python中的netCDF4批量处理NC文件的操作方法
目录
- 一、使用ArcMap提取出第一期数据
- 1.使用工具箱中的“Make NetCDF Raster Layer”工具,提取出一个数据
- 2.导出该数据作为标准数据
- 二、使用python批量提取所有数据
- 1. 查看数据属性
- 2.批量导出结果
- !注意事项
一、使用ArcMap提取出第一期数据
1.使用工具箱中的“Make NetCDF Raster Layer”工具,提取出一个数据
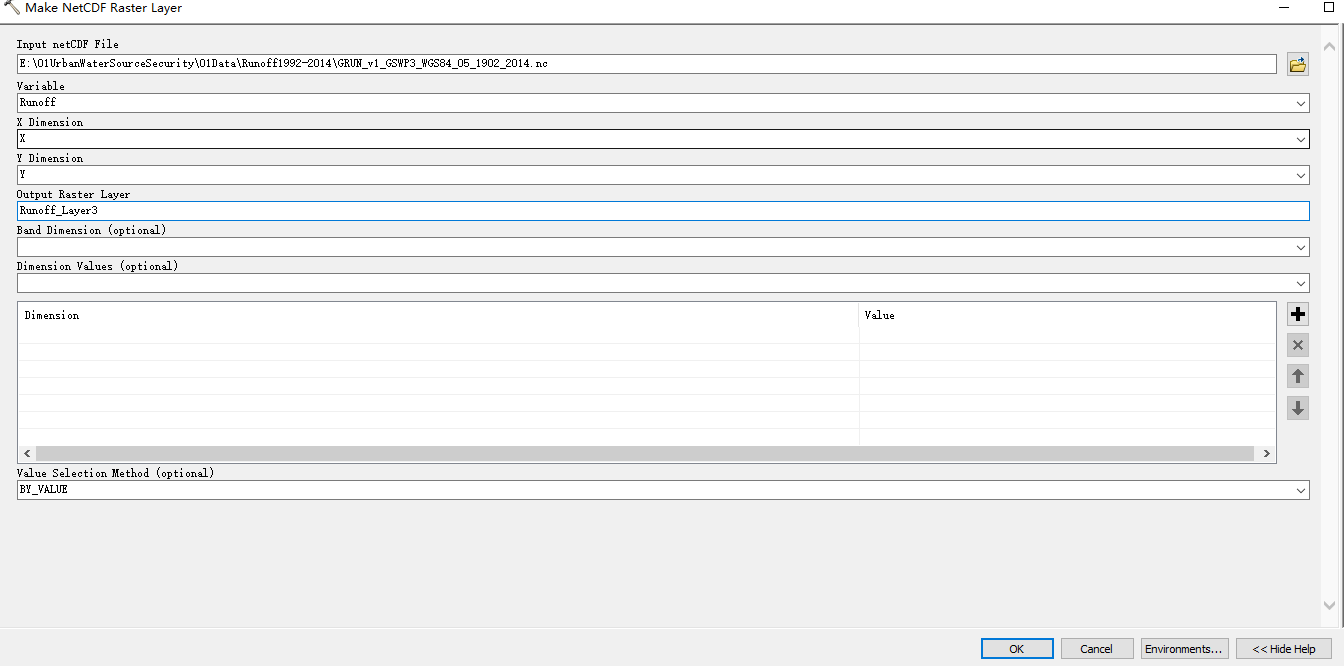
可以发现该数据有正确的像元大小、坐标系等
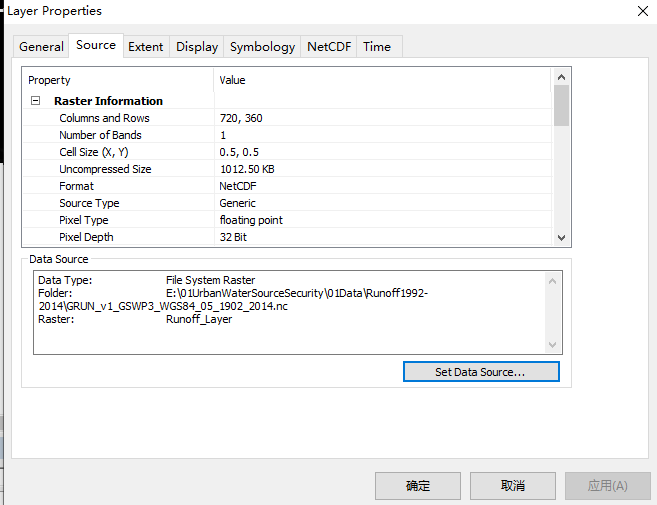

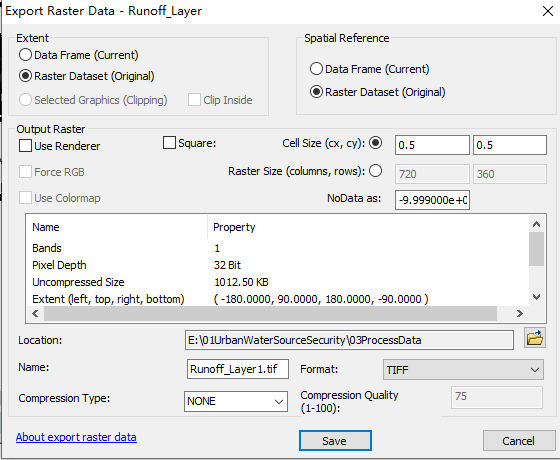
2.导出该数据作为标准数据
二、使用python批量提取所有数据
1. 查看数据属性
from netCDF4 import Dataset,num2date infile = "../01Data/Runoff1992-2014/GRUN_v1_GSWP3_WGS84_05_1902_2014.nc" data_set = Dataset(infile) # 读取nc文件信息 print(data_set)
输出为
<class 'netCDF4._netCDF4.Dataset'>
root group (NETCDF3_CLASSIC data model, file format NETCDF3):
title: GRUN
version: GRUN 1.0
meteorological_forcing: GSWP3
temporal_resolution: monthly
spatial_resolution: 0.5x0.5
crs: WGS84
proj4: +proj=longlat +ellps=WGS84 +datum=WGS84 +no_defs
EPSG: 4326
references: Ghiggi et al.,2019. GRUN: An observation-based global gridded runoff dataset from 1902 to 2014. ESSD, doi: https://doi.org/10.5194/essd-2019-32
authors: Gionata Ghiggi; Lukas Gudmundsson
contacts: gionata.ghiggi@gmail.com; lukas.gudmundsson@env.ethz.ch
institution: Land-Climate Dynamics, Institute for Atmospheric and Climate Science, ETH Zürich
institution_id: IAC ETHZ
dimensions(sizes): X(720), Y(360), time(1356)
variables(dimensions): float64 X(X), float64 Y(Y), float64 time(time), float32 Runoff(time, Y, X)
groups:
可以看到variables变量X、Y为经纬度,time为时间,Runoff为需要的结果
2.批量导出结果
from osgeo import gdal
from netCDF4 import Dataset,num2date
import numpy as np
def WriteTiff(im_data,inputdir, path):
raster = gdal.Open(inputdir)
im_width = raster.RasterXSize #栅格矩阵的列数
im_height = raster.RasterYSize #栅格矩阵的行数
im_bands = raster.RasterCount #波段数
im_geotrans = raster.GetGeoTransform()#获取仿射矩阵信息
im_proj = raster.GetProjection()#获取投影信息
if 'int8' in im_data.dtype.name:
datatype = gdal.GDT_Byte
elif 'int16' in im_data.dtype.name:
datatype = gdal.GDT_UInt16
else:
datatype = gdal.GDT_Float32
if len(im_data.shape) == 3:
im_bands, im_height, im_width = im_data.shape
elif len(im_data.shape) == 2:
im_data = np.array([im_data])
im_bands, (im_height, im_width) = 1, im_data.shape
# 创建文件
driver = gdal.GetDriverByName("GTiff")
dataset = driver.Create(path, im_width, im_height, im_bands, datatype)
if (dataset != None):
dataset.SetGeoTransform(im_geotrans) # 写入仿射变换参数
dataset.SetProjection(im_proj) # 写入投影
for i in range(im_bands):
dataset.GetRasterBand(i + 1).WriteArray(im_data[i])
del dataset
infile = "../01Data/Runoff1992-2014/GRUN_v1_GSWP3_WGS84_05_1902_2014.nc"
data_set = Dataset(infile) # 读取nc文件信息
time = data_set.variables["time"][:] # 获取时间一列
units = data_set.variables["time"].units # 获取第一期时间
#读取样本tif文件的地理信息
intif = "../03ProcessData/runoff_example.tif"
for i in range(0,len(time)):
yr = num2date(time[i],units).year # 提取年份
mon = num2date(time[i],units).month # 提取月份
value_data = data_set.variables['Runoff'][i]
# 将缺失值改为0
data = value_data.data
mask = value_data.mask
data[np.where(mask == True)] = 0
outputname = "../01Data/Runoff1992-2014/tif/" + str(yr) + str(mon).zfill(2) + ".tif"
WriteTiff(data,intif , outputname)
print(outputname)
!注意事项
1.使用时候请自行修改修改输入输出文件路径与变量名称
2.根据需要处理缺失值
到此这篇关于python的netCDF4批量处理NC格式文件的操作方法的文章就介绍到这了,更多相关python netCDF4处理NC格式文件内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python批量处理txt文件的实例代码
通过python对多个txt文件进行处理 读取路径,读取文件 获取文件名,路径名 对响应的文件夹名字进行排序 对txt文件内部的数据相应的某一列/某一行进行均值处理 写入到事先准备好的Excel文件中 关闭Excel文件 #import numpy as np import pandas as pd import os folder = 'D:/log/A190820C31N82' def all_files_in_a_folder_iter(folder): import os for roo
-
套娃式文件夹如何通过Python批量处理
前言 在我对项目组的一些训练图像进行预处理的时候,发现处理的图像是分好了类,在文件夹里的文件夹里,套娃式存储的,所以对我批处理,以及按原文件夹规则进行存储的时候,就会造成很大困扰 但通过下面几个函数的结合,帮我顺利的完成了一系列的预处理. 一.用不腻的芷山库 1.安装库 pip安装: pip install zisan 2.getFiles函数 函数调用: import zisan.FileTools as zf file_path = 'C:/Users/xxx/Desktop/2016/An
-
Python实现将数据写入netCDF4中的方法示例
本文实例讲述了Python实现将数据写入netCDF4中的方法.分享给大家供大家参考,具体如下: nc文件为处理气象数据文件.用户可以去https://www.lfd.uci.edu/~gohlke/pythonlibs/ 搜索netCDF4,下载相应平台的whl文件,使用pip安装即可. 这里演示的写入数据操作代码如下: # -*- coding:utf-8 -*- import numpy as np ''' 输入的data的shape=(627,652) ''' def write_to_
-

python中的netCDF4批量处理NC文件的操作方法
目录 一.使用ArcMap提取出第一期数据 1.使用工具箱中的“Make NetCDF Raster Layer”工具,提取出一个数据 2.导出该数据作为标准数据 二.使用python批量提取所有数据 1. 查看数据属性 2.批量导出结果 !注意事项 一.使用ArcMap提取出第一期数据 1.使用工具箱中的“Make NetCDF Raster Layer”工具,提取出一个数据 可以发现该数据有正确的像元大小.坐标系等 2.导出该数据作为标准数据 二.使用python批量提取所有数据 1. 查看
-
python的netCDF4批量处理NC格式文件的操作方法
目录 一.使用ArcMap提取出第一期数据 1.使用工具箱中的“Make NetCDF Raster Layer”工具,提取出一个数据 2.导出该数据作为标准数据 二.使用python批量提取所有数据 1. 查看数据属性 2.批量导出结果 !注意事项 一.使用ArcMap提取出第一期数据 1.使用工具箱中的“Make NetCDF Raster Layer”工具,提取出一个数据 可以发现该数据有正确的像元大小.坐标系等 2.导出该数据作为标准数据 二.使用python批量提取所有数据 1. 查看
-
python遍历文件目录、批量处理同类文件
本文实例为大家分享了python遍历文件目录.批量处理同类文件的具体代码,供大家参考,具体内容如下 目录操作 1.获取当前目录 import os curr_path=os.path.dirname(__file__) #返回当前文件所在的目录,即当前运行的脚本所在父目录 print curr_path 运行示例 (1)使用os.path.dirname(__file__)时,是针对运行时对所给程序脚本的路径来获取父目录的,即截取你输入的脚本路径的所在目录名称,如上图示例,输入绝对路径时返回绝对
-
python中利用h5py模块读取h5文件中的主键方法
如下所示: import h5py import numpy as np #HDF5的写入: imgData = np.zeros((2,4)) f = h5py.File('HDF5_FILE.h5','w') #创建一个h5文件,文件指针是f f['data'] = imgData #将数据写入文件的主键data下面 f['labels'] = np.array([1,2,3,4,5]) #将数据写入文件的主键labels下面 f.close() #关闭文件 #HDF5的读取: f = h5
-
在python中使用with打开多个文件的方法
虽然初恋是java, 可是最近是越来越喜欢python, 所以决定追根溯源好好了解下python的原理,架构等等.小脑袋瓜不太好使,只能记录下慢慢进步吧 使用with打开文件的好处不多说,这里记录一下如果要打开多个文件,该怎么书写简捷的代码. 场景是同时打开三个文件,文件行数一样,程序实现每个文件依次读取一行,同时输出. 首先来一种比较容易想到的写法,如下一样嵌套: with open('file1') as f1: with open('file2') as f2: with open('fi
-
Python中的pandas表格模块、文件模块和数据库模块
目录 一.Series数据结构 1.Series的创建 2.Series属性 2.Series缺失数据处理 二.DataFrame数据结构 1.DataFrame的创建 2.DataFrame属性 3.DataFrame取值 4.DataFrame值替换 5.处理丢失数据 6.合并数据 二.读取CSV文件 三.导入导出数据 1.读取文件导入数据 2.写入文件导出数据 3.实例 四.pandas读取json文件 五.pandas读取sql语句 pandas官方文档:https://pandas.p
-
Python中使用dom模块生成XML文件示例
在Python中解析XML文件也有Dom和Sax两种方式,这里先介绍如何是使用Dom解析XML,这一篇文章是Dom生成XML文件,下一篇文章再继续介绍Dom解析XML文件. 在生成XML文件中,我们主要使用下面的方法来完成. 主要方法 1.生成XML节点(node) 复制代码 代码如下: createElement("node_name") 2.给节点添加属性值(Attribute) 复制代码 代码如下: node.setAttribute("att_name",
-
Python中使用不同编码读写txt文件详解
复制代码 代码如下: import os import codecs filenames=os.listdir(os.getcwd()) out=file("name.txt","w") for filename in filenames: out.write(filename.decode("gb2312").encode("utf-8")) out.close() 将执行文件的当前目录及文件名写入到name.txt文件中
-
python中创建一个包并引用使用的操作方法
一.Python包 python包在开发中十分常见,一般通过导入包含特定功能的python模块包进行使用.当然,也可以自己创建打包模块,然后发布,安装使用. 1.安装包 在线安装包:pip install 包名:安装第三方包:python setup.py install (几乎每个python第三方包中都有这个setup.py文件,这个文件是作者打包时设置的文件,而安装第三方包时,也是要先进入到setup.py文件所在目录,然后执行python setup.py install) 2.dis
-
php中数据的批量导入(csv文件)
有时写程序时后台要求把大量数据导入数据库中,比如计算机考试成绩的查询.电话簿的数据等一般都是存放在excel中的,这时我们可把数据导出成csv文件,然后通过以下程序即可在后台批量导入数据到数据库中. 下面只是主要程序部分: <?php /***************************************************作者:冲星/arcow**************************njj@nuc.edu.cn*****************************