R语言验证及协方差的计算公式
协方差的计算公式及R语言进行验证
首先附上协方差公式:
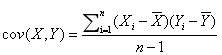
来设5个样本点:(3,9),(2,7),(4,12),(5,15),(6,17)
用R绘制出散点图,大概是这样:

要求这5个点的协方差,首先样本点为5个,n=5,X依次取3,2,4,5,6,Y依次取9,7,12,15,17。X的均值为4,带入公式可得:
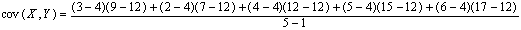
不难计算出结果为6.5
现在用R语言进行验证:
已知R语言里边协方差函数为cov(x,y)
我们分别用cov()函数和上述公式来进行仿真结果,代码如下:
a <- c(3,2,4,5,6)
b <- c(9,7,12,15,17)
COV=0
EX=mean(a)
EY=mean(b)
for(j in 1:5){
COV <- COV+(a[j]-EX)*(b[j]-EY)/4
}
COV
cov(a,b)
输出结果如下:
> COV
[1] 6.5
> cov(a,b)
[1] 6.5
由此可得,计算公式得出的结果完全正确
到此这篇关于R语言验证及协方差的计算公式的文章就介绍到这了,更多相关R语言协方差计算内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
解决R语言 数据不平衡的问题
R语言解决数据不平衡问题 一.项目环境 开发工具:RStudio R:3.5.2 相关包:dplyr.ROSE.DMwR 二.什么是数据不平衡?为什么要处理数据不平衡? 首先我们要知道的第一个问题就是"什么是数据不平衡",从字面意思上进行解释就是数据分布不均匀.在我们做有监督学习的时候,数据中有一个类的比例远大于其他类,或者有一个类的比值远小于其他类时,我们就可以认为这个数据存在数据不平衡问题. 那么这样的一个问题会对我们后续的分析工作带来怎样的影响呢?我举个简单的例子,或许大家就明白
-

用R语言绘制函数曲线图
函数曲线图是研究函数的重要工具. R 中 curve() 函数可以绘制函数的图像,代码格式如下: curve(expr, from = NULL, to = NULL, n = 101, add = FALSE, type = "l", xname = "x", xlab = xname, ylab = NULL, log = NULL, xlim = NULL, -) # S3 函数的方法 plot(x, y = 0, to = 1, from = y, xlim
-
R语言数据预处理操作——离散化(分箱)
一.项目环境 开发工具:RStudio R:3.5.2 相关包:infotheo,discretization,smbinning,dplyr,sqldf 二.导入数据 # 这里我们使用的是鸢尾花数据集(iris) data(iris) head(iris) Sepal.Length Sepal.Width Petal.Length Petal.Width Species 1 5.1 3.5 1.4 0.2 setosa 2 4.9 3.0 1.4 0.2 setosa 3 4.7 3.2 1.
-
R语言时间序列中时间年、月、季、日的处理操作
1.年 pt<-ts(p, freq = 1, start = 2011) 2.月 pt<-ts(p,frequency=12,start=c(2011,1)) frequency=12表示以月份为单位,start 表示时间开始点,start=c(2011,1) 表示从2011年1月开始 3.季度 pt <- ts(p, frequency = 4, start = c(2011, 1)) 4.天 pt<-ts(p,frequency=7,start=c(2011,1)) 用 ts
-
R语言时间序列TAR阈值自回归模型示例详解
为了方便起见,这些模型通常简称为TAR模型.这些模型捕获了线性时间序列模型无法捕获的行为,例如周期,幅度相关的频率和跳跃现象.Tong和Lim(1980)使用阈值模型表明,该模型能够发现黑子数据出现的不对称周期性行为. 一阶TAR模型的示例: σ是噪声标准偏差,Yt-1是阈值变量,r是阈值参数, {et}是具有零均值和单位方差的iid随机变量序列. 每个线性子模型都称为一个机制.上面是两个机制的模型. 考虑以下简单的一阶TAR模型: #低机制参数 i1 = 0.3 p1 = 0.5 s1 = 1
-
R语言学习笔记之lm函数详解
在使用lm函数做一元线性回归时,发现lm(y~x+1)和lm(y~x)的结果是一致的,一直没找到两者之间的区别,经过大神们的讨论和测试,才发现其中的差别,测试如下: ------------------------------------------------------------- ------------------------------------------------------------- 结果可以发现,两者的结果是一样的,并无区别,但是若改为lm(y~x-1)就能看出+1和
-
R语言验证及协方差的计算公式
协方差的计算公式及R语言进行验证 首先附上协方差公式: 来设5个样本点:(3,9),(2,7),(4,12),(5,15),(6,17) 用R绘制出散点图,大概是这样: 要求这5个点的协方差,首先样本点为5个,n=5,X依次取3,2,4,5,6,Y依次取9,7,12,15,17.X的均值为4,带入公式可得: 不难计算出结果为6.5 现在用R语言进行验证: 已知R语言里边协方差函数为cov(x,y) 我们分别用cov()函数和上述公式来进行仿真结果,代码如下: a <- c(3,2,4,5,6)
-
R语言交叉验证的实现代码
k-折交叉验证 k-折交叉验证(K-fold cross-validation)是交叉验证方法里一种.它是指将样本集分为k份,其中k-1份作为训练数据集,而另外的1份作为验证数据集.用验证集来验证所得分类器或者模型的错误率.一般需要循环k次,直到所有k份数据全部被选择一遍为止. 有关交叉验证的介绍可参考作者另一博文: http://blog.csdn.net/yawei_liu1688/article/details/79138202 R语言实现 K折交叉验证,随机分组 数据打折-数据分组自编译
-
R语言逻辑回归、ROC曲线与十折交叉验证详解
自己整理编写的逻辑回归模板,作为学习笔记记录分享.数据集用的是14个自变量Xi,一个因变量Y的australian数据集. 1. 测试集和训练集3.7分组 australian <- read.csv("australian.csv",as.is = T,sep=",",header=TRUE) #读取行数 N = length(australian$Y) #ind=1的是0.7概率出现的行,ind=2是0.3概率出现的行 ind=sample(2,N,rep
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
R语言的特点总结
R语言一般特点 自由软件,免费.开放源代码,支持各个主要计算机系统: 完整的程序设计语言,基于函数和对象,可以自定义函数,调入C.C++.Fortran编译的代码: 具有完善的数据类型,如向量.矩阵.因子.数据集.一般对象等,支持缺失值,代码像伪代码一样简洁.可读; 强调交互式数据分析,支持复杂算法描述,图形功能强; 实现了经典的.现代的统计方法,如参数和非参数假设检验.线性回归.广义线性回归.非线性回归.可加模型.树回归.混合模型.方差分析.判别.聚类.时间序列分析等. 统计科研工作者广泛使用
-
R语言基础统计方法图文实例讲解
tidyr > tdata <- data.frame(names=rownames(tdata),tdata)行名作为第一列 > gather(tdata,key="Key",value="Value",cyl:disp,mpg)创key列和value列,cyl和disp放在一列中 -号减去不需要转换的列 > spread(gdata,key="Key",value="Value") 根据value将
-
R语言关于“包”的知识点总结
R语言的包是R函数,编译代码和样本数据的集合. 它们存储在R语言环境中名为"library"的目录下. 默认情况下,R语言在安装期间安装一组软件包. 随后添加更多包,当它们用于某些特定目的时. 当我们启动R语言控制台时,默认情况下只有默认包可用. 已经安装的其他软件包必须显式加载以供将要使用它们的R语言程序使用. 所有可用的R语言包都列在R语言的包. 下面是用于检查,验证和使用R包的命令列表. 检查可用R语言的包 获取包含R包的库位置 .libPaths() 当我们执行上面的代码,它产
-
R语言数据的输入和输出操作
数据的载入 R本身已经提供了超过50个数据集,而在众多功能包中,默认的数据集被存放在datasets程序包中,通过函数data()k可以查看系统提供所有的数据包,同时可以通过函数library()加载程序包中的数据. 矩阵型数据最常用的读取方式是read.table()具体的调用格式是() read.table(file, header = FALSE, sep = "", quote = "\"'",dec = ".", numera
-
R语言-实现按日期分组求皮尔森相关系数矩阵
R语言按日期分组求相关系数 前几天得到了3700+支股票一周内的波动率,想要计算每周各个股票之间的相关系数并将其可视化.最终结果保存在制定文件夹中. 部分数据如下: 先读取数据 data<-read.csv("D:/data/stock_day_close_price_week_series.csv", header = TRUE,blank.lines.skip = TRUE) 利用mice包处理缺失值: library(lattice) library(MASS) libra
-
R语言利用caret包比较ROC曲线的操作
说明 我们之前探讨了多种算法,每种算法都有优缺点,因而当我们针对具体问题去判断选择那种算法时,必须对不同的预测模型进行重做评估. 为了简化这个过程,我们使用caret包来生成并比较不同的模型与性能. 操作 加载对应的包与将训练控制算法设置为10折交叉验证,重复次数为3: library(ROCR) library(e1071) library("pROC") library(caret) library("pROC") control = trainControl(