selenium动态数据获取的方法实现
目录
- webdriver的安装
- selenium安装
- 驱动安装
- 基本使用
- 查找节点
- 执行 JavaScript
- 切换 Frame
- 前进后退
- 选项卡管理
- 配置操作
- �绕过检测
Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击、下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可获取。对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效。接下来,就让我们来感受一下它的强大之处吧。
webdriver的安装
selenium安装
首先,我们使用selenium进行测试,所以我们得安装selenium库。
pip install selenium
驱动安装
webdriver 是浏览器对应的驱动,我们使用的的浏览器有三种谷歌Chrome、微软Microsoft Edge、还有一个火狐Firefox,但是我们经常使用谷歌Chrome浏览器进行测试。现在我们就以Chrome浏览器为例下载它对应的chromedriver 。
官网:http://chromedriver.storage.googleapis.com/index.html
注意:
我们下载chromedriver 驱动时,我们要查明浏览器的版本,要对应相应的版本号进行下载,否则会报错。禁止Google浏览器更新服务,可以上网查教程。
基本使用
查找节点
Selenium 可以驱动浏览器完成各种操作,比如填充表单、模拟点击等。比如,我们想要完成向某个输入框输入文字的操作,总需要知道这个输入框在哪里吧?而 Selenium 提供了一系列查找节点的方法,我们可以用这些方法来获取想要的节点,以便下一步执行一些动作或者提取信息。
获取节点的方法:
find_element_by_id find_element_by_name find_element_by_xpath find_element_by_link_text 专门用来定位超链接文本(标签) 全匹配 find_element_by_partial_link_text 模糊匹配 find_element_by_tag_name find_element_by_class_name find_element_by_css_selector
给个示例
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
input = browser.find_element_by_id('kw')
input.send_keys('Python')
browser.find_element_by_id('su').click()
# 提取页面
print(browser.page_source.encode('utf-8'))
# 提取cookie
print(browser.get_cookies())
# 提取当前请求地址
print(browser.current_url)
browser.close()
运行代码后发现,会自动弹出一个 Chrome 浏览器。浏览器首先会跳转到百度,然后在搜索框中输入 Python,接着跳转到搜索结果页
注:当我们的chromedriver驱动没有放置到Chrome浏览器路径时,我们可以使用以下来申明浏览器对象。
browser = webdriver.Chrome(executable_path="chromedriver安装路径")
方法总结:
- brower.get(url):跳转当前url链接。
- browser.find_element_by_id('id属性值'):定位到id属性值。
- send_keys('输入关键字'):定位到输入框后输入。
- find_element_by_id('id属性值').click():定位到id属性值后点击。
- browser.page_source.encode('utf-8'):获取当前页面的源码。
- browser.get_cookies():提取cookies。
- browser.current_url:获取当前页面的url。
- brower.close():关闭浏览器。
执行 JavaScript
对于某些操作,Selenium API 并没有提供。比如,下拉进度条,它可以直接模拟运行 JavaScript,此时使用 execute_script() 方法即可实现,代码如下:
# document.body.scrollHeight 获取页面高度
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://36kr.com/')
# 下拉边框 一次性下拉
browser.execute_script('window.scrollTo(0, document.body.scrollHeight)')
# 慢慢的下拉
for i in range(1,9):
time.sleep(random.randint(100, 300) / 1000)
browser.execute_script('window.scrollTo(0,{})'.format(i * 700))
这里就利用 execute_script() 方法将进度条下拉到最底部。为了模拟人为活动,我们调节了下拉的缓冲时间。
我们使用浏览器的控制台输入以下代码也能运行。
window.scrollTo(0, document.body.scrollHeight)
图例:
切换 Frame
我们知道网页中有一种节点叫作 iframe,也就是子 Frame,相当于页面的子页面,它的结构和外部网页的结构完全一致。Selenium 打开页面后,它默认是在父级 Frame 里面操作,而此时如果页面中还有子 Frame,它是不能获取到子 Frame 里面的节点的。这时就需要使用 switch_to.frame() 方法来切换 Frame。示例如下:
browser.get('https://www.douban.com/')
login_iframe = browser.find_element_by_xpath('//div[@class="login"]/iframe')
browser.switch_to.frame(login_iframe)
browser.find_element_by_class_name('account-tab-account').click()
browser.find_element_by_id('username').send_keys('123123123')
首先我们要定位到iframe,然后用switch_to.frame() 方法来切换 Frame,这时我们就可以定位到子 Frame进行有关操作了。
前进后退
平常使用浏览器时都有前进和后退功能,Selenium 也可以完成这个操作,它使用 back() 方法后退,使用 forward() 方法前进。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com/')
browser.get('https://www.taobao.com/')
browser.get('https://www.python.org/')
browser.back()
time.sleep(1)
browser.forward()
browser.close()
这里我们连续访问 3 个页面,然后调用 back() 方法回到第二个页面,接下来再调用 forward() 方法又可以前进到第三个页面。
选项卡管理
在访问网页的时候,会开启一个个选项卡。在 Selenium 中,我们也可以对选项卡进行操作。示例如下:
import time
from selenium import webdriver
browser = webdriver.Chrome()
browser.get('https://www.baidu.com')
browser.execute_script('window.open()')
print(browser.window_handles)
browser.switch_to_window(browser.window_handles[1])
browser.get('https://www.taobao.com')
time.sleep(1)
browser.switch_to_window(browser.window_handles[0])
browser.get('https://python.org')
这里我们先跳转到百度再打开一个空白选项卡打印选项卡编号,再跳转到第二个选项卡也就是这个空白选项卡打开淘宝,休息一秒,再跳转到第一个选项卡打开python官网。
配置操作
selenium有很多配置,下面我举几个常见的。
options = webdriver.ChromeOptions()
# 无头模式
option.add_argument("-headless")
#设置代理
options.add_argument('proxy-server=' +'192.168.0.28:808')
#将浏览器最大化显示
browser.maximize_window()
# 设置宽高
browser.set_window_size(480, 800)
# 通过js新打开一个窗口
driver.execute_script('window.open("https://www.baidu.com");')
browser = webdriver.Chrome(chrome_options=options)
�绕过检测
绕过检测对于一些网站的自动化反爬很管用。
# 设置屏蔽
options = webdriver.ChromeOptions()
options.add_argument('--disable-blink-features=AutomationControlled')
browsers = webdriver.Chrome(chrome_options=options)
browsers.get('https://bot.sannysoft.com/')
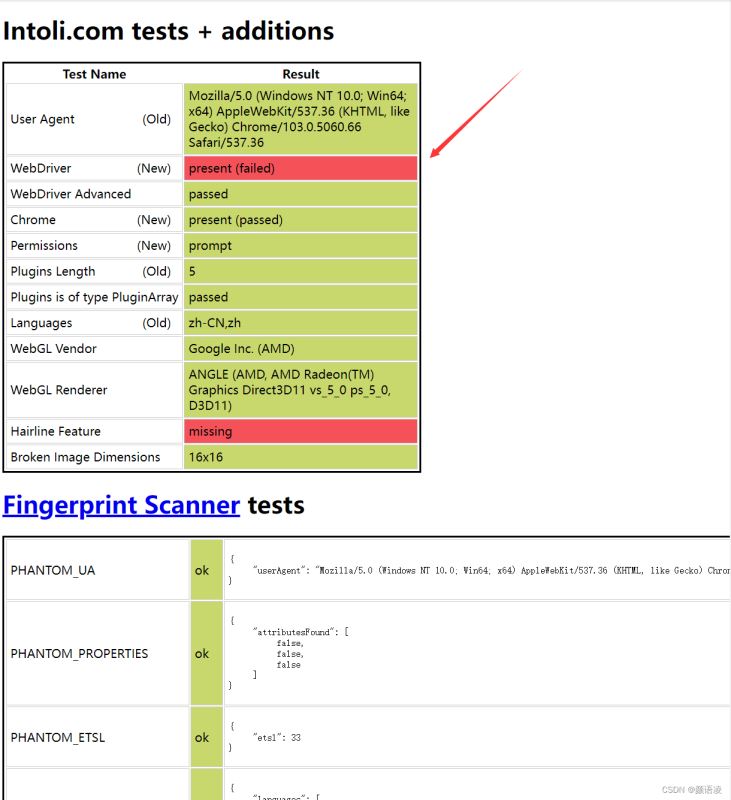
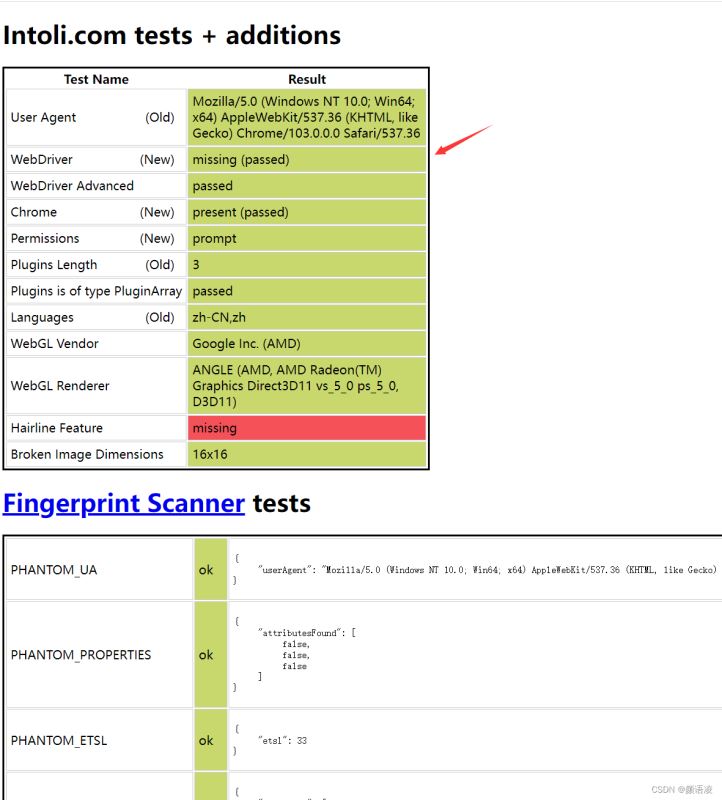
这里我们使用下面这个网站进行自动化检测
网站:https://bot.sannysoft.com/
我们没设置绕过检测
我们设置了绕过检测后
到此这篇关于selenium动态数据获取的方法实现的文章就介绍到这了,更多相关selenium动态数据获取内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
scrapy与selenium结合爬取数据(爬取动态网站)的示例代码
scrapy框架只能爬取静态网站.如需爬取动态网站,需要结合着selenium进行js的渲染,才能获取到动态加载的数据. 如何通过selenium请求url,而不再通过下载器Downloader去请求这个url? 方法:在request对象通过中间件的时候,在中间件内部开始使用selenium去请求url,并且会得到url对应的源码,然后再将 源 代码通过response对象返回,直接交给process_response()进行处理,再交给引擎.过程中相当于后续中间件的process_req
-

selenium动态数据获取的方法实现
目录 webdriver的安装 selenium安装 驱动安装 基本使用 查找节点 执行 JavaScript 切换 Frame 前进后退 选项卡管理 配置操作 �绕过检测 Selenium 是一个自动化测试工具,利用它可以驱动浏览器执行特定的动作,如点击.下拉等操作,同时还可以获取浏览器当前呈现的页面的源代码,做到可见即可获取.对于一些 JavaScript 动态渲染的页面来说,此种抓取方式非常有效.接下来,就让我们来感受一下它的强大之处吧. webdriver的安装 selenium安装 首
-
使用jsp:include控制动态内容的方法
本文实例讲述了使用jsp:include控制动态内容的方法.分享给大家供大家参考,具体如下: 清单 1. JSP include 伪指令 <![CDATA[ <%@ page language="java" contentType="text/html" %> <html> <head> <title>newInstance.com</title> <meta http-equiv="
-
Linux下g++编译与使用静态库和动态库的方法
在windows环境下,我们通常在IDE如VS的工程中开发C++项目,对于生成和使用静态库(*.lib)与动态库(*.dll)可能都已经比较熟悉,但是,在linux环境下,则是另一套模式,对应的静态库(*.a)与动态库(*.so)的生成与使用方式是不同的.刚开始可能会不适应,但是用多了应该会习惯这种使用,因为步骤上并没有VS下配置那么繁琐. 下面就分别总结下linux下生成并使用静态库与动态库的方法:(由于是C++项目,所以编译器用的g++,但是与gcc的使用是相通的) 首先是准备工作,把我们需
-
javascript元素动态创建实现方法
本文实例讲述了javascript元素动态创建实现方法.分享给大家供大家参考.具体分析如下: document.write只能在页面加载过程中才能动态创建 可以调用document的createElement方法来创建具有指定标签的DOM对象,然后通过调用元素的appendChild方法将 新创建元素添加到相应的元素下 举例如下: <html xmlns="http://www.w3.org/1999/xhtml"> <head> <meta http-e
-
java 动态代理的方法总结
java 动态代理的方法总结 AOP的拦截功能是由java中的动态代理来实现的.说白了,就是在目标类的基础上增加切面逻辑,生成增强的目标类(该切面逻辑或者在目标类函数执行之前,或者目标类函数执行之后,或者在目标类函数抛出异常时候执行.不同的切入时机对应不同的Interceptor的种类,如BeforeAdviseInterceptor,AfterAdviseInterceptor以及ThrowsAdviseInterceptor等). 那么动态代理是如何实现将切面逻辑(advise)织入到目标类
-
通过java反射机制动态调用某方法的总结(推荐)
如下: public Object invokeMethod(String className, String methodName, Object[] args) throws Exception{ Class ownerClass = Class.forName(className); Object owner = ownerClass.newInstance(); Class[] argsClass = new Class[args.length]; for (int i = 0, j =
-
js显示动态时间的方法详解
本文实例讲述了js显示动态时间的方法.分享给大家供大家参考,具体如下: Date对象的方法 Date 对象能够使你获得相对于国际标准时间(格林威治标准时间,现在被称为 UTC-Universal Coordinated Time)或者是 Flash 播放器正运行的操作系统的时间和日期.要使用Date对象的方法,你就必须先创建一个Date对象的实体(Instance). Date 对象必须使用 Flash 5 或以后版本的播放器. Date 对象的方法并不是静态的,但是在使用时却可以应用于所指定的
-
JavaScript实现同步于本地时间的动态时间显示方法
本文实例讲述了JavaScript实现同步于本地时间的动态时间显示方法.分享给大家供大家参考.具体分析如下: 动态显示时间的例子非常简单,了解JavaScript之后就是几行的代码便能够完成的事情, 但是对于一些未接触过JavaScript的人来说,几乎很大工程的样子,然后在网上苦苦寻觅代码,之后在茫茫的html代码中寻求不到,最终得不到要领. 一.基本目标 实现一个随同客户端(浏览者机器上的)时间的网页文本时间,使用最短的代码. 二.制作过程 复制代码 代码如下: <!DOCTYPE html
-
JS实现给json数组动态赋值的方法示例
本文实例讲述了JS实现给json数组动态赋值的方法.分享给大家供大家参考,具体如下: json 数组也是数组: //1. var jsonstr="[{'name':'a','value':1},{'name':'b','value':2}]"; var jsonarray = eval('('+jsonstr+')'); var arr = { "name" : $('#names').val(), "value" : $('#values')
-
JS实现向表格中动态添加行的方法
本文实例讲述了JS实现向表格中动态添加行的方法.分享给大家供大家参考.具体分析如下: 下面的JS代码通过表格对象的insertRow方法动态向表格的最顶端添加新的行 <!DOCTYPE html> <html> <head> <script> function insRow() { var x=document.getElementById('myTable').insertRow(0); var y=x.insertCell(0); var z=x.ins