C++超详细讲解模拟实现vector
目录
- 1. 模拟实现vector
- 2. vector常用接口
- 2.1 reserve
- 2.2 resize
- 2.3 push_back
- 2.4 pop_back()
- 2.5 insert
- 2.6 erase
- 2.7 构造函数的匹配问题
- 3. 更深层次的深浅拷贝问题
1. 模拟实现vector
我们模拟实现是为了加深对这个容器的理解,不是为了造更好的轮子。

快速搭一个vector的架子
// vector.h
#pragma once
#include <assert.h>
// 模拟实现 -- 加深对这个容器理解,不是为了造更好的轮子
namespace Yuucho
{
template<class T>
class vector
{
public:
typedef T* iterator;
typedef const T* const_iterator;
vector()
:_start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{}
// 迭代器区间来构造,用模板的原因是存储的类型多种多样
template <class InputIterator>
vector(InputIterator first, InputIterator last)
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
while (first != last)
{
push_back(*first);
++first;
}
}
// 用n个T去构造,但是会隐藏匹配问题
vector(size_t n, const T& val = T())
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
reserve(n);
for (size_t i = 0; i < n; ++i)
{
push_back(val);
}
}
void swap(vector<T>& v)
{
std::swap(_start, v._start);
std::swap(_finish, v._finish);
std::swap(_endofstorage, v._endofstorage);
}
//拷贝构造函数
vector(const vector<T>& v)
: _start(nullptr)
, _finish(nullptr)
, _endofstorage(nullptr)
{
vector<T> tmp(v.begin(), v.end());
swap(tmp);
}
// 拷贝赋值函数
vector<T>& operator=(vector<T> v)
{
swap(v);
return *this;
}
// 资源管理
~vector()
{
if(_start)
{
delete[] _start;
_start = _finish = _endofstorage = nullptr;
}
}
iterator begin()
{
return _start;
}
iterator end()
{
return _finish;
}
const_iterator begin() const
{
return _start;
}
const_iterator end() const
{
return _finish;
}
// 默认是内联,频繁调用不用担心栈帧消耗
size_t size() const
{
return _finish - _start;
}
size_t capacity() const
{
return _endofstorage - _start;
}
void reserve(size_t n)
{
}
//void resize(size_t n, const T& val = T())
void resize(size_t n, T val = T())
{
}
void push_back(const T& x)
{
}
void pop_back()
{
}
T& operator[](size_t pos)
{
assert(pos < size());
return _start[pos];
}
const T& operator[](size_t pos) const
{
assert(pos < size());
return _start[pos];
}
iterator insert(iterator pos, const T& x)
{
}
void clear()
{
_finish = _start;
}
private:
iterator _start;
iterator _finish;
iterator _endofstorage;
};
}
2. vector常用接口
2.1 reserve
跟string的扩容思路一样。一般不考虑缩容(n<capacity),因为这是时间换空间的做法,我们要的是效率。
错误代码:
void reserve(size_t n)
{
// 一般不考虑缩容(n<capacity)
if(n > capacity())
{
T* tmp = new T[n];
// capacity为0,n就是4(_endofstorage、_start都为nuptr)
// 有数据才拷贝
if(_start)
{
memcpy(tmp, _start, size()*sizeof(T));
delete[] _start;
}
_start = tmp; // 注意,这里start位置变了
}
// 更新_finish、_endofstorage
_finish = _start + size(); // size():_finish - _start, _finish还是空指针
_endofstorage = _start + capacity; //capacity起始为0,也不对
}
修正后的代码:
void reserve(size_t n)
{
// 记录size
size_t sz = size();
if(n > capacity())
{
T* tmp = new T[n];
if(_start)
{
//memcpy还会隐藏更深层次的深浅拷贝问题,讲解在最后
memcpy(tmp, _start, size()*sizeof(T));
delete[] _start;
}
_start = tmp; // 注意,这里start位置变了
}
// 更新_finish、_endofstorage
_finish = _start + sz;
_endofstorage = _start + n;
}
2.2 resize
resize是开空间+初始化,size_type就是size_t,value_type就是T。

C++模板出来了语法就必须支持内置类型的默认构造、析构函数。
int() // 默认构造是0
double() // 默认构造是0.0
int*() // 默认构造是nullptr

思路与string一样
//void resize(size_t n, const T& val = T()) 严格的编译器编不过,它认为T是临时对象
// 按照库里的写法
void resize(size_t n, T val = T()) // T类型的匿名对象,默认构造函数很重要,内置类型咋办?
{
if (n > capacity())
{
reserve(n);
}
if (n > size())
{
while (_finish < _start + n)
{
*_finish = val;
++_finish;
}
}
// n < capacity就是删除数据
else
{
_finish = _start + n;
}
}
2.3 push_back
void push_back(const T& x)
{
// 满了先扩容
if(_finish == _endofstorage)
{
size_t newCapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newCapacity);
}
// 插入数据
*_finish = x;
++_finish;
}
复用insert:
void push_back(const T& x)
{
insert(end(), x);
}
2.4 pop_back()
void pop_back()
{
// 如果不为空
if(_finish > _start)
{
--_finish;
}
}
复用erase:
void pop_back()
{
erase(end()-1);
}
2.5 insert
库里面的insert是带返回值的,我们先不管,先写一个没有返回值的看看。
void insert(iterator pos, const T& x)
{
// 检查参数
assert(pos >= _start && pos <= _finish);
// 扩容
if (_finish == _endofstorage)
{
size_t newCapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newCapacity);
}
// 挪动数据
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
}
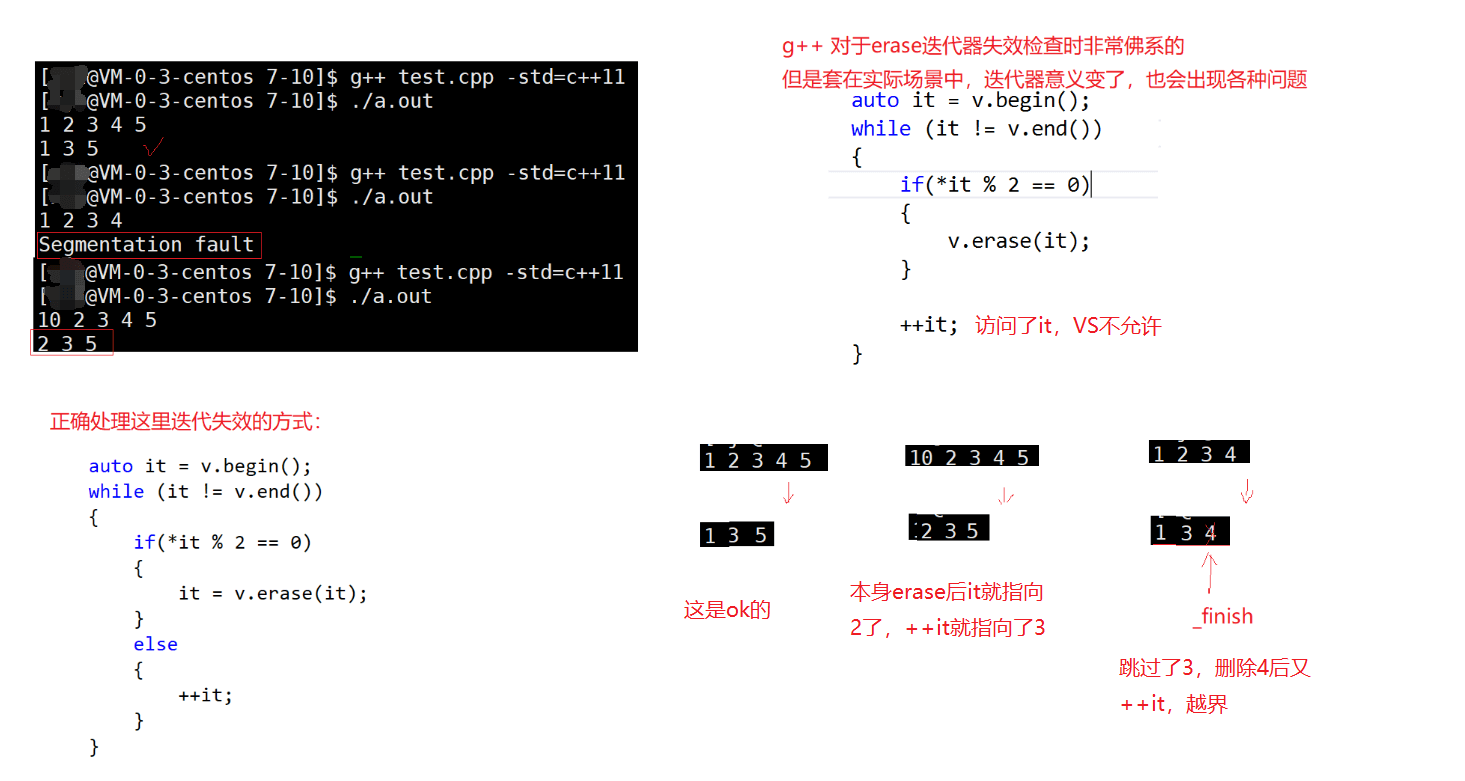
(1) 迭代器失效第一种场景
yeahbaby,现在我们就可以来讲讲迭代器失效的问题了,嘿嘿嘿。
如果插入时没有扩容,ok,那还好说,没有问题。
如果扩容了,reserve会去更新_start和_finish,而不会去更新pos(pos还是会指向旧空间,迭代器发生了野指针问题)。在VS环境下,会用断言暴力检查出来的。在Linux环境下,检查不出来这种情况,甚至对原来的it仍然可读可写。

ok,那我们在扩容时更新一下pos:
if (_finish == _endofstorage)
{
size_t n = pos - _start;
size_t newCapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newCapacity);
pos = _start + n;
}
(2)另一种场景
void test_vector1()
{
// 在所有的偶数的前面插入2
vector<int> v;
//v.reserve(10);
v.push_back(1);
v.push_back(2);
v.push_back(3);
v.push_back(4);
v.push_back(5);
v.push_back(6);
vector<int>::iterator it = v.begin();
while (it != v.end())
{
if (*it % 2 == 0)
{
it = v.insert(it, 20);
++it;
}
++it;
}
for (auto e : v)
{
cout << e << " ";
}
cout << endl;
}
}
运行结果

导致断言错误的原因是啥?为什么不能在2的前面插入20?
同样的道理,虽然我们修正了pos,但是我们是值传递,形参不会改变实参。所以it仍然是野指针。在VS环境下,会用断言暴力检查出来的。在Linux环境下,检查不出来这种情况,甚至对原来的it仍然可读可写。

有小伙伴就会说了,传引用不就行了吗?
我们是不会用引用的,官方库也没有用引用。因为我要传的是像v.begin()这样的临时对象怎么办。
更悲伤的是就算我提前把空间给你开好,保证插入时不需要扩容还是会出现问题。因为insert是在2之前插入20,++it后it仍指向2,这样就导致不断地在2之前插入20。这也是迭代器失效的一种场景。

修正后的代码:
用返回值解决,官方库里返回的是指向新插入的第一个元素的迭代器。 那我们也这样返回。
iterator insert(iterator pos, const T& x)
{
// 检查参数
assert(pos >= _start && pos <= _finish);
// 扩容
// 扩容以后pos就失效了,需要更新一下
if (_finish == _endofstorage)
{
size_t n = pos - _start;
size_t newCapacity = capacity() == 0 ? 4 : capacity() * 2;
reserve(newCapacity);
pos = _start + n;
}
// 挪动数据
iterator end = _finish - 1;
while (end >= pos)
{
*(end + 1) = *end;
--end;
}
*pos = x;
++_finish;
return pos;
}
此时我们这样使用就行:
while (it != v.end())
{
if(*it % 2 == 0)
{
// 返回新插入的第一个元素的迭代器
it = v.insert(it, 20);
//还是指向2
++it;
}
// 指向2的后一位
++it;
}
运行结果

2.6 erase
一般vector删除数据,都不考虑缩容的方案。
缩容方案:size() < capacity()/2时,可以考虑开一个size()大小的空间,拷贝数据,释放旧空间。
缩容方案本质是时间换空间。一般设计都不会考虑缩容,因为实际比较关注时间效率,不关注空间效率,因为现在硬件设备空间都比较大,空间存储也比较便宜。
我们这里不考虑缩容方案。
erase返回最后一个被释放元素的后一个元素的新位置。
iterator erase(iterator pos)
{
assert(pos >= _start && pos < _finish);
iterator it = pos + 1;
while (it != _finish)
{
*(it - 1) = *it;
++it;
}
//erase最后一个数据,则pos==_finish,pos真失效了,但仍然属于这个容器
--_finish;
return pos;
}
VS中的vector也没有考虑缩容方案,但是它对pos(如果缩容,pos就是野指针)进行了断言检查,不允许访问和写入。
(1)erase迭代器的失效都是意义变了,或者不在有效访问数据的范围。
(2)一般不会使用缩容的方案,那么erase的失效,一般也不存在野指针的失效。
erase(pos)以后pos失效了,pos的意义变了,但是不同平台下面对访问pos的反应不一样。VS会强制检查,Linux则没有严格的检查机制。我们用的时候一定要小心,统一以失效角度去看待。
erase迭代器意义变了的场景(假设我们要删除容器中的偶数):
2.7 构造函数的匹配问题
迭代器区间的构造函数的参数要求是同类型的,而第一个构造函数的第一个参数是size_t,int会涉及隐式类型转换。所以参数为(10,2)的会匹配迭代器区间的构造函数,而参数为(10, ‘x’)的会匹配第一个构造函数。
这里就会导致int类型被当作迭代器解引用,本质上是发生了构造函数的错配问题。

解决方法:
源码是通过再写一个第一个参数为int类型的构造函数来解决的。
vector(int n, const T& val = T())
: _start(nullptr)
, _finish(nullptr)
, _endofstoage(nullptr)
{
reserve(n);
for (int i = 0; i < n; ++i)
{
push_back(val);
}
}
3. 更深层次的深浅拷贝问题
以杨辉三角为例:
class Solution {
public:
vector<vector<int>> generate(int numRows) {
vector<vector<int>> vv;
// 先开辟杨辉三角的空间
vv.resize(numRows);
//初始化每一行
for(size_t i = 0; i < numRows; ++i)
{
//每行个数依次递增
vv[i].resize(i+1, 0);
// 每一行的第一个和最后一个都是1
vv[i][0] = 1;
vv[i][vv[i].size()-1] = 1;
}
for(size_t i = 0; i < vv.size(); ++i)
{
for(size_t j = 0; j < vv[i].size(); ++j)
{
if(vv[i][j] == 0)
{
//之间位置等于上一行j-1和j个相加
vv[i][j] = vv[i-1][j-1] + vv[i-1][j];
}
}
}
return vv;
}
};
我们自己写的vector去跑这里的杨辉三角会出现问题。
void test_vector2()
{
vector<vector<int>> ret = Solution().generate(5);
for (size_t i = 0; i < ret.size(); ++i)
{
for (size_t j = 0; j < ret[i].size(); ++j)
{
cout << ret[i][j] << " ";
}
cout << endl;
}
cout << endl;
}
为了方便大家理解,我们把扩容的代码拿下来。
void reserve(size_t n)
{
// 记录size
size_t sz = size();
if(n > capacity())
{
T* tmp = new T[n];
if(_start)
{
memcpy(tmp, _start, size()*sizeof(T));
delete[] _start;
}
_start = tmp; // 注意,这里start位置变了
}
// 更新_finish、_endofstorage
_finish = _start + sz;
_endofstorage = _start + n;
}
vector<vector<int>> ret = Solution().generate(5);会去调用拷贝构造,拷贝构造又去调用了迭代器的区间构造函数,迭代器区间构造函数又去调用了push_back,push_back又去调用了reserve。
因为push_back我们第一次开的空间是4,所以前4次的push_back都不会有问题,第5次push_back去调用reserve时就会出现问题。
因为扩容的时候tmp会把前4组的vector<int>数据memcpy下来,而memcpy是浅拷贝,拷贝下来的数据和原来的数据指向的是同一块空间。关键是memcpy后又delete了旧空间,导致插入第5个vector<int>时前4组的数据被释放了,成了野指针。

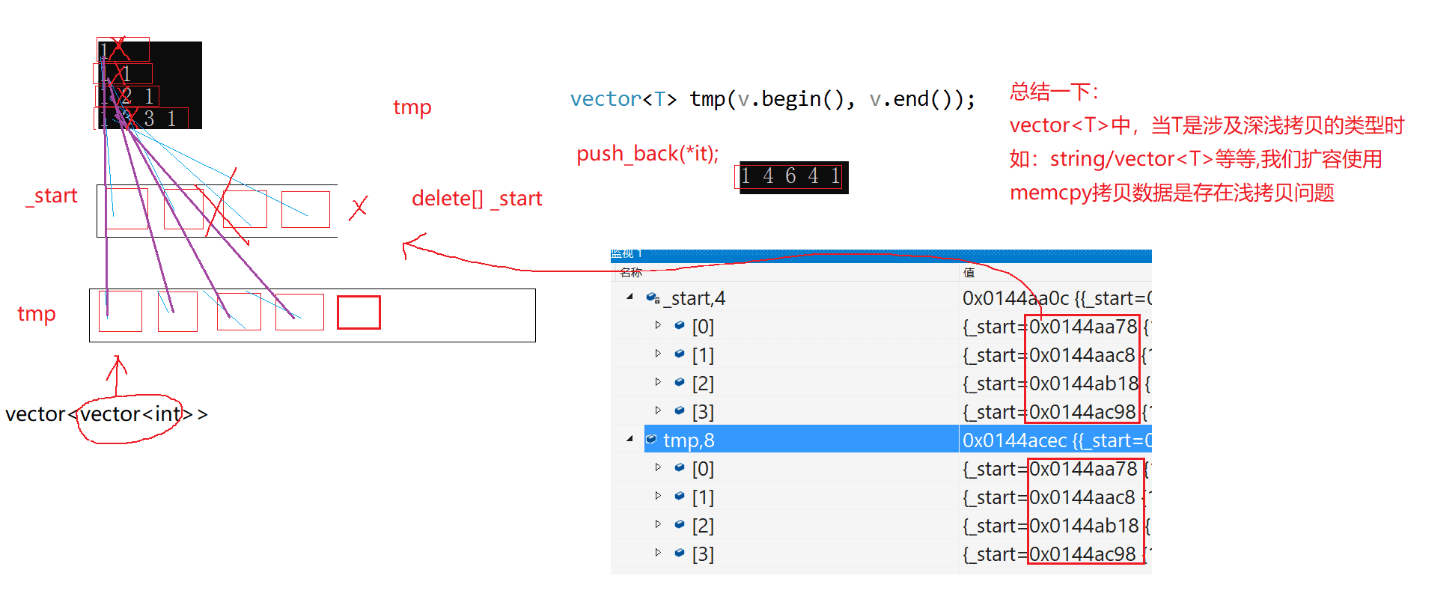
解决方法:
拷贝的时候不要用memcpy,使用拷贝赋值函数来完成,因为赋值函数会帮我们完成深拷贝。
void reserve(size_t n)
{
// 记录size
size_t sz = size();
if(n > capacity())
{
T* tmp = new T[n];
if(_start)
{
//防止浅拷贝问题3
for (size_t i = 0; i < size(); ++i)
{
tmp[i] = _start[i];
}
delete[] _start;
}
_start = tmp; // 注意,这里start位置变了
}
// 更新_finish、_endofstorage
_finish = _start + sz;
_endofstorage = _start + n;
}
到此这篇关于C++超详细讲解模拟实现vector的文章就介绍到这了,更多相关C++ vector内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

C++ vector类的模拟实现方法
vector和string虽然底层都是通过顺序表来实现的,但是他们利用顺序表的方式不同,string是指定好了类型,通过使用顺序表来存储并对数据进行操作,而vector是利用了C++中的泛型模板,可以存储任何类型的数据,并且在vector中,并没有什么有效字符和容量大小的说法,底层都是通过迭代器进行操作的,迭代器底层实现也就是指针,所以说,vector是利用指针对任何顺序表进行操作的. vector属性 _start用于指向第一个有效元素 _finish用于指向最后一个有效元素的下一个位置 _e
-
c++中vector的使用和模拟实现
一.接口介绍 1.插入数据 void push_back(const T& x) 在当前vector尾部插入x,如果容量不够扩大二倍. iterator insert(iterator pos, const T& x) 在POS位置插入元素x 2.容量相关 size_t capacity() 返回当前vector的容量(size+剩余容量) size_t size() 返回当前vector的元素个数 void resize(size_t n, const T& val = T())
-
C++中vector的模拟实现实例详解
目录 vector接口总览 默认成员函数 构造函数 拷贝构造 赋值重载 析构函数 迭代器相关函数 begin和end 容量相关函数 size和capacity reserve resize empty 修改容器相关函数 push_back pop_back insert erase swap 访问容器相关函数 operator[ ] 总结 vector接口总览 namespace nzb { //模拟实现vector template<class T> class vector { publi
-
C++ STL vector的模拟实现
1. vector的介绍和使用 vector是表示可变大小数组的序列容器. 就像数组一样,vector也采用的连续存储空间来存储元素.也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效.但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理. 本质讲,vector使用动态分配数组来存储它的元素.当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间.其做法是,分配一个新的数组,然后将全部元素移到这个数组.就时间而言,这是一个相对代价高的任务,因为每当一个新
-
c++ vector模拟实现的全过程
一.vector是什么? vector是表示可变大小数组的序列容器,它也采用连续存储空间来存储元素,因此可以采用下标对vector的元素进行访问,它的大小是动态改变的,vector使用动态分配数组来存储它的元素: 二.容器特性 1.顺序序列 顺序容器中的元素按照严格的线性顺序排序.可以通过元素在序列中的位置访问对应的元素; 2.动态数组 支持对序列中的任意元素进行快速直接访问,甚至可以通过指针进行该操作.操供了在序列末尾相对快速地添加/删除元素的操作; 3.能够感知内存分配器的 容器使用一个内存
-
c++ vector模拟实现代码
vector的介绍 1.vector是表示可变大小数组的序列容器. 2.就像数组一样,vector也采用的连续存储空间来存储元素.也就是意味着可以采用下标对vector的元素进行访问,和数组一样高效.但是又不像数组,它的大小是可以动态改变的,而且它的大小会被容器自动处理. 3.本质讲,vector使用动态分配数组来存储它的元素.当新元素插入时候,这个数组需要被重新分配大小为了增加存储空间.其做法是,分配一个新的数组,然后将全部元素移到这个数组.就时间而言,这是一个相对代价高的任务,因为每当一个新
-
C++超详细讲解模拟实现vector
目录 1. 模拟实现vector 2. vector常用接口 2.1 reserve 2.2 resize 2.3 push_back 2.4 pop_back() 2.5 insert 2.6 erase 2.7 构造函数的匹配问题 3. 更深层次的深浅拷贝问题 1. 模拟实现vector 我们模拟实现是为了加深对这个容器的理解,不是为了造更好的轮子. 快速搭一个vector的架子 // vector.h #pragma once #include <assert.h> // 模拟实现 --
-
超详细讲解Linux C++多线程同步的方式
目录 一.互斥锁 1.互斥锁的初始化 2.互斥锁的相关属性及分类 3,测试加锁函数 二.条件变量 1.条件变量的相关函数 1)初始化的销毁读写锁 2)以写的方式获取锁,以读的方式获取锁,释放读写锁 四.信号量 1)信号量初始化 2)信号量值的加减 3)对信号量进行清理 背景问题:在特定的应用场景下,多线程不进行同步会造成什么问题? 通过多线程模拟多窗口售票为例: #include <iostream> #include<pthread.h> #include<stdio.h&
-
C++ 数据结构超详细讲解顺序表
目录 前言 一.顺序表是什么 概念及结构 二.顺序表的实现 顺序表的缺点 几道练手题 总结 (●’◡’●) 前言 线性表是n个具有相同特性的数据元素的有限序列.线性表是一种在实际中广泛使用的数据结构,常见的线性表:顺序表.链表.栈.队列.字符串. 线性表在逻辑上是线性结构,也就是说连续的一条直线,但是在物理结构并不一定是连续的,线性表在物理上存储时,通常以数组和链式结构的形式存储. 本章我们来深度初体验顺序表 一.顺序表是什么 概念及结构 顺序表是一段物理地址连续的存储单元依次存储数据元素的线性
-
C语言超详细讲解栈与队列实现实例
目录 1.思考-1 2.栈基本操作的实现 2.1 初始化栈 2.2 入栈 2.3 出栈 2.4 获取栈顶数据 2.5 获取栈中有效元素个数 2.6 判断栈是否为空 2.7 销毁栈 3.测试 3.1测试 3.2测试结果 4.思考-2 5.队列的基本操作实现 5.1 初始化队列 5.2 队尾入队列 5.3 队头出队列 5.4 队列中有效元素的个数 5.5 判断队列是否为空 5.6 获取队头数据 5.7 获取队尾的数据 5.8 销毁队列 6.测试 6.1测试 6.2 测试结果 1.思考-1 为什么栈用
-
Java超详细讲解SpringMVC如何获取请求数据
目录 1.获得请求参数 1)基本类型参数: 2)POJO类型参数: 3)数组类型参数 4)集合类型参数 2.请求乱码问题 3.参数绑注解@RequestParam 4.获得Restful风格的参数 5.自定义类型转换器 6.获得请求头 7.文件上传 8.小结 1.获得请求参数 客户端请求参数的格式是:name=value&name=value- - 服务器端要获得请求的参数,有时还需要进行数据的封装,SpringMVC可以接收如下类型的参数: 1)基本类型
-
Java 超详细讲解十大排序算法面试无忧
目录 排序算法的稳定性: 一.选择排序 二.冒泡排序 三.插入排序 四.希尔排序 五.堆排序 六.归并排序 七.快速排序 八.鸽巢排序 九.计数排序 十.基数排序 排序算法的稳定性: 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,如果排序以后,保证这些记录的相对次序保持不变,即在原序列中,a[i]=a[j],且 a[i] 在 a[j] 之前,排序后保证 a[i] 仍在 a[j] 之前,则称这种排序算法是稳定的:否则称为不稳定的. 一.选择排序 每次从待排序的元素中选择最小的元素,依次
-
Java 超详细讲解数据结构的应用
目录 一.bfs 二.双端队列 三.算法题 1.kotori和迷宫 2.小红找红点 3.小红玩数组 一.bfs bfs(广度优先搜索),类似二叉树的层序遍历,利用队列完成.一般用于求最短路. 图的最短路问题: 给定一个无向图,每条边的长度都是1.求1号点到x号点的最短距离. 顶点数n 边数为m q次询问 输入x 输出1到x的最短距离. 若1号点到x不连通,则输出-1 二.双端队列 双端队列的应用(区间翻转): 对于长度为n的数组,给定一个长度为m的区间,区间初始位置为a[1]到a[m].
-
Java超详细讲解设计模式中的命令模式
目录 介绍 实现 个人理解:把一个类里的多个命令分离出来,每个类里放一个命令,实现解耦合,一个类只对应一个功能,在使用命令时由另一个类来统一管理所有命令. 缺点:如果功能多了就会导致创建的类的数量过多 命令模式(Command Pattern)是⼀种数据驱动的设计模式,它属于行为型模式.请求以命令的形式包裹在对象中,并传给调⽤对象.调⽤对象寻找可以处理该命令的合适的对象,并把该命令传给相应的对象,该对象执⾏命令. 介绍 意图:将⼀个请求封装成⼀个对象,从⽽使您可以⽤不同的请求对客户进⾏参数化.
-
C++超详细讲解数组操作符的重载
目录 一.字符串类的兼容性 二.重载数组访问操作符 三.小结 一.字符串类的兼容性 问题:string 类对象还具备 C 方式字符串的灵活性吗?还能直接访问单个字符吗? string 类最大限度的考虑了 C 字符串的兼容性 可以按照使用 C 字符串的方式使用 string 对象 下面看一个用 C 方式使用 string 类的示例: #include <iostream> #include <string> using namespace std; int main() { stri
-
C++详细讲解模拟实现位图和布隆过滤器的方法
目录 位图 引论 概念 解决引论 位图的模拟实现 铺垫 结构 构造函数 存储 set,reset,test flip,size,count any,none,all 重载流运算符 测试 位图简单应用 位图代码汇总 布隆过滤器 引论 要点 代码实现 效率 解决方法 位图 引论 四十亿个无符号整数,现在给你一个无符号整数,判断这个数是否在这四十亿个数中. 路人甲:简单,快排+二分. 可是存储这四十亿个整数需要多少空间? 简单算一下,1G=1024M=1024 * 1024KB=1024 * 1024