详解Go语言中关于包导入必学的 8 个知识点
1. 单行导入与多行导入
在 Go 语言中,一个包可包含多个 .go 文件(这些文件必须得在同一级文件夹中),只要这些 .go 文件的头部都使用 package 关键字声明了同一个包。
导入包主要可分为两种方式:
单行导入
import "fmt" import "sync"
多行导入
import( "fmt" "sync" )
如你所见,Go 语言中 导入的包,必须得用双引号包含,在这里吐槽一下。
2. 使用别名
在一些场景下,我们可能需要对导入的包进行重新命名,比如
我们导入了两个具有同一包名的包时产生冲突,此时这里为其中一个包定义别名
import ( "crypto/rand" mrand "math/rand" // 将名称替换为mrand避免冲突 )
我们导入了一个名字很长的包,为了避免后面都写这么长串的包名,可以这样定义别名
import hw "helloworldtestmodule"
防止导入的包名和本地的变量发生冲突,比如 path 这个很常用的变量名和导入的标准包冲突。
import pathpkg "path"
3. 使用点操作
如里在我们程序内部里频繁使用了一个工具包,比如 fmt,那每次使用它的打印函数打印时,都要 包名+方法名。
对于这种使用高频的包,可以在导入的时,就把它定义会 "自己人"(方法是使用一个 . ),自己人的话,不分彼此,它的方法,就是我们的方法。
从此,我们打印再也不用加 fmt 了。
import . "fmt"
func main() {
Println("hello, world")
}
但这种用法,会有一定的隐患,就是导入的包里可能有函数,会和我们自己的函数发生冲突。
4. 包的初始化
每个包都允许有一个 init 函数,当这个包被导入时,会执行该包的这个 init 函数,做一些初始化任务。
对于 init 函数的执行有两点需要注意
init 函数优先于 main 函数执行
在一个包引用链中,包的初始化是深度优先的。比如,有这样一个包引用关系:main→A→B→C,那么初始化顺序为
C.init→B.init→A.init→main
5. 包的匿名导入
当我们导入一个包时,如果这个包没有被使用到,在编译时,是会报错的。
但是有些情况下,我们导入一个包,只想执行包里的 init 函数,来运行一些初始化任务,此时怎么办呢?
可以使用匿名导入,用法如下,其中下划线为空白标识符,并不能被访问
// 注册一个PNG decoder import _ "image/png"
由于导入时,会执行 init 函数,所以编译时,仍然会将这个包编译到可执行文件中。
6. 导入的是路径还是包?
当我们使用 import 导入 testmodule/foo 时,初学者,经常会问,这个 foo 到底是一个包呢,还是只是包所在目录名?
import "testmodule/foo"
为了得出这个结论,专门做了个试验(请看「第七点里的代码示例」),最后得出的结论是:
导入时,是按照目录导入。导入目录后,可以使用这个目录下的所有包。
出于习惯,包名和目录名通常会设置成一样,所以会让你有一种你导入的是包的错觉。
7. 相对导入和绝对导入
据我了解在 Go 1.10 之前,好像是不支持相对导入的,在 Go 1.10 之后才可以。
绝对导入:从 $GOPATH/src 或 $GOROOT 或者 $GOPATH/pkg/mod 目录下搜索包并导入
相对导入:从当前目录中搜索包并开始导入。就像下面这样
import ( "./module1" "../module2" "../../module3" "../module4/module5" )
分别举个例子吧
一、使用绝对导入
有如下这样的目录结构(注意确保当前目录在 GOPATH 下)
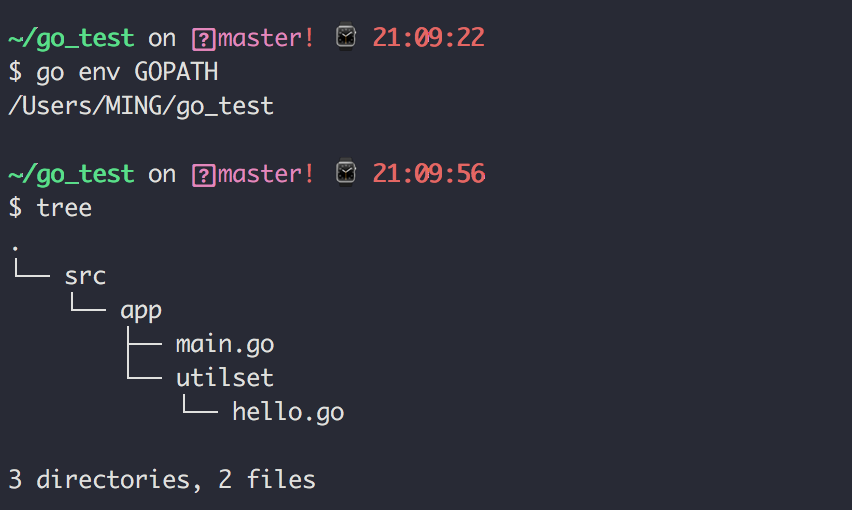
其中 main.go 是这样的
package main
import (
"app/utilset" // 这种使用的就是绝对路径导入
)
func main() {
utils.PrintHello()
}
而在 main.go 的同级目录下,还有另外一个文件夹 utilset ,为了让你理解 「第六点:import 导入的是路径而不是包」,我在 utilset 目录下定义了一个 hello.go 文件,这个go文件定义所属包为 utils。
package utils
import "fmt"
func PrintHello(){
fmt.Println("Hello, 我在 utilset 目录下的 utils 包里")
}
运行结果如下

二、使用相对导入
还是上面的代码,将绝对导入改为相对导入后
将 GOPATH 路径设置回去(请对比上面使用绝对路径的 GOPATH)

然后再次运行

总结一下,使用相对导入,有两点需要注意
项目不要放在 $GOPATH/src 下,否则会报错(比如我修改当前项目目录为GOPATH后,运行就会报错)
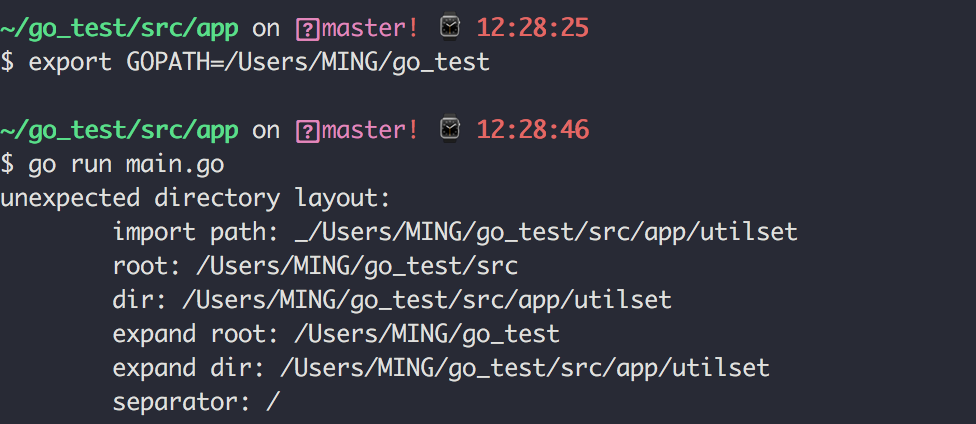
Go Modules 不支持相对导入,在你开启 GO111MODULE 后,无法使用相对导入。
最后,不得不说的是:使用相对导入的方式,项目可读性会大打折扣,不利用开发者理清整个引用关系。
所以一般更推荐使用绝对引用的方式。使用绝对引用的话,又要谈及优先级了
8. 包导入路径优先级
前面一节,介绍了三种不同的包依赖管理方案,不同的管理模式,存放包的路径可能都不一样,有的可以将包放在 GOPATH 下,有的可以将包放在 vendor 下,还有些包是内置包放在 GOROOT 下。
那么问题就来了,如果在这三个不同的路径下,有一个相同包名但是版本不同的包,我们导入的时候,是选择哪个进行导入呢?
这就需要我们搞懂,在 Golang 中包搜索路径优先级是怎样的?
这时候就需要区分,是使用哪种模式进行包的管理的。
如果使用 govendor
当我们导入一个包时,它会:
- 先从项目根目录的 vendor 目录中查找
- 最后从 $GOROOT/src 目录下查找
- 然后从 $GOPATH/src 目录下查找
- 都找不到的话,就报错。
为了验证这个过程,我在创建中创建一个 vendor 目录后,就开启了 vendor 模式了,我在 main.go 中随便导入一个包 pkg,由于这个包是我随便指定的,当然会找不到,找不到就会报错, Golang 会在报错信息中打印中搜索的过程,从这个信息中,就可以看到 Golang 的包查找优先级了。

如果使用 go modules
你导入的包如果有域名,都会先在 $GOPATH/pkg/mod 下查找,找不到就连网去该网站上寻找,找不到或者找到的不是一个包,则报错。
而如果你导入的包没有域名(比如 "fmt"这种),就只会到 $GOROOT 里查找。
还有一点很重要,当你的项目下有 vendor 目录时,不管你的包有没有域名,都只会在 vendor 目录中想找。
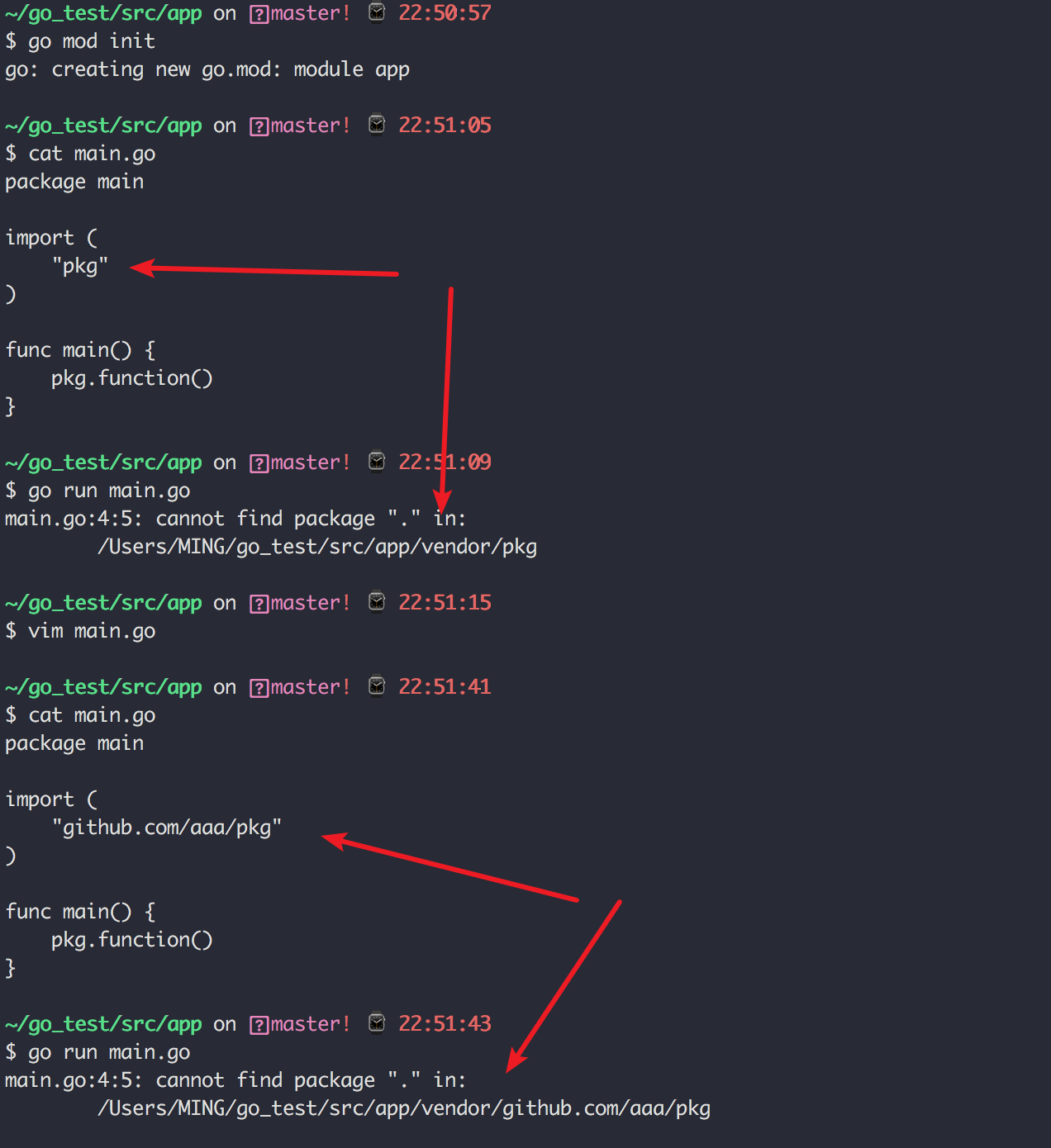
通常vendor 目录是通过 go mod vendor 命令生成的,这个命令会将项目依赖全部打包到你的项目目录下的 verdor 文件夹中。
延伸阅读如何使用go module导入本地包
到此这篇关于详解Go语言中关于包导入必学的 8 个知识点的文章就介绍到这了,更多相关Go语言 包导入内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Golang import 导入包语法及一些特殊用法详解
package 的导入语法 写 Go 代码的时经常用到 import 这个命令用来导入包,参考如下: import( "fmt" ) 然后在代码里面可以通过如下的方式调用: fmt.Println( "我爱我们" ) fmt 是 Go 的标准库,它其实是去 GOROOT 下去加载该模块,当然 Go 的 import 还支持如下两种方式来加载自己写的模块: 相对路径 import "./model" // 当前文件同一目录的 model 目录,但是
-
Golang import本地包和导入问题相关详解
1 本地包声明 包是Go程序的基本单位,所以每个Go程序源代码的开始都是一个包声明: package pkgName 这就是包声明,pkgName 告诉编译器,当前文件属于哪个包.一个包可以对应多个*.go源文件,标记它们属于同一包的唯一依据就是这个package声明,也就是说:无论多少个源文件,只要它们开头的package包相同,那么它们就属于同一个包,在编译后就只会生成一个.a文件,并且存放在$GOPATH/pkg文件夹下. 示例: (1) 我们在$GOPATH/目录下,创建如下结构的文件夹
-
对Golang import 导入包语法详解
package 的导入语法 写 Go 代码的时经常用到 import 这个命令用来导入包,参考如下: import( "fmt" ) 然后在代码里面可以通过如下的方式调用: fmt.Println( "我爱北京天安门" ) fmt 是 Go 的标准库,它其实是去 GOROOT 下去加载该模块,当然 Go 的 import 还支持如下两种方式来加载自己写的模块: 相对路径 import "./model" // 当前文件同一目录的 model 目录
-
使用go module导入本地包的方法教程详解
go module 是Go1.11版本之后官方推出的版本管理工具,并且从 Go1.13 版本开始, go module 将是Go语言默认的依赖管理工具.到今天 Go1.14 版本推出之后 Go modules 功能已经被正式推荐在生产环境下使用了. 这几天已经有很多教程讲解如何使用 go module ,以及如何使用 go module 导入gitlab私有仓库,我这里就不再啰嗦了.但是最近我发现很多小伙伴在群里问如何使用 go module 导入本地包,作为初学者大家刚开始接触package的
-
详解Go语言中关于包导入必学的 8 个知识点
1. 单行导入与多行导入 在 Go 语言中,一个包可包含多个 .go 文件(这些文件必须得在同一级文件夹中),只要这些 .go 文件的头部都使用 package 关键字声明了同一个包. 导入包主要可分为两种方式: 单行导入 import "fmt" import "sync" 多行导入 import( "fmt" "sync" ) 如你所见,Go 语言中 导入的包,必须得用双引号包含,在这里吐槽一下. 2. 使用别名 在一些场
-

详解R语言中生存分析模型与时间依赖性ROC曲线可视化
R语言简介 R是用于统计分析.绘图的语言和操作环境.R是属于GNU系统的一个自由.免费.源代码开放的软件,它是一个用于统计计算和统计制图的优秀工具. 人们通常使用接收者操作特征曲线(ROC)进行二元结果逻辑回归.但是,流行病学研究中感兴趣的结果通常是事件发生时间.使用随时间变化的时间依赖性ROC可以更全面地描述这种情况下的预测模型. 时间依赖性ROC定义 令 Mi为用于死亡率预测的基线(时间0)标量标记. 当随时间推移观察到结果时,其预测性能取决于评估时间 t.直观地说,在零时间测量的标记值应该
-
详解Go语言中的作用域和变量隐藏
目录 前言 包隐藏 全局变量 类型强制 闭包 := 的情况 总结 前言 变量隐藏在 Go 中可能会令人困惑,让我们尝试弄清楚. package main import ( "fmt" "io/ioutil" "log" ) func main() { f, err := ioutil.TempFile("", "") if err != nil { log.Fatal(err) } defer f.Clos
-
详解Go语言中配置文件使用与日志配置
目录 项目结构调整 配置文件使用 日志配置 小结 接着上一篇的文章构建的项目:Go语学习笔记 - 环境安装.接口测试 只是简单的把GET和POST接口的使用测试了一下. 我还是想按照正常的项目结构调整一下,这篇笔记主要是三个部分:调整项目目录结构.增加配置文件使用.增加日志配置,很常规而且也是每个项目都需要用到的. 项目地址:github地址 项目结构调整 说先对项目目录结构调整一下,按照我自己的开发习惯,增加了几个目录. 项目结构如下图: 解释一下目录结构 app/constants:主要放置
-
详解Java语言中的抽象类与继承
目录 一.实验目的 二.实验要求 三.实验报告要求 四.实验小结 一.实验目的 1.掌握抽象类的设计: 2.掌握抽象方法方法的实现: 3.熟悉类的向下向上转型,以及子类实例化父类对象的基本要求: 4.掌握通过类的继承实现抽象类. 二.实验要求 (一)编写一个Shape抽象类,其中包含有: 1个成员变量:表示长度,数据类型为double.当类为Circle时,表示半径:当类为Square时,表示其边长: 2个抽象方法area().perimeter(),分别用于计算图形的面积.周长. public
-
详解Go语言中结构体与JSON间的转换
目录 前言 结构体转 JSON JSON 解析结构体 小结 前言 在日常开发中,我们往往会将 JSON 解析成对应的结构体,反之也会将结构体转成 JSON.接下来本文会通过 JSON 包的两个函数,来介绍 JSON 与结构体之间的转换. 结构体转 JSON Marshal(v any) ([]byte, error):将 v 转成 JSON 数据,以 []byte 的形式返回. import ( "encoding/json" "fmt" ) type User s
-
详解R语言中的多项式回归、局部回归、核平滑和平滑样条回归模型
在标准线性模型中,我们假设 .当线性假设无法满足时,可以考虑使用其他方法. 多项式回归 扩展可能是假设某些多项式函数, 同样,在标准线性模型方法(使用GLM的条件正态分布)中,参数 可以使用最小二乘法获得,其中 在 . 即使此多项式模型不是真正的多项式模型,也可能仍然是一个很好的近似值 .实际上,根据 Stone-Weierstrass定理,如果 在某个区间上是连续的,则有一个统一的近似值 ,通过多项式函数. 仅作说明,请考虑以下数据集 db = data.frame(x=xr,y=y
-
详解R语言中的表达式、数学公式、特殊符号
在R语言的绘图函数中,如果文本参数是合法的R语言表达式,那么这个表达式就被用Tex类似的规则进行文本格式化. y <- function(x) (exp(-(x^2)/2))/sqrt(2*pi) plot(y, -5, 5, main = expression(f(x) == frac(1,sqrt(2*pi))*e^(-frac(x^2,2))), lwd = 3, col = "blue") library(ggplot2) x <- seq(0, 2*pi, b
-
详解C语言中不同类型的数据转换规则
不同类型数据间的混合运算与类型转换 1.自动类型转换 在C语言中,自动类型转换遵循以下规则: ①若参与运算量的类型不同,则先转换成同一类型,然后进行运算 ②转换按数据长度增加的方向进行,以保证精度不降低.如int型和long型运算时,先把int量转成long型后再进行运算 a.若两种类型的字节数不同,转换成字节数高的类型 b.若两种类型的字节数相同,且一种有符号,一种无符号,则转换成无符号类型 ③所有的浮点运算都是以双精度进行的,即使是两个float单精度量运算的表达式,也要先转换成double
-
详解C语言中二分查找的运用技巧
目录 基础的二分查 查找左侧边界 查找右侧边界 二分查找问题分析 实例1: 爱吃香蕉的珂珂 实例2:运送包裹 前篇文章聊到了二分查找的基础以及细节的处理问题,主要介绍了 查找和目标值相等的元素.查找第一个和目标值相等的元素.查找最后一个和目标值相等的元素 三种情况. 这些情况都适用于有序数组中查找指定元素 这个基本的场景,但实际应用中可能不会这么直接,甚至看了题目之后,都不会想到可以用二分查找算法来解决 . 本文就来分析下二分查找在实际中的应用,通过分析几个应用二分查找的实例,总结下能使用二分查