详解Pytorch显存动态分配规律探索
下面通过实验来探索Pytorch分配显存的方式。
实验显存到主存
我使用VSCode的jupyter来进行实验,首先只导入pytorch,代码如下:
import torch
打开任务管理器查看主存与显存情况。情况分别如下:


在显存中创建1GB的张量,赋值给a,代码如下:
a = torch.zeros([256,1024,1024],device= 'cpu')
查看主存与显存情况:


可以看到主存与显存都变大了,而且显存不止变大了1G,多出来的内存是pytorch运行所需的一些配置变量,我们这里忽略。
再次在显存中创建一个1GB的张量,赋值给b,代码如下:
b = torch.zeros([256,1024,1024],device= 'cpu')
查看主显存情况:

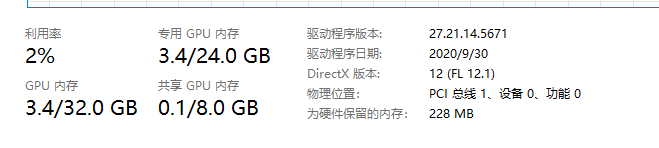
这次主存大小没变,显存变高了1GB,这是合情合理的。然后我们将b移动到主存中,代码如下:
b = b.to('cpu')
查看主显存情况:


发现主存是变高了1GB,显存却只变小了0.1GB,好像只是将显存张量复制到主存一样。实际上,pytorch的确是复制了一份张量到主存中,但它也对显存中这个张量的移动进行了记录。我们接着执行以下代码,再创建1GB的张量赋值给c:
c = torch.zeros([256,1024,1024],device= 'cuda')
查看主显存情况:


发现只有显存大小变大了0.1GB,这说明,Pytorch的确记录了显存中张量的移动,只是没有立即将显存空间释放,它选择在下一次创建新变量时覆盖这个位置。接下来,我们重复执行上面这行代码:
c = torch.zeros([256,1024,1024],device= 'cuda')
主显存情况如下:


明明我们把张量c给覆盖了,显存内容却变大了,这是为什么呢?实际上,Pytorch在执行这句代码时,是首先找到可使用的显存位置,创建这1GB的张量,然后再赋值给c。但因为在新创建这个张量时,原本的c依然占有1GB的显存,pytorch只能先调取另外1GB显存来创建这个张量,再将这个张量赋值给c。这样一来,原本的那个c所在的显存内容就空出来了,但和前面说的一样,pytorch并不会立即释放这里的显存,而等待下一次的覆盖,所以显存大小并没有减小。
我们再创建1GB的d张量,就可以验证上面的猜想,代码如下:
d = torch.zeros([256,1024,1024],device= 'cuda')
主显存情况如下:


显存大小并没有变,就是因为pytorch将新的张量创建在了上一步c空出来的位置,然后再赋值给了d。另外,删除变量操作也同样不会立即释放显存:
del d
主显存情况:


显存没有变化,同样是等待下一次的覆盖。
主存到显存
接着上面的实验,我们创建直接在主存创建1GB的张量并赋值给e,代码如下:
e = torch.zeros([256,1024,1024],device= 'cpu')
主显存情况如下:


主存变大1GB,合情合理。然后将e移动到显存,代码如下:
e = e.to('cuda')
主显存情况如下:


主存变小1GB,显存没变是因为上面张量d被删除没有被覆盖,合情合理。说明主存的释放是立即执行的。
总结
通过上面的实验,我们了解到,pytorch不会立即释放显存中失效变量的内存,它会以覆盖的方式利用显存中的可用空间。另外,如果要重置显存中的某个规模较大的张量,最好先将它移动到主存中,或是直接删除,再创建新值,否则就需要两倍的内存来实现这个操作,就有可能出现显存不够用的情况。
实验代码汇总如下:
#%%
import torch
#%%
a = torch.zeros([256,1024,1024],device= 'cuda')
#%%
b = torch.zeros([256,1024,1024],device= 'cuda')
#%%
b = b.to('cpu')
#%%
c = torch.zeros([256,1024,1024],device= 'cuda')
#%%
c = torch.zeros([256,1024,1024],device= 'cuda')
#%%
d = torch.zeros([256,1024,1024],device= 'cuda')
#%%
del d
#%%
e = torch.zeros([256,1024,1024],device= 'cpu')
#%%
e = e.to('cuda')
到此这篇关于Pytorch显存动态分配规律探索的文章就介绍到这了,更多相关Pytorc显存分配规律内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch释放显存占用方式
如果在python内调用pytorch有可能显存和GPU占用不会被自动释放,此时需要加入如下代码 torch.cuda.empty_cache() 我们来看一下官方文档的说明 Releases all unoccupied cached memory currently held by the caching allocator so that those can be used in other GPU application and visible in nvidia-smi. Note e
-
解决Pytorch 训练与测试时爆显存(out of memory)的问题
Pytorch 训练时有时候会因为加载的东西过多而爆显存,有些时候这种情况还可以使用cuda的清理技术进行修整,当然如果模型实在太大,那也没办法. 使用torch.cuda.empty_cache()删除一些不需要的变量代码示例如下: try: output = model(input) except RuntimeError as exception: if "out of memory" in str(exception): print("WARNING: out of
-
Pytorch GPU显存充足却显示out of memory的解决方式
今天在测试一个pytorch代码的时候显示显存不足,但是这个网络框架明明很简单,用CPU跑起来都没有问题,GPU却一直提示out of memory. 在网上找了很多方法都行不通,最后我想也许是pytorch版本的问题,原来我的pytorch版本是0.4.1,于是我就把这个版本卸载,然后安装了pytorch1.1.0,程序就可以神奇的运行了,不会再有OOM的提示了.虽然具体原因还不知道为何,这里还是先mark一下,具体过程如下: 卸载旧版本pytorch: conda uninstall pyt
-
详解Pytorch显存动态分配规律探索
下面通过实验来探索Pytorch分配显存的方式. 实验显存到主存 我使用VSCode的jupyter来进行实验,首先只导入pytorch,代码如下: import torch 打开任务管理器查看主存与显存情况.情况分别如下: 在显存中创建1GB的张量,赋值给a,代码如下: a = torch.zeros([256,1024,1024],device= 'cpu') 查看主存与显存情况: 可以看到主存与显存都变大了,而且显存不止变大了1G,多出来的内存是pytorch运行所需的一些配置变量,我们这
-
详解pytorch tensor和ndarray转换相关总结
在使用pytorch的时候,经常会涉及到两种数据格式tensor和ndarray之间的转换,这里总结一下两种格式的转换: 1. tensor cpu 和tensor gpu之间的转化: tensor cpu 转为tensor gpu: tensor_gpu = tensor_cpu.cuda() >>> tensor_cpu = torch.ones((2,2)) tensor([[1., 1.], [1., 1.]]) >>> tensor_gpu = tensor_
-
详解pytorch中squeeze()和unsqueeze()函数介绍
squeeze的用法主要就是对数据的维度进行压缩或者解压. 先看torch.squeeze() 这个函数主要对数据的维度进行压缩,去掉维数为1的的维度,比如是一行或者一列这种,一个一行三列(1,3)的数去掉第一个维数为一的维度之后就变成(3)行.squeeze(a)就是将a中所有为1的维度删掉.不为1的维度没有影响.a.squeeze(N) 就是去掉a中指定的维数为一的维度.还有一种形式就是b=torch.squeeze(a,N) a中去掉指定的定的维数为一的维度. 再看torch.unsque
-

弄清Pytorch显存的分配机制
对于显存不充足的炼丹研究者来说,弄清楚Pytorch显存的分配机制是很有必要的.下面直接通过实验来推出Pytorch显存的分配过程. 实验实验代码如下: import torch from torch import cuda x = torch.zeros([3,1024,1024,256],requires_grad=True,device='cuda') print("1", cuda.memory_allocated()/1024**2) y = 5 * x print(&quo
-
pytorch显存一直变大的解决方案
在代码中添加以下两行可以解决: torch.backends.cudnn.enabled = True torch.backends.cudnn.benchmark = True 补充:pytorch训练过程显存一直增加的问题 之前遇到了爆显存的问题,卡了很久,试了很多方法,总算解决了. 总结下自己试过的几种方法: **1. 使用torch.cuda.empty_cache() 在每一个训练epoch后都添加这一行代码,可以让训练从较低显存的地方开始,但并不适用爆显存的问题,随着epoch的增加
-
详解pytorch的多GPU训练的两种方式
目录 方法一:torch.nn.DataParallel 1. 原理 2. 常用的配套代码如下 3. 优缺点 方法二:torch.distributed 1. 代码说明 方法一:torch.nn.DataParallel 1. 原理 如下图所示:小朋友一个人做4份作业,假设1份需要60min,共需要240min. 这里的作业就是pytorch中要处理的data. 与此同时,他也可以先花3min把作业分配给3个同伙,大家一起60min做完.最后他再花3min把作业收起来,一共需要66min. 这个
-
详解滑动穿透(锁body)终极探索
场景 当页面出现浮层的时候,滑动浮层的内容,正常情况下预期应该是浮层下边的内容不会滚动:然而事实并非如此. 如图所示,浮层下边的内容并没有如想象中不受影响. 解决 先去github上搜索一番,发现有解决此问题的开源包,简单粗暴直接挑选了其中star的最高的(body-scroll-lock)操作一番! 使用后发现有一些问题: 安卓端全挂 ios端偶尔会有锁不住的情况 查源码发现该包在iOS端使用禁止touchmove的方式单独处理,但是在其他端只是给body加overflow: hidden简单
-
详解Pytorch中的tensor数据结构
目录 torch.Tensor Tensor 数据类型 view 和 reshape 的区别 Tensor 与 ndarray 创建 Tensor 传入维度的方法 torch.Tensor torch.Tensor 是一种包含单一数据类型元素的多维矩阵,类似于 numpy 的 array.Tensor 可以使用 torch.tensor() 转换 Python 的 list 或序列数据生成,生成的是dtype 默认是 torch.FloatTensor. 注意 torch.tensor() 总是
-
详解PyTorch批训练及优化器比较
一.PyTorch批训练 1. 概述 PyTorch提供了一种将数据包装起来进行批训练的工具--DataLoader.使用的时候,只需要将我们的数据首先转换为torch的tensor形式,再转换成torch可以识别的Dataset格式,然后将Dataset放入DataLoader中就可以啦. import torch import torch.utils.data as Data torch.manual_seed(1) # 设定随机数种子 BATCH_SIZE = 5 x = torch.li
-
详解pytorch 0.4.0迁移指南
总说 由于pytorch 0.4版本更新实在太大了, 以前版本的代码必须有一定程度的更新. 主要的更新在于 Variable和Tensor的合并., 当然还有Windows的支持, 其他一些就是支持scalar tensor以及修复bug和提升性能吧. Variable和Tensor的合并导致以前的代码会出错, 所以需要迁移, 其实迁移代价并不大. Tensor和Variable的合并 说是合并, 其实是按照以前(0.1-0.3版本)的观点是: Tensor现在默认requires_grad=F