pandas map(),apply(),applymap()区别解析
基础
以下操作基于python 3.6 windows 10 环境下 通过
将通过实例来演示三者的区别
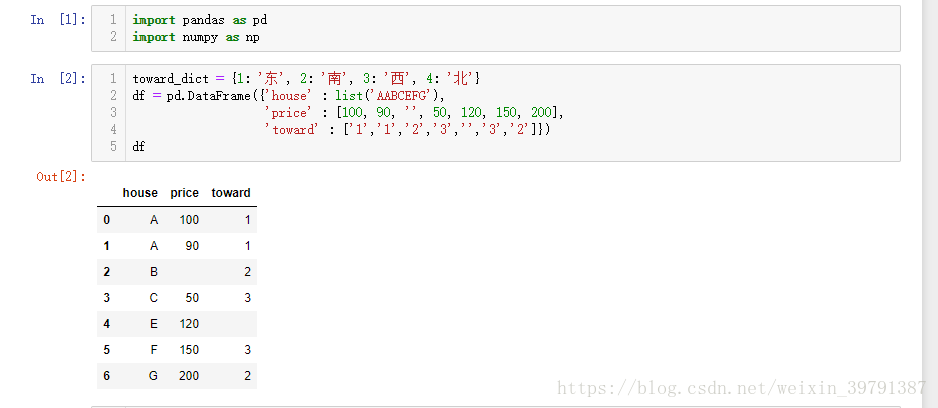
toward_dict = {1: '东', 2: '南', 3: '西', 4: '北'}
df = pd.DataFrame({'house' : list('AABCEFG'),
'price' : [100, 90, '', 50, 120, 150, 200],
'toward' : ['1','1','2','3','','3','2']})
df
map()方法
通过df.(tab)键,发现df的属性列表中有apply() 和 applymap(),但没有map().
map()是python 自带的方法, 可以对df某列内的元素进行操作, 我个人最常用的场景就是有toward_dict的映射关系 ,为df中的toward匹配出结果,
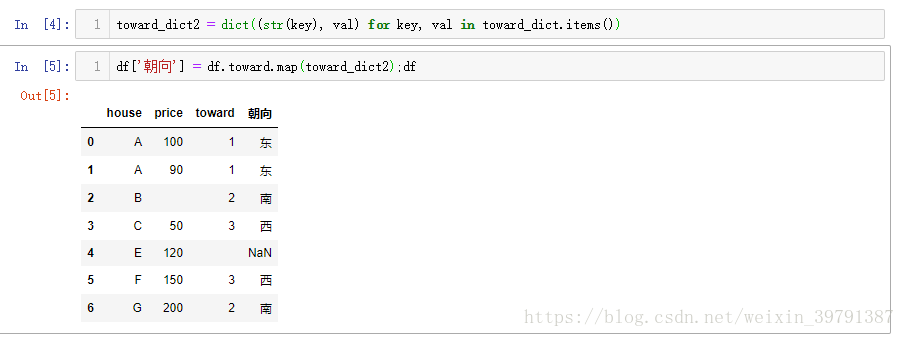
df['朝向'] = df.toward.map(toward_dict);df

结果就是没有匹配出来, why???
因为df.toward这列数字是str型的, toward_dict中的key是int型,下面修正操作下:两个思路:
第一种思路:`toward_dict`的key转换为str型 toward_dict2 = dict((str(key), val) for key, val in toward_dict.items())
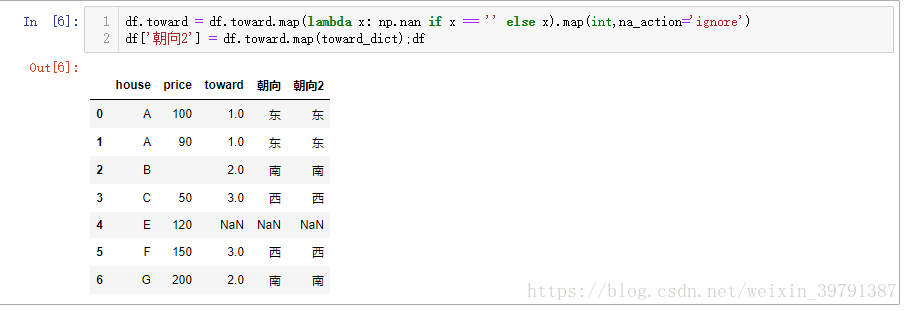
# 第二种思路, 将df.toward转为int型 df.toward = df.toward.map(lambda x: np.nan if x == '' else x).map(int,na_action='ignore') df['朝向2'] = df.toward.map(toward_dict);df
apply() 方法
更新时间: 2018-08-10
我目前的实际工作中使用apply()方法比较少, 所以整理的内容比较简陋, 后续涉及到数据分析方面可能会应用比较多些.
先将上面的测试中的map替换为apply,看看怎么样?
结果报错了, ValueError, 还是老老实实写实际操作例子吧 ?
参考DataFrame.apply官方文档
文档中第一个参数:
func : function
Function to apply to each column or row.
意思即是, 将传入的func应用到每一列或每一行,进行元素级别的运算
第二个参数:
axis : {0 or ‘index', 1 or ‘columns'}, default 0
Axis along which the function is applied:
0 or ‘index': apply function to each column. # 注意这里的解释
1 or ‘columns': apply function to each row.
举例:

这个要特别注意的,
没有继续使用map里的DF, 是因为df.house是字符串, 不能进行np.sum运算,会报错.
2018年12月3日 新增:
最近在工作中使用到了pandas.apply()方法,更新如下:
背景介绍:
一个 df 有三个列需要进行计算,change_type 值 为1和0, 1为涨价,0为降价, price为现价, changed为涨降价的绝对值, 现求:涨降价的比例, 精确到0位,无小数位,
解决思路:
1.最主要的计算是: 涨降价的绝对值/ 原价
2.最主要的难点是: 涨价的原价 = 现价 - 绝对值
降价的原价 = 现价 + 绝对值
伪代码如下: 涨降价比例 = round(changed/(price 加上或减去 changed), 0)
就是我需求的结果了.
解决方案 如下:
以下代码经过win 10 环境 python3.6 版本测试通过
import pandas as pd
df = pd.DataFrame({'change_type' : [1,1,0,0,1,0],
'price' : [100, 90, 50, 120, 150, 200],
'changed' : [10,8,4,11,14,10]})
def get_round(change_type, price, changed_val):
"""
策略设计
"""
if change_type == 0:
return round(changed_val/(price + changed_val) * 100, 2)
elif change_type == 1:
return round(changed_val/(price - changed_val) * 100, 2)
else:
print(f'{change} is not exists')
# 策略实现
df['round'] = df.apply(lambda x: get_round(x['change_type'], x['price'], x['changed']),axis=1)
若有问题, 欢迎指正, 谢谢
applymap()
func : callable
Python function, returns a single value from a single value.
文档很简单, 只有一个参数, 即传入的func方法
样例参考文档吧, 没有比这个更简单了
总结:
map() 方法是pandas.series.map()方法, 对DF中的元素级别的操作, 可以对df的某列或某多列, 可以参考文档
apply(func) 是DF的属性, 对DF中的行数据或列数据应用func操作.
applymap(func) 也是DF的属性, 对整个DF所有元素应用func操作
到此这篇关于pandas map(),apply(),applymap()区别解析的文章就介绍到这了,更多相关pandas map(),apply(),applymap()内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pandas对DataFrame单列/多列进行运算(map, apply, transform, agg)
1.单列运算 在Pandas中,DataFrame的一列就是一个Series, 可以通过map来对一列进行操作: df['col2'] = df['col1'].map(lambda x: x**2) 其中lambda函数中的x代表当前元素.可以使用另外的函数来代替lambda函数,例如: define square(x): return (x ** 2) df['col2'] = df['col1'].map(square) 2.多列运算 apply()会将待处理的对象拆分成多个片段,然后对各
-
pandas使用函数批量处理数据(map、apply、applymap)
前言 在我们对DataFrame对象进行处理时候,下意识的会想到对DataFrame进行遍历,然后将处理后的值再填入DataFrame中,这样做比较繁琐,且处理大量数据时耗时较长.Pandas内置了一个可以对DataFrame批量进行函数处理的工具:map.apply和applymap. 提示:为方便快捷地解决问题,本文仅介绍函数的主要用法,并非全面介绍 一.pandas.Series.map()是什么? 把Series中的值进行逐一映射,带入进函数.字典或Series中得出的另一个值. Ser
-
浅谈Pandas中map, applymap and apply的区别
1.apply() 当想让方程作用在一维的向量上时,可以使用apply来完成,如下所示 In [116]: frame = DataFrame(np.random.randn(4, 3), columns=list('bde'), index=['Utah', 'Ohio', 'Texas', 'Oregon']) In [117]: frame Out[117]: b d e Utah -0.029638 1.081563 1.280300 Ohio 0.647747 0.831136 -1.
-

pandas map(),apply(),applymap()区别解析
基础 以下操作基于python 3.6 windows 10 环境下 通过 将通过实例来演示三者的区别 toward_dict = {1: '东', 2: '南', 3: '西', 4: '北'} df = pd.DataFrame({'house' : list('AABCEFG'), 'price' : [100, 90, '', 50, 120, 150, 200], 'toward' : ['1','1','2','3','','3','2']}) df map()方法 通过df.(ta
-
详解Pandas的三大利器(map,apply,applymap)
目录 模拟数据 1.map demo 实际数据 2.apply demo apply实现需求 3.applymap DF数据加1 保留2位有效数字 实际工作中,我们在利用 pandas进行数据处理的时候,经常会对数据框中的单行.多行(列也适用)甚至是整个数据进行某种相同方式的处理,比如将数据中的 sex字段将 男替换成1,女替换成0. 在这个时候,很容易想到的是 for循环.用 for循环是一种很简单.直接的方式,但是运行效率很低.本文中介绍了 pandas中的三大利器: map.apply.a
-
Python函数中apply、map、applymap的区别
目录 一.总结 二.实操对比 一.总结 apply -- 应用在 dataFrame 上,用于对 row 或者 column 进行计算 applymap -- 应用在 dataFrame 上,元素级别的操作 map -- python 系统自带函数,应用在 series 上, 元素级别的操作 二.实操对比 构建测试数据框: import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(0, 10, (4, 3
-
pandas中apply和transform方法的性能比较及区别介绍
1. apply与transform 首先讲一下apply() 与transform()的相同点与不同点 相同点: 都能针对dataframe完成特征的计算,并且常常与groupby()方法一起使用. 不同点: apply()里面可以跟自定义的函数,包括简单的求和函数以及复杂的特征间的差值函数等(注:apply不能直接使用agg()方法 / transform()中的python内置函数,例如sum.max.min.'count'等方法) transform() 里面不能跟自定义的特征交互函数,
-
一文搞懂Map与Set的用法和区别解析
目录 前言 1.基本概念 1.1 Map(字典) 1.2 Set(集合) 2.基本使用 2.1 Map 基本使用 2.2 Set 基本使用 3.Map和Set区别 4.使用场景介绍 4.1 Set对象使用场景 4.2 Map对象使用场景 5.思考点 总结 前言 作为前端开发人员,我们最常用的一些数据结构就是 Object.Array 之类的,毕竟它们使用起来非常的方便.往往有些刚入门的同学都会忽视 Set 和 Map 这两种数据结构的存在,因为能用 set 和 map 实现的,基本上也可以使用对
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
HashSet和TreeSet使用方法的区别解析
一.问题 1.HashSet,TreeSet是如何使用hashCode()和equal()方法的 2.TreeMap,TreeSet中的对象何时以及为何要实现Comparable接口? 二.回答: 1.HashSet是通过HashMap实现的,TreeSet是通过TreeMap实现的,只不过Set用的只是Map的key. 2.Map的key和Set都有一个共同的特性就是集合的唯一性.TreeMap更是多了一个有序性. 3.hashCode和equal()是HashMap用的,因为无需排序所以只需
-
JavaScript函数Call、Apply原理实例解析
这篇文章主要介绍了JavaScript函数Call.Apply原理实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.方法重用 使用 call() 方法,您可以编写能够在不同对象上使用的方法. 1.函数是对象方法 在 JavaScript 中,函数是对象的方法. 如果一个函数不是 JavaScript 对象的方法,那么它就是全局对象的函数(参见前一章). 下面的例子创建了带有三个属性的对象(firstName.lastName.full