手把手教你Python抓取数据并可视化
目录
- 前言
- 一、数据抓取篇
- 1.简单的构建反爬措施
- 2.解析数据
- 3.完整代码
- 二、数据可视化篇
- 1.数据可视化库选用
- 2.案例实战
- (1).柱状图Bar
- (2).地图Map
- (3).饼图Pie
- (4).折线图Line
- (5).组合图表
- 总结
前言
大家好,这次写作的目的是为了加深对数据可视化pyecharts的认识,也想和大家分享一下。如果下面文章中有错误的地方还请指正,哈哈哈!!!
本次主要用到的第三方库:
- requests
- pandas
- pyecharts

之所以数据可视化选用pyecharts,是因为它含有丰富的精美图表,地图,也可轻松集成至 Flask,Django 等主流 Web 框架中,并且在html渲染网页时把图片保存下来(这里好像截屏就可以了,),任君挑选!!!
这次的数据采集是从招聘网址上抓取到的python招聘岗位信息,嗯……其实这抓取到的数据有点少(只有1200条左右,也没办法,岗位太少了…),所以在后面做可视化图表的时候会导致不好看,骇。本来也考虑过用java(数据1万+)的数据来做测试的,但是想到写的是python,所以也就只能将就用这个数据了,当然如果有感兴趣的朋友,你们可以用java,前端这些岗位的数据来做测试,下面提供的数据抓取方法稍微改一下就可以抓取其它岗位了。
好了,废话不多说,直接开始吧!
一、数据抓取篇
1.简单的构建反爬措施
这里为大家介绍一个很好用的网站,可以帮助我们在写爬虫时快速构建请求头、cookie这些。但是这个网站也不知为什么,反正在访问时也经常访问不了!额……,介绍下它的使用吧!首先,我们只需要根据下面图片上步骤一样。
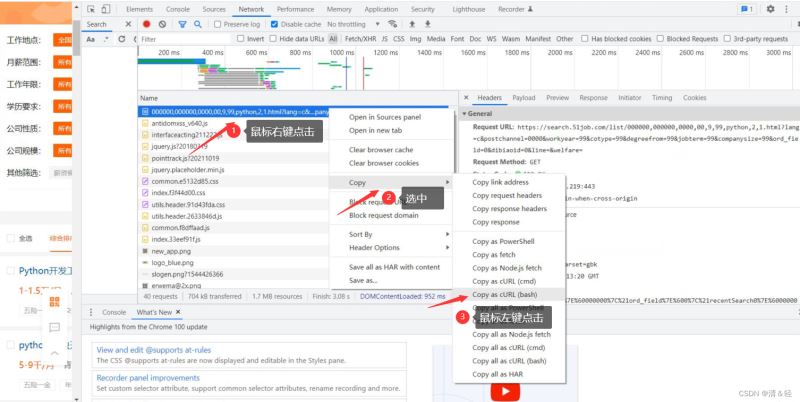
完成之后,我们就复制好了请求头里面的内容了,然后打开网址https://curlconverter.com/进入后直接在输入框里Ctrl+v粘贴即可。然后就会在下面解析出内容,我们直接复制就完成了,快速,简单,哈哈哈。

2.解析数据
这里我们请求网址得到的数据它并没有在html元素标签里面,所以就不能用lxml,css选择器等这些来解析数据。这里我们用re正则来解析数据,得到的数据看到起来好像字典类型,但是它并不是,所以我们还需要用json来把它转化成字典类型的数据方便我们提取。


这里用json转化为字典类型的数据后,不好查看时,可以用pprint来打印查看。
import pprint pprint.pprint(parse_data_dict)
3.完整代码
import requests
import re
import json
import csv
import time
from random import random
from fake_useragent import UserAgent
def spider_python(key_word):
headers = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,image/apng,*/*;q=0.8,application/signed-exchange;v=b3;q=0.9',
'Accept-Language': 'zh-CN,zh;q=0.9',
'Cache-Control': 'no-cache',
'Connection': 'keep-alive',
'Pragma': 'no-cache',
'Sec-Fetch-Dest': 'document',
'Sec-Fetch-Mode': 'navigate',
'Sec-Fetch-Site': 'same-origin',
'Sec-Fetch-User': '?1',
'Upgrade-Insecure-Requests': '1',
'User-Agent': UserAgent().Chrome,
'sec-ch-ua': '" Not A;Brand";v="99", "Chromium";v="100", "Google Chrome";v="100"',
'sec-ch-ua-mobile': '?0',
'sec-ch-ua-platform': '"Windows"',
}
params = {
'lang': 'c',
'postchannel': '0000',
'workyear': '99',
'cotype': '99',
'degreefrom': '99',
'jobterm': '99',
'companysize': '99',
'ord_field': '0',
'dibiaoid': '0',
'line': '',
'welfare': '',
}
save_time = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime()).replace(' ', '_').replace(':','_')
file_path = f'./testDataPython-{save_time}.csv'
f_csv = open(file_path, mode='w', encoding='utf-8', newline='')
fieldnames = ['公司名字', '职位名字', '薪资', '工作地点',
'招聘要求', '公司待遇','招聘更新时间', '招聘发布时间',
'公司人数', '公司类型', 'companyind_text', 'job_href', 'company_href']
dict_write = csv.DictWriter(f_csv, fieldnames=fieldnames)
dict_write.writeheader()
page = 0 #页数
error_time = 0 #在判断 职位名字中是否没有关键字的次数,这里定义出现200次时,while循环结束
# (因为在搜索岗位名字时(如:搜索python),会在网站20多页时就没有关于python的岗位了,但是仍然有其它的岗位出现,所以这里就需要if判断,使其while循环结束)
flag = True
while flag:
page += 1
print(f'第{page}抓取中……')
try:
time.sleep(random()*3) #这里随机休眠一下,简单反爬处理,反正我们用的是单线程爬取,也不差那一点时间是吧
url='这里你们自己构建url吧,从上面的图片应该能看出,我写出来的话实在是不行,过不了审核,难受!!!'
###这里还是要添加cookies的好,我们要伪装好不是?防止反爬,如果你用上面提供的方法,也就很快的构建出cookies。
response = requests.get(url=url,params=params, headers=headers)
except:
print(f'\033[31m第{page}请求异常!033[0m')
flag = False
parse_data = re.findall('"engine_jds":(.*?),"jobid_count"',response.text)
parse_data_dict = json.loads(parse_data[0])
# import pprint
# pprint.pprint(parse_data_dict)
# exit()
for i in parse_data_dict:
###在这里要处理下异常,因为在爬取多页时,可能是网站某些原因会导致这里的结构变化
try:
companyind_text = i['companyind_text']
except Exception as e:
print(f'\033[31m异常:{e}033[0m')
companyind_text = None
dic = {
'公司名字': i['company_name'],
'职位名字': i['job_name'],
'薪资': i['providesalary_text'],
'工作地点': i['workarea_text'],
'招聘要求': ' '.join(i['attribute_text']),
'公司待遇': i['jobwelf'],
'招聘更新时间': i['updatedate'],
'招聘发布时间': i['issuedate'],
'公司人数': i['companysize_text'],
'公司类型': i['companytype_text'],
'companyind_text': companyind_text,
'job_href': i['job_href'],
'company_href': i['company_href'],
}
if 'Python' in dic['职位名字'] or 'python' in dic['职位名字']:
dict_write.writerow(dic)
print(dic['职位名字'], '——保存完毕!')
else:
error_time += 1
if error_time == 200:
flag = False
print('抓取完成!')
f_csv.close()
if __name__ == '__main__':
key_word = 'python'
# key_word = 'java' ##这里不能输入中文,网址做了url字体加密,简单的方法就是直接从网页url里面复制下来用(如:前端)
# key_word = '%25E5%2589%258D%25E7%25AB%25AF' #前端
spider_python(key_word)
二、数据可视化篇
1.数据可视化库选用
本次数据可视化选用的是pyecharts第三方库,它制作图表是多么的强大与精美!!!想要对它进行一些简单地了解话可以前往这篇博文:
https://www.jb51.net/article/247122.htm
安装: pip install pyecharts
2.案例实战
本次要对薪资、工作地点、招聘要求里面的经验与学历进行数据处理并可视化。

(1).柱状图Bar
按住鼠标中间滑轮或鼠标左键可进行调控。

import pandas as pd
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
###柱状图
from pyecharts.charts import Bar
c = (
Bar()
.add_xaxis(city.index.tolist()) #城市列表数据项
.add_yaxis("Python", city.values.tolist())#城市对应的岗位数量列表数据项
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位所在城市分布情况"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
xaxis_opts=opts.AxisOpts(name='城市'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='岗位数量'), # 设置y轴名字属性
)
.render("bar_datazoom_both.html")
)
(2).地图Map
省份
这里对所在省份进行可视化。

import pandas as pd
import copy
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data_deepcopy = copy.deepcopy(python_data) #深复制一份数据
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
city_list = [list(ct) for ct in city.items()]
def province_city():
'''这是从接口里爬取的数据(不太准,但是误差也可以忽略不计!)'''
area_data = {}
with open('./中国省份_城市.txt', mode='r', encoding='utf-8') as f:
for line in f:
line = line.strip().split('_')
area_data[line[0]] = line[1].split(',')
province_data = []
for ct in city_list:
for k, v in area_data.items():
for i in v:
if ct[0] in i:
ct[0] = k
province_data.append(ct)
area_data_deepcopy = copy.deepcopy(area_data)
for k in area_data_deepcopy.keys():
area_data_deepcopy[k] = 0
for i in province_data:
if i[0] in area_data_deepcopy.keys():
area_data_deepcopy[i[0]] = area_data_deepcopy[i[0]] +i[1]
province_data = [[k,v]for k,v in area_data_deepcopy.items()]
best = max(area_data_deepcopy.values())
return province_data,best
province_data,best = province_city()
#地图_中国地图(带省份)Map-VisualMap(连续型)
c2 = (
Map()
.add( "Python",province_data, "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位——全国分布情况"),
visualmap_opts=opts.VisualMapOpts(max_=int(best / 2)),
)
.render("map_china.html")
)
这是 中国省份_城市.txt 里面的内容,通过[接口]抓取到的中国地区信息。

源码:
import requests
import json
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36",
}
response = requests.get('https://j.i8tq.com/weather2020/search/city.js',headers=header)
result = json.loads(response.text[len('var city_data ='):])
print(result)
each_province_data = {}
f = open('./中国省份_城市.txt',mode='w',encoding='utf-8')
for k,v in result.items():
province = k
if k in ['上海', '北京', '天津', '重庆']:
city = ','.join(list(v[k].keys()))
else:
city = ','.join(list(v.keys()))
f.write(f'{province}_{city}\n')
each_province_data[province] = city
f.close()
print(each_province_data)
城市
这里对所在城市进行可视化。

import pandas as pd
import copy
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data_deepcopy = copy.deepcopy(python_data) #深复制一份数据
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
city_list = [list(ct) for ct in city.items()]
###地图_中国地图(带城市)——Map-VisualMap(分段型)
from pyecharts.charts import Map
c1 = (
Map(init_opts=opts.InitOpts(width="1244px", height="700px",page_title='Map-中国地图(带城市)', bg_color="#f4f4f4"))
.add(
"Python",
city_list,
"china-cities", #地图
label_opts=opts.LabelOpts(is_show=False),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位——全国分布情况"),
visualmap_opts=opts.VisualMapOpts(max_=city_list[0][1],is_piecewise=True),
)
.render("map_china_cities.html")
)
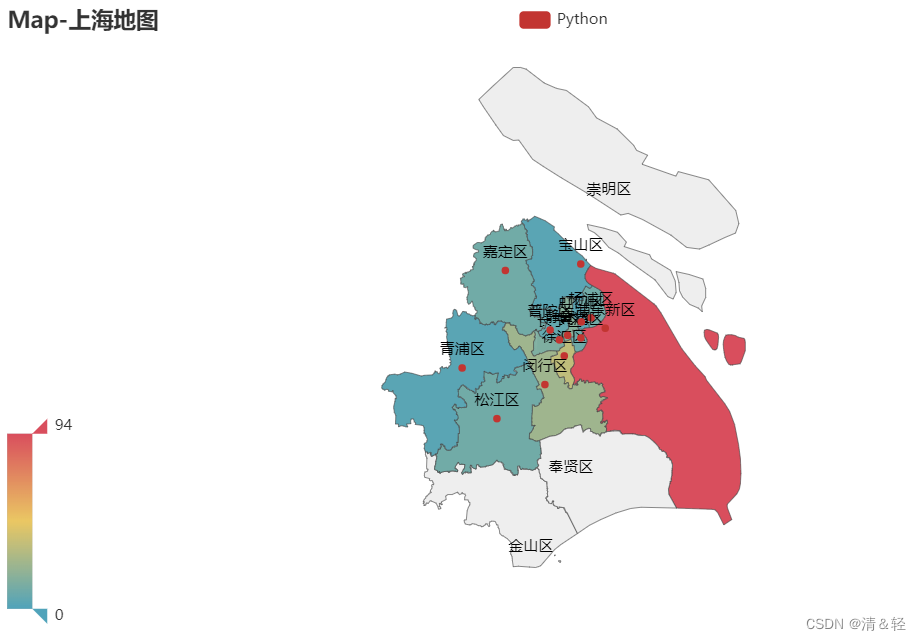
地区
这里对上海地区可视化。
import pandas as pd
import copy
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data_deepcopy = copy.deepcopy(python_data) #深复制一份数据
shanghai_data = []
sh = shanghai_data.append
for i in python_data_deepcopy['工作地点']:
if '上海' in i:
if len(i.split('-')) > 1:
sh(i.split('-')[1])
shanghai_data = pd.Series(shanghai_data).value_counts()
shanghai_data_list = [list(sh) for sh in shanghai_data.items()]
#上海地图
c3 = (
Map()
.add("Python", shanghai_data_list, "上海") ###这个可以更改地区(如:成都)这里改了的话,上面的数据处理也要做相应的更改
.set_global_opts(
title_opts=opts.TitleOpts(title="Map-上海地图"),
visualmap_opts=opts.VisualMapOpts(max_=shanghai_data_list[0][1])
)
.render("map_shanghai.html")
)
(3).饼图Pie
Pie1
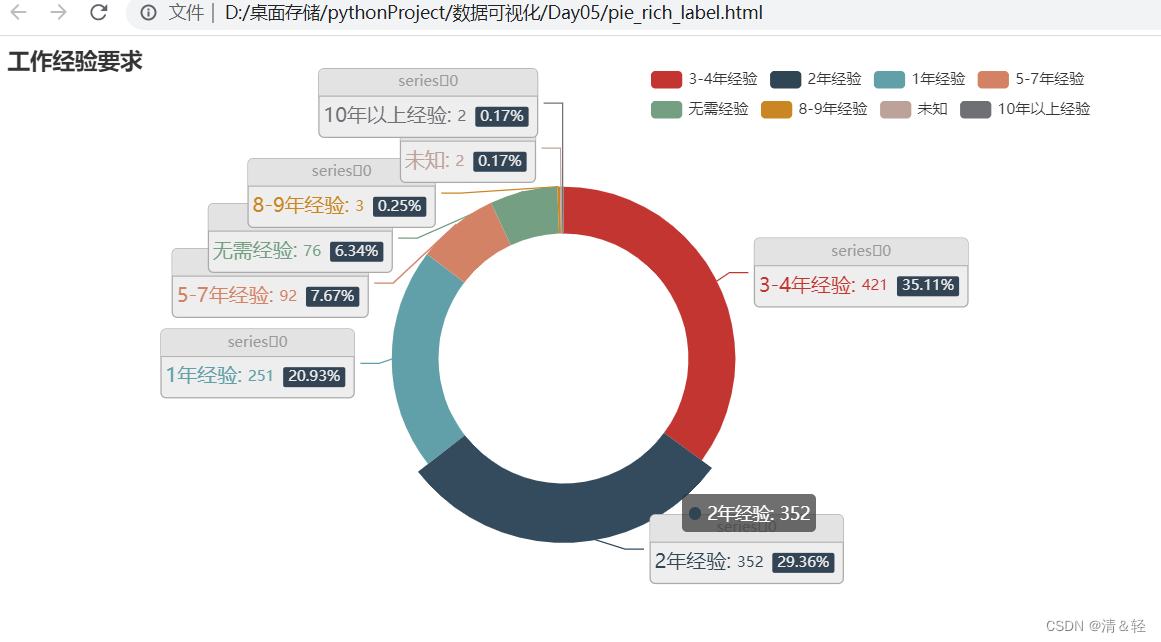
from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
require_list = []
rl = require_list.append
for i in python_data['招聘要求']:
if '经验' in i:
rl(i.split(' ')[1])
else:
rl('未知')
python_data['招聘要求'] = require_list
require = python_data['招聘要求'].value_counts()
require_list = [list(ct) for ct in require.items()]
print(require_list)
c = (
Pie()
.add(
"",
require_list,
radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="工作经验要求"),
legend_opts=opts.LegendOpts(padding=20, pos_left=500),
)
.render("pie_rich_label.html")
)
Pie2

from pyecharts import options as opts
from pyecharts.charts import Pie
import pandas as pd
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
xueli_list = []
xl = xueli_list.append
for i in python_data['招聘要求']:
if len(i.split(' ')) == 3:
xl(i.split(' ')[2])
else:
xl('未知')
python_data['招聘要求'] = xueli_list
xueli_require = python_data['招聘要求'].value_counts()
xueli_require_list = [list(ct) for ct in xueli_require.items()]
c = (
Pie()
.add(
"",
xueli_require_list,
radius=["30%", "55%"],
rosetype="area",
)
.set_global_opts(title_opts=opts.TitleOpts(title="学历要求"))
.render("pie_rosetype.html")
)
(4).折线图Line
这里对薪资情况进行可视化。

import pandas as pd
import re
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
sal = python_data['薪资']
xin_zi1 = []
xin_zi2 = []
xin_zi3 = []
xin_zi4 = []
xin_zi5 = []
xin_zi6 = []
for s in sal:
s = str(s)
if '千' in s:
xin_zi1.append(s)
else:
if re.findall('-(.*?)万',s):
s = float(re.findall('-(.*?)万',s)[0])
if 1.0<s<=1.5:
xin_zi2.append(s)
elif 1.5<s<=2.5:
xin_zi3.append(s)
elif 2.5<s<=3.2:
xin_zi4.append(s)
elif 3.2<s<=4.0:
xin_zi5.append(s)
else:
xin_zi6.append(s)
xin_zi = [['<10k',len(xin_zi1)],['10~15k',len(xin_zi2)],['15<25k',len(xin_zi3)],
['25<32k',len(xin_zi4)],['32<40k',len(xin_zi5)],['>40k',len(xin_zi6),]]
import pyecharts.options as opts
from pyecharts.charts import Line
x, y =[i[0] for i in xin_zi],[i[1] for i in xin_zi]
c2 = (
Line()
.add_xaxis(x)
.add_yaxis(
"Python",
y,
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="max", coord=[x[2], y[2]], value=y[2])] #name='自定义标记点'
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="薪资情况"),
xaxis_opts=opts.AxisOpts(name='薪资范围'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='数量'), # 设置y轴名字属性
)
.render("line_markpoint_custom.html")
)
(5).组合图表
最后,将多个html上的图表进行合并成一个html图表。
首先,我们执行下面这串格式的代码(只写了四个图表,自己做相应添加即可)
import pandas as pd
from pyecharts.charts import Bar,Map,Pie,Line,Page
from pyecharts import options as opts
python_data = pd.read_csv('./testDataPython-2022-05-01_11_48_36.csv')
python_data['工作地点'] = [i.split('-')[0] for i in python_data['工作地点']]
city = python_data['工作地点'].value_counts()
city_list = [list(ct) for ct in city.items()]
###柱状图
def bar_datazoom_slider() -> Bar:
c = (
Bar()
.add_xaxis(city.index.tolist()) #城市列表数据项
.add_yaxis("Python", city.values.tolist())#城市对应的岗位数量列表数据项
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位所在城市分布情况"),
datazoom_opts=[opts.DataZoomOpts(), opts.DataZoomOpts(type_="inside")],
xaxis_opts=opts.AxisOpts(name='城市'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='岗位数量'), # 设置y轴名字属性
)
)
return c
# 地图_中国地图(带省份)Map-VisualMap(连续型)
def map_china() -> Map:
import copy
area_data = {}
with open('./中国省份_城市.txt', mode='r', encoding='utf-8') as f:
for line in f:
line = line.strip().split('_')
area_data[line[0]] = line[1].split(',')
province_data = []
for ct in city_list:
for k, v in area_data.items():
for i in v:
if ct[0] in i:
ct[0] = k
province_data.append(ct)
area_data_deepcopy = copy.deepcopy(area_data)
for k in area_data_deepcopy.keys():
area_data_deepcopy[k] = 0
for i in province_data:
if i[0] in area_data_deepcopy.keys():
area_data_deepcopy[i[0]] = area_data_deepcopy[i[0]] + i[1]
province_data = [[k, v] for k, v in area_data_deepcopy.items()]
best = max(area_data_deepcopy.values())
c = (
Map()
.add("Python", province_data, "china")
.set_global_opts(
title_opts=opts.TitleOpts(title="Python招聘岗位——全国分布情况"),
visualmap_opts=opts.VisualMapOpts(max_=int(best / 2)),
)
)
return c
#饼图
def pie_rich_label() -> Pie:
require_list = []
rl = require_list.append
for i in python_data['招聘要求']:
if '经验' in i:
rl(i.split(' ')[1])
else:
rl('未知')
python_data['招聘要求'] = require_list
require = python_data['招聘要求'].value_counts()
require_list = [list(ct) for ct in require.items()]
c = (
Pie()
.add(
"",
require_list,
radius=["40%", "55%"],
label_opts=opts.LabelOpts(
position="outside",
formatter="{a|{a}}{abg|}\n{hr|}\n {b|{b}: }{c} {per|{d}%} ",
background_color="#eee",
border_color="#aaa",
border_width=1,
border_radius=4,
rich={
"a": {"color": "#999", "lineHeight": 22, "align": "center"},
"abg": {
"backgroundColor": "#e3e3e3",
"width": "100%",
"align": "right",
"height": 22,
"borderRadius": [4, 4, 0, 0],
},
"hr": {
"borderColor": "#aaa",
"width": "100%",
"borderWidth": 0.5,
"height": 0,
},
"b": {"fontSize": 16, "lineHeight": 33},
"per": {
"color": "#eee",
"backgroundColor": "#334455",
"padding": [2, 4],
"borderRadius": 2,
},
},
),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="工作经验要求"),
legend_opts=opts.LegendOpts(padding=20, pos_left=500),
)
)
return c
#折线图
def line_markpoint_custom() -> Line:
import re
sal = python_data['薪资']
xin_zi1 = []
xin_zi2 = []
xin_zi3 = []
xin_zi4 = []
xin_zi5 = []
xin_zi6 = []
for s in sal:
s = str(s)
if '千' in s:
xin_zi1.append(s)
else:
if re.findall('-(.*?)万',s):
s = float(re.findall('-(.*?)万',s)[0])
if 1.0<s<=1.5:
xin_zi2.append(s)
elif 1.5<s<=2.5:
xin_zi3.append(s)
elif 2.5<s<=3.2:
xin_zi4.append(s)
elif 3.2<s<=4.0:
xin_zi5.append(s)
else:
xin_zi6.append(s)
xin_zi = [['<10k',len(xin_zi1)],['10~15k',len(xin_zi2)],['15<25k',len(xin_zi3)],
['25<32k',len(xin_zi4)],['32<40k',len(xin_zi5)],['>40k',len(xin_zi6),]]
x, y =[i[0] for i in xin_zi],[i[1] for i in xin_zi]
c = (
Line()
.add_xaxis(x)
.add_yaxis(
"Python",
y,
markpoint_opts=opts.MarkPointOpts(
data=[opts.MarkPointItem(name="MAX", coord=[x[2], y[2]], value=y[2])]
),
)
.set_global_opts(title_opts=opts.TitleOpts(title="薪资情况"),
xaxis_opts=opts.AxisOpts(name='薪资范围'), # 设置x轴名字属性
yaxis_opts=opts.AxisOpts(name='数量'), # 设置y轴名字属性
)
)
return c
#合并
def page_draggable_layout():
page = Page(layout=Page.DraggablePageLayout)
page.add(
bar_datazoom_slider(),
map_china(),
pie_rich_label(),
line_markpoint_custom(),
)
page.render("page_draggable_layout.html")
if __name__ == "__main__":
page_draggable_layout()
执行完后,会在当前目录下生成一个page_draggable_layout.html。
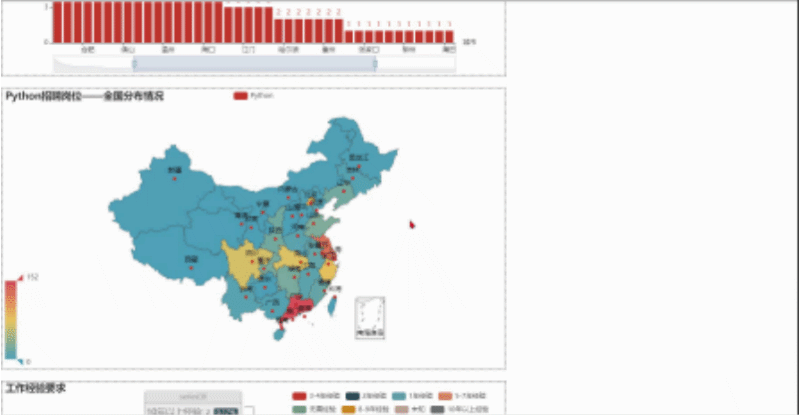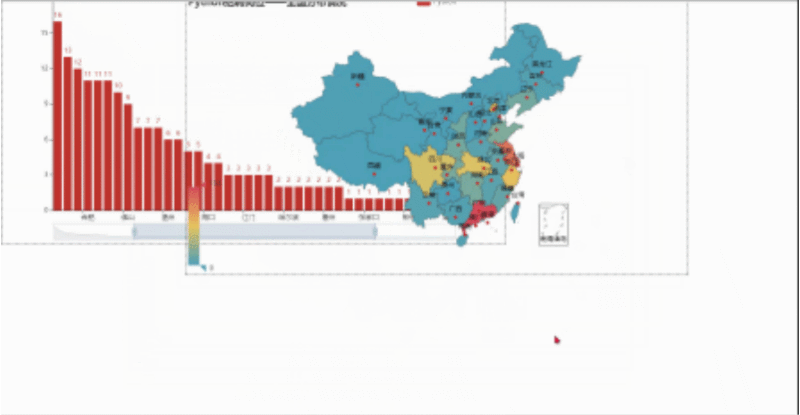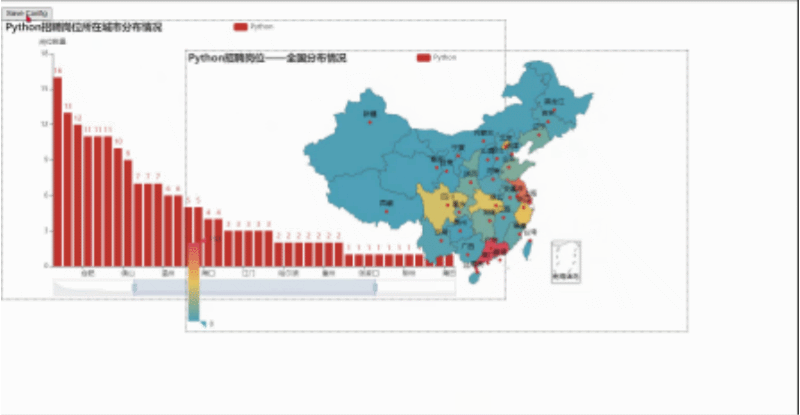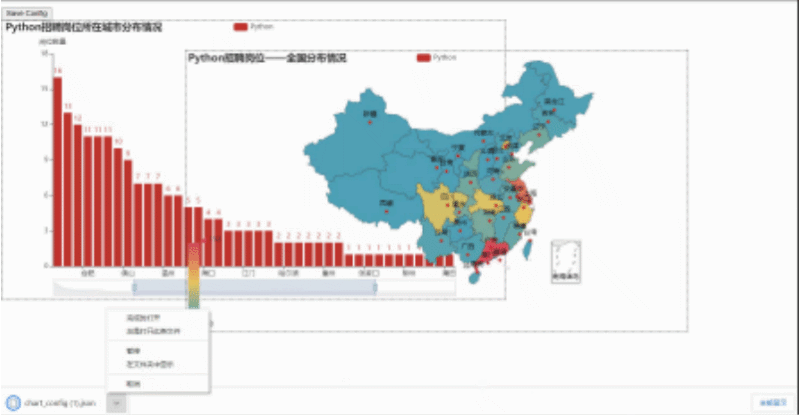
然后我们用浏览器打开,就会看到下面这样,我们可以随便拖动虚线框来进行组合,组合好后点击Save Config就会下载一个chart_config.json,然后在文件中找到它,剪切到py当前目录。
文件放置好后,可以新建一个py文件来执行以下代码,这样就会生成一个resize_render.html,也就完成了。
from pyecharts.charts import Page
Page.save_resize_html('./page_draggable_layout.html',cfg_file='chart_config.json')
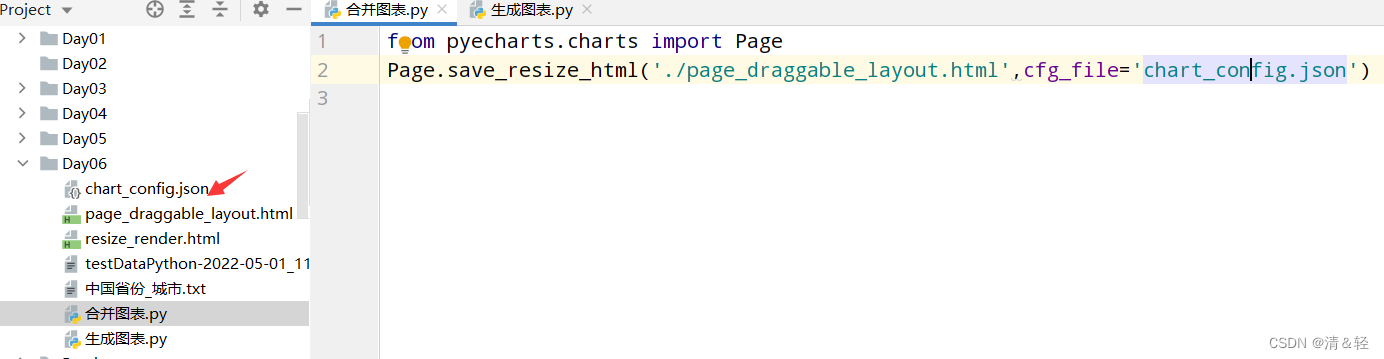
最后,点击打开resize_render.html,我们合并成功的图表就是这样啦!

总结
到此这篇关于Python抓取数据并可视化的文章就介绍到这了,更多相关Python抓取数据可视化内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

利用Python进行数据可视化常见的9种方法!超实用!
前言 如同艺术家们用绘画让人们更贴切的感知世界,数据可视化也能让人们更直观的传递数据所要表达的信息. 我们今天就分享一下如何用 Python 简单便捷的完成数据可视化. 其实利用 Python 可视化数据并不是很麻烦,因为 Python 中有两个专用于可视化的库 matplotlib 和 seaborn 能让我们很容易的完成任务. Matplotlib:基于Python的绘图库,提供完全的 2D 支持和部分 3D 图像支持.在跨平台和互动式环境中生成高质量数据时,matplotlib 会很有帮助
-
Python数据可视化之画图
安装数据可视化模块matplotlib:pip install matplotlib 导入matplotlib模块下的pyplot 1 折线图 from matplotlib import pyplot #横坐标 year=[2010,2012,2014,2016] #纵坐标 perple=[20,40,60,100] #生成折线图:函数polt pyplot.plot(year,perple) #设置横坐标说明 pyplot.xlabel('year') #设置纵坐标说明 pyplot.yla
-
python数据抓取3种方法总结
三种数据抓取的方法 正则表达式(re库) BeautifulSoup(bs4) lxml *利用之前构建的下载网页函数,获取目标网页的html,我们以https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/为例,获取html. from get_html import download url = 'https://guojiadiqu.bmcx.com/AFG__guojiayudiqu/' page_content = download(url) *假设我
-
Python数据分析之绘图和可视化详解
一.前言 matplotlib是一个用于创建出版质量图表的桌面绘图包(主要是2D方面).该项目是由John Hunter于2002年启动的,其目的是为Python构建一个MATLAB式的绘图接口.matplotlib和IPython社区进行合作,简化了从IPython shell(包括现在的Jupyter notebook)进行交互式绘图.matplotlib支持各种操作系统上许多不同的GUI后端,而且还能将图片导出为各种常见的矢量(vector)和光栅(raster)图:PDF.SVG.JPG
-
Python爬取数据并实现可视化代码解析
这次主要是爬了京东上一双鞋的相关评论:将数据保存到excel中并可视化展示相应的信息 主要的python代码如下: 文件1 #将excel中的数据进行读取分析 import openpyxl import matplotlib.pyplot as pit #数据统计用的 wk=openpyxl.load_workbook('销售数据.xlsx') sheet=wk.active #获取活动表 #获取最大行数和最大列数 rows=sheet.max_row cols=sheet.max_colum
-
手把手教你Python抓取数据并可视化
目录 前言 一.数据抓取篇 1.简单的构建反爬措施 2.解析数据 3.完整代码 二.数据可视化篇 1.数据可视化库选用 2.案例实战 (1).柱状图Bar (2).地图Map (3).饼图Pie (4).折线图Line (5).组合图表 总结 前言 大家好,这次写作的目的是为了加深对数据可视化pyecharts的认识,也想和大家分享一下.如果下面文章中有错误的地方还请指正,哈哈哈!!!本次主要用到的第三方库: requests pandas pyecharts 之所以数据可视化选用pyechar
-
Python抓取数据到可视化全流程的实现过程
目录 1.爬取目标网站:业绩预告_数据中心_同花顺财经 2.获取序号.股票代码.等你所需要的信息 3.组成DataFrame 4.处理数据 1.爬取目标网站:业绩预告_数据中心_同花顺财经 (ps:headers不会设置的可以看这篇:Python 用requests.get获取网页内容为空 ’ ’) import pandas as pd import numpy as np import matplotlib.pyplot as plt import re import requests##把
-
Python 抓取数据存储到Redis中的操作
redis是一个key-value存储结构.和Memcached类似,它支持存储的value类型相对更多,包括string(字符串).list(链表).set(集合).zset(sorted set 有序集合)和hash(哈希类型),数据存储如下图分析 为了分别为ID存入多个键值对,此次仅对Hash数据进行操作,例子如下 import os,sys import requests import bs4 import redis #连接Redis r = redis.Redis(host='127
-
Python抓取框架 Scrapy的架构
最近在学Python,同时也在学如何使用python抓取数据,于是就被我发现了这个非常受欢迎的Python抓取框架Scrapy,下面一起学习下Scrapy的架构,便于更好的使用这个工具. 一.概述 下图显示了Scrapy的大体架构,其中包含了它的主要组件及系统的数据处理流程(绿色箭头所示).下面就来一个个解释每个组件的作用及数据的处理过程. 二.组件 1.Scrapy Engine(Scrapy引擎) Scrapy引擎是用来控制整个系统的数据处理流程,并进行事务处理的触发.更多的详细内容可以看下
-
python采用requests库模拟登录和抓取数据的简单示例
如果你还在为python的各种urllib和urlibs,cookielib 头疼,或者还还在为python模拟登录和抓取数据而抓狂,那么来看看我们推荐的requests,python采集数据模拟登录必备利器! 这也是python推荐的HTTP客户端库: 本文就以一个模拟登录的例子来加以说明,至于采集大家就请自行发挥吧. 代码很简单,主要是展现python的requests库的简单至极,代码如下: s = requests.session() data = {'user':'用户名','pass
-
对python抓取需要登录网站数据的方法详解
scrapy.FormRequest login.py class LoginSpider(scrapy.Spider): name = 'login_spider' start_urls = ['http://www.login.com'] def parse(self, response): return [ scrapy.FormRequest.from_response( response, # username和password要根据实际页面的表单的name字段进行修改 formdat
-
Python基于多线程实现抓取数据存入数据库的方法
本文实例讲述了Python基于多线程实现抓取数据存入数据库的方法.分享给大家供大家参考,具体如下: 1. 数据库类 """ 使用须知: 代码中数据表名 aces ,需要更改该数据表名称的注意更改 """ import pymysql class Database(): # 设置本地数据库用户名和密码 host = "localhost" user = "root" password = "&quo
-
浅谈如何使用python抓取网页中的动态数据实现
我们经常会发现网页中的许多数据并不是写死在HTML中的,而是通过js动态载入的.所以也就引出了什么是动态数据的概念,动态数据在这里指的是网页中由Javascript动态生成的页面内容,是在页面加载到浏览器后动态生成的,而之前并没有的. 在编写爬虫进行网页数据抓取的时候,经常会遇到这种需要动态加载数据的HTML网页,如果还是直接从网页上抓取那么将无法获得任何数据. 今天,我们就在这里简单聊一聊如何用python来抓取页面中的JS动态加载的数据. 给出一个网页:豆瓣电影排行榜,其中的所有电影信息都是
-
python实现scrapy爬虫每天定时抓取数据的示例代码
1. 前言. 1.1. 需求背景. 每天抓取的是同一份商品的数据,用来做趋势分析. 要求每天都需要抓一份,也仅限抓取一份数据. 但是整个爬取数据的过程在时间上并不确定,受本地网络,代理速度,抓取数据量有关,一般情况下在20小时左右,极少情况下会超过24小时. 1.2. 实现功能. 通过以下三步,保证爬虫能自动隔天抓取数据: 每天凌晨00:01启动监控脚本,监控爬虫的运行状态,一旦爬虫进入空闲状态,启动爬虫. 一旦爬虫执行完毕,自动退出脚本,结束今天的任务. 一旦脚本距离启动时间超过24小时,自动
-
如何用python抓取B站数据
概述 可以获取的数据包括: video-视频模块 user-用户模块 dynamic-动态模块 这次用"Running Man"十周年特辑的视频,来做个获取弹幕的Demo. 我是对比 没有对比,就没有伤害,就像最近的"哈工大"某学生和"浙大"某学生一样. 这是之前获取弹幕的过程: 1.弹幕数据接口 https://comment.bilibili.com/123072475.xml (一个固定的url地址 + 视频的cid + .xml) 2.利