并等实在是大快人心! 利用dplyr包中的函数更高效的数据清洗.数据分析,及为后续数据建模创造环境:本篇涉及到的函数为filter.filter_all().filter_if().filter_at().mutate.group_by.select.summarise. 1.数据筛选函数: #可使用filter()函数筛选/查找特定条件的行或者样本 #filte
-
R语言glmnet包lasso回归中分类变量的处理图文详解
我们在既往文章<手把手教你使用R语言做LASSO 回归>中介绍了glmnet包进行lasso回归,后台不少粉丝发信息向我问到分类变量处理的问题,我后面查了一下资料之前文章分类变量没有处理,非常抱歉.现在来重新聊一聊分类变量的处理. 我们导入glmnet包的时候可以看到,还需要导入一个Matrix包,说明这个矩阵包很重要 按照glmnet包的原文如下: 就是告诉我们,除了Cox Model外,其他的表达都支持矩阵形式,在Cox Model的介绍中,函数样式为 说明我们应该把其他变量变为矩阵的形式
-
R语言中矩阵matrix和数据框data.frame的使用详解
本文主要介绍了R语言中矩阵matrix和数据框data.frame的一些使用,分享给大家,具体如下: "一,矩阵matrix" "创建向量" x_1=c(1,2,3) x_1=c(1:3) x_2=1:3 typeof(x_1)==typeof(x_2)#查看目标类型 x_3=seq(1,6,length=3)#将1--6分为3个数 a<-rep(1:3,each=3) #1到3依次重复 c<-rep(1:3,times=3) #1到3重复3次 d<
-
R语言逻辑回归、ROC曲线与十折交叉验证详解
自己整理编写的逻辑回归模板,作为学习笔记记录分享.数据集用的是14个自变量Xi,一个因变量Y的australian数据集. 1. 测试集和训练集3.7分组 australian <- read.csv("australian.csv",as.is = T,sep=",",header=TRUE) #读取行数 N = length(australian$Y) #ind=1的是0.7概率出现的行,ind=2是0.3概率出现的行 ind=sample(2,N,rep
-
Go语言ORM包中使用worm构造查询条件的实例详解
目录 构造查询条件 main函数 数据库表与数据模型 通过ID来查询数据 通过Where函数来查询数据 XXXIf查询 in.not in查询 嵌套查询语句 Limit与Offset orderby查询 构造查询条件 worm是一款方便易用的Go语言ORM库.worm支Model方式(持结构体字段映射).原生SQL以及SQLBuilder三种模式来操作数据库,并且Model方式.原生SQL以及SQLBuilder可混合使用. Model方式.SQL builder支持链式API,可使用Where
-
详解R语言caret包trainControl函数
目录 trainControl参数详解 源码 参数详解 示例 trainControl参数详解 源码 caret::trainControl <- function (method = "boot", number = ifelse(grepl("cv", method), 10, 25), repeats = ifelse(grepl("[d_]cv$", method), 1, NA), p = 0.75, search = "
-
R语言关于“包”的知识点总结
R语言的包是R函数,编译代码和样本数据的集合. 它们存储在R语言环境中名为"library"的目录下. 默认情况下,R语言在安装期间安装一组软件包. 随后添加更多包,当它们用于某些特定目的时. 当我们启动R语言控制台时,默认情况下只有默认包可用. 已经安装的其他软件包必须显式加载以供将要使用它们的R语言程序使用. 所有可用的R语言包都列在R语言的包. 下面是用于检查,验证和使用R包的命令列表. 检查可用R语言的包 获取包含R包的库位置 .libPaths() 当我们执行上面的代码,它产
-
关于R语言lubridate包处理时间数据的问题
加载包 # install.packages(lubridate) library(lubridate) 第一个函数ymd():解析日期为年月日格式 x <- c("09-01-01", "09-01-02", "09-01-03") ymd(x) [1] "2009-01-01" "2009-01-02" "2009-01-03" x <- c("2009-01-
-
R语言UpSet包实现集合可视化示例详解
目录 前言 一.R包及数据 二.upset()函数 1)基本参数 2)queries参数 3)attribute.plots参数 3.1 添加柱形图和散点图 3.2 添加箱线图 3.3 添加密度曲线图 前言 介绍一个R包UpSetR,专门用来集合可视化,当多集合的韦恩图不容易看的时候,就是它大展身手的时候了. 一.R包及数据 #安装及加载R包 #install.packages("UpSetR") library(UpSetR) #载入数据集 data <- read.csv(&