python数据可视化Seaborn画热力图
目录
- 1.引言
- 2. 栗子
- 3. 数据预处理
- 4. 画热力图
- 5. 添加数值
- 6. 调色板优化
1.引言
热力图的想法很简单,用颜色替换数字。

现在,这种可视化风格已经从最初的颜色编码表格走了很长一段路。热力图被广泛用于地理空间数据。这种图通常用于描述变量的密度或强度,模式可视化、方差甚至异常可视化等。
鉴于热力图有如此多的应用,本文将介绍如何使用Seaborn 来创建热力图。
2. 栗子
首先我们导入Pandas和Numpy库,这两个库可以帮助我们进行数据预处理。
import pandas as pd import matplotlib.pyplot as plt import seaborn as sb import numpy as np
为了举例,我们采用的数据集是 80 种不同谷物的样本,我们来看看它们的成分。
数据集样例如下所示:

上图中,第一行为表头,接着对于每一行来说,第一列为谷物的名称,后面第4列到16列为每种谷物含有的13种主要组成成分的数值。
3. 数据预处理
解下来我们分析每种谷物13种不同成分之间的相关性,我们可以采用Pandas库中的coor()函数来计算相关性,
代码如下:
# read dataset
df = pd.read_csv('data/cereal.csv')
# get correlations
df_corr = df.corr() # 13X13
print(df_corr)
得到结果如下:
calories protein fat ... weight cups rating
calories 1.000000 0.019066 0.498610 ... 0.696091 0.087200 -0.689376
protein 0.019066 1.000000 0.208431 ... 0.216158 -0.244469 0.470618
fat 0.498610 0.208431 1.000000 ... 0.214625 -0.175892 -0.409284
sodium 0.300649 -0.054674 -0.005407 ... 0.308576 0.119665 -0.401295
fiber -0.293413 0.500330 0.016719 ... 0.247226 -0.513061 0.584160
carbo 0.250681 -0.130864 -0.318043 ... 0.135136 0.363932 0.052055
sugars 0.562340 -0.329142 0.270819 ... 0.450648 -0.032358 -0.759675
potass -0.066609 0.549407 0.193279 ... 0.416303 -0.495195 0.380165
vitamins 0.265356 0.007335 -0.031156 ... 0.320324 0.128405 -0.240544
shelf 0.097234 0.133865 0.263691 ... 0.190762 -0.335269 0.025159
weight 0.696091 0.216158 0.214625 ... 1.000000 -0.199583 -0.298124
cups 0.087200 -0.244469 -0.175892 ... -0.199583 1.000000 -0.203160
rating -0.689376 0.470618 -0.409284 ... -0.298124 -0.203160 1.000000[13 rows x 13 columns]
接着我们移除相关性不大的最后几个成分,代码如下:
# irrelevant fields fields = ['rating', 'shelf', 'cups', 'weight'] # drop rows df_corr.drop(fields, inplace=True) # 9X13 # drop cols df_corr.drop(fields, axis=1, inplace=True) # 9X9 print(df_corr)
得到结果如下:

我们知道相关性矩阵是对称矩阵,矩阵中上三角和下三角的值是相同的,这带来了很大的重复。
4. 画热力图
非常幸运的是我们可以使用Mask矩阵来生成Seaborn中的热力图,那么我们首先来生成Mask矩阵。
np.ones_like(df_corr, dtype=np.bool)
结果如下:
接着我们来得到上三角矩阵,在Numpy中使用np.triu函数可以返回上三角矩阵对应的Mask,
如下所示:
mask = np.triu(np.ones_like(df_corr, dtype=np.bool))
结果如下:

接下来我们画热力图,如下所示:
sb.heatmap(df_corr,mask=mask) plt.show()
此时的运行结果如下:

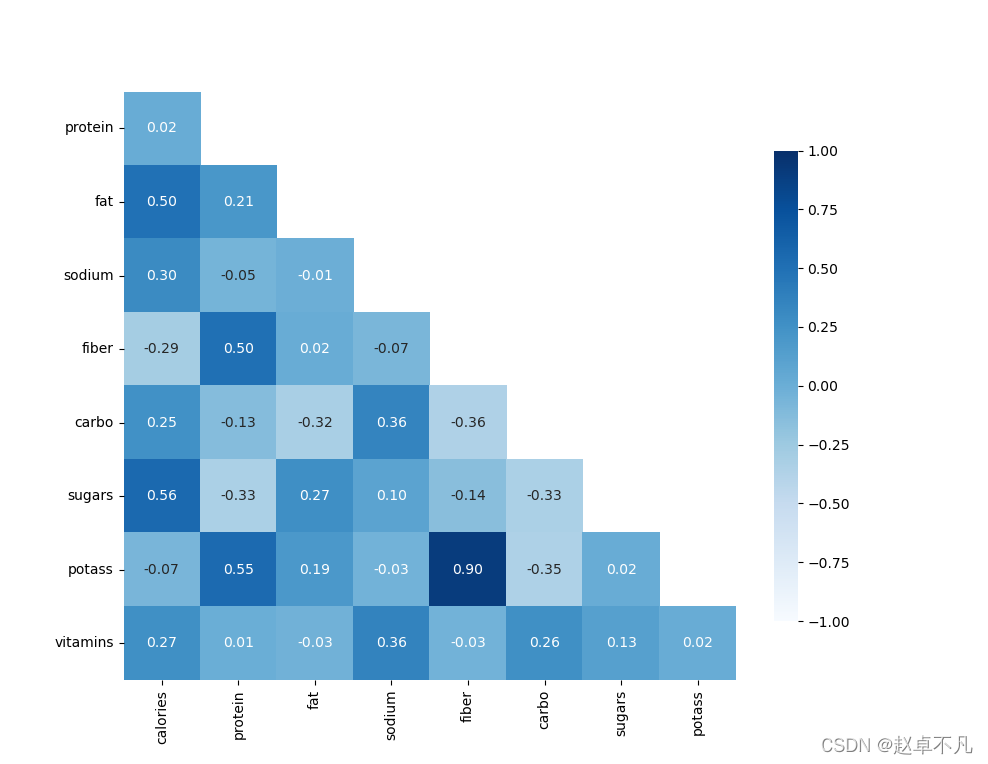
5. 添加数值
观察上图,我们虽然使用Mask生成了热力图,但是图像中还有两个空的单元格(红色圆圈所示)。
我们当然可以在绘制的时候将其进行过滤。即分别将和上述圆圈对应的mask和df_corr过滤掉,
代码如下:
# adjust mask and df mask = mask[1:, :-1] corr = df_corr.iloc[1:, :-1].copy()
同时我们可以设置heatmap相应的参数,让其显示对应的数值,
完整代码如下:
def test2():
# read dataset
df = pd.read_csv('data/cereal.csv')
# get correlations
df_corr = df.corr() # 13X13
# irrelevant fields
fields = ['rating', 'shelf', 'cups', 'weight']
df_corr.drop(fields, inplace=True) # 9X13
# drop cols
df_corr.drop(fields, axis=1, inplace=True) # 9X9
mask = np.triu(np.ones_like(df_corr, dtype=np.bool))
# adjust mask and df
mask = mask[1:, :-1]
corr = df_corr.iloc[1:, :-1].copy()
# plot heatmap
sb.heatmap(corr, mask=mask, annot=True, fmt=".2f", cmap='Blues',
vmin=-1, vmax=1, cbar_kws={"shrink": .8})
# yticks
plt.yticks(rotation=0)
plt.show()
运行结果如下:
6. 调色板优化
接着我们继续优化可视化的效果,考虑到相关系数的范围为-1到1,所以颜色变化有两个方向。基于此,由中间向两侧发散的调色板相比连续的调色板视觉效果会更好。如下所示为发散的调色板示例:

在Seaborn库中存在生成发散调色板的函数 driverging_palette,该函数用于构建colormaps,每侧使用一种颜色,并在中心汇聚成另一种颜色。
这个函数的完整形式如下:
diverging_palette(h_neg, h_pos, s=75, l=50, sep=1,n=6, center=“light”, as_cmap=False)
该函数使用颜色表示形式为HUSL,即hue,Saturation和Lightness。这里我们查阅网站来选择我们接下来设置的调色板的颜色。
最后但是最最重要的一点,不要忘了在我们的图像上设置标题,使用title函数即可。
完整代码如下:
def test3():
# read dataset
df = pd.read_csv('data/cereal.csv')
# get correlations
df_corr = df.corr() # 13X13
# irrelevant fields
fields = ['rating', 'shelf', 'cups', 'weight']
df_corr.drop(fields, inplace=True) # 9X13
# drop cols
df_corr.drop(fields, axis=1, inplace=True) # 9X9
fig, ax = plt.subplots(figsize=(12, 10))
# mask
mask = np.triu(np.ones_like(df_corr, dtype=np.bool))
# adjust mask and df
mask = mask[1:, :-1]
corr = df_corr.iloc[1:, :-1].copy()
# color map
cmap = sb.diverging_palette(0, 230, 90, 60, as_cmap=True)
# plot heatmap
sb.heatmap(corr, mask=mask, annot=True, fmt=".2f",
linewidths=5, cmap=cmap, vmin=-1, vmax=1,
cbar_kws={"shrink": .8}, square=True)
# ticks
yticks = [i.upper() for i in corr.index]
xticks = [i.upper() for i in corr.columns]
plt.yticks(plt.yticks()[0], labels=yticks, rotation=0)
plt.xticks(plt.xticks()[0], labels=xticks)
# title
title = 'CORRELATION MATRIX\nSAMPLED CEREALS COMPOSITION\n'
plt.title(title, loc='left', fontsize=18)
plt.show()
运行结果如下:

是不是看上去高大上了很多。人类果然还是视觉动物。
到此这篇关于数据可视化Seaborn画热力图的文章就介绍到这了,更多相关Seaborn画热力图内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

python数据可视化Seaborn绘制山脊图
目录 1. 引言 2. 举个栗子 3.山脊图 4.扩展 5.结论 1. 引言 山脊图一般由垂直堆叠的折线图组成,这些折线图中的折线区域间彼此重叠,此外它们还共享相同的x轴. 山脊图经常以一种相对不常见且非常适合吸引大家注意力的紧凑图的形式表现.观察上图,我们给其起名叫Ridge plot是非常恰当的,因为上述图表看起来确实很像山的脊背.此外,上述图像还有另一个称呼叫做Joy Plots–这主要是因为Joy Division乐队在如下专辑封面上采用了这种可视化形式. 2. 举个栗子 在介绍完山脊图
-
Python中seaborn库之countplot的数据可视化使用
在Python数据可视化中,seaborn较好的提供了图形的一些可视化功效. seaborn官方文档见链接:http://seaborn.pydata.org/api.html countplot是seaborn库中分类图的一种,作用是使用条形显示每个分箱器中的观察计数.接下来,对seaborn中的countplot方法进行详细的一个讲解,希望可以帮助到刚入门的同行. 导入seaborn库 import seaborn as sns 使用countplot sns.countplot() cou
-
Python 数据可视化之Seaborn详解
目录 安装 散点图 线图 条形图 直方图 总结 安装 要安装 seaborn,请在终端中输入以下命令. pip install seaborn Seaborn 建立在 Matplotlib 之上,因此它也可以与 Matplotlib 一起使用.一起使用 Matplotlib 和 Seaborn 是一个非常简单的过程.我们只需要像之前一样调用 Seaborn Plotting 函数,然后就可以使用 Matplotlib 的自定义函数了. 注意: Seaborn 加载了提示.虹膜等数据集,但在本教程
-
Python编程matplotlib绘图挑钻石seaborn小提琴和箱线图
目录 箱线图 小提琴图 想不到大家都这么喜欢用python给女朋友挑钻石,所以我又写了个续. 如果看过之前一篇用python给女朋友挑钻石的文章,那么可以直接从箱线图开始读. seaborn是matplotlib的补充包,提供了一系列高颜值的figure,并且集成了多种在线数据集,通过sns.load_dataset()进行调用,可供学习,如果网络不稳定,可下载到本地,然后在调用的时候使用把cache设为True. 其中,diamonds数据集中包含了钻石数据,总计十项,分别是[重量/克拉]ca
-
Python编程使用matplotlib挑钻石seaborn画图入门教程
目录 scatter_plot lmplot jointplot 挑钻石第二弹 seaborn是matplotlib的补充包,提供了一系列高颜值的figure,并且集成了多种在线数据集,通过sns.load_dataset()进行调用,可供学习,如果网络不稳定,可下载到本地,然后在调用的时候使用把cache设为True. scatter_plot 官方的示例就很不错,绘制了diamonds数据集中的钻石数据.diamonds中总共包含十项数据,分别是重量/克拉.切割水平.颜色.透明度.深度.ta
-
python可视化分析的实现(matplotlib、seaborn、ggplot2)
一.matplotlib库 1.基本绘图命令 import matplotlib.pyplot as plt plt.figure(figsize=(5,4)) #设置图形大小 plt.rcParams['axes.unicode_minus']=False #正常显示负号 plt.rcParams['font.sans-self']=['Kai Ti'] #设置字体,这里是楷体,SimHei表示黑体 #基本统计图 plt.bar(x,y);plt.pie(y,labels=x);plt.plo
-
python数据可视化Seaborn画热力图
目录 1.引言 2. 栗子 3. 数据预处理 4. 画热力图 5. 添加数值 6. 调色板优化 1.引言 热力图的想法很简单,用颜色替换数字. 现在,这种可视化风格已经从最初的颜色编码表格走了很长一段路.热力图被广泛用于地理空间数据.这种图通常用于描述变量的密度或强度,模式可视化.方差甚至异常可视化等. 鉴于热力图有如此多的应用,本文将介绍如何使用Seaborn 来创建热力图. 2. 栗子 首先我们导入Pandas和Numpy库,这两个库可以帮助我们进行数据预处理. import pandas
-
Python数据可视化之Seaborn的使用详解
目录 1. 安装 seaborn 2.准备数据 3.背景与边框 3.1 设置背景风格 3.2 其他 3.3 边框控制 4. 绘制 散点图 5. 绘制 折线图 5.1 使用 replot()方法 5.2 使用 lineplot()方法 6. 绘制直方图 displot() 7. 绘制条形图 barplot() 8. 绘制线性回归模型 9. 绘制 核密度图 kdeplot() 9.1 一般核密度图 9.2 边际核密度图 10. 绘制 箱线图 boxplot() 11. 绘制 提琴图 violinpl
-
Python数据可视化Pyecharts制作Heatmap热力图
目录 HeatMap:热力图 1.基本设置 2.热力图数据项 Demo 举例 1.基础热力图 本文介绍基于 Python3 的 Pyecharts 制作 Heatmap(热力图 时需要使用的设置参数和常用模板案例,可根据实际情况对案例中的内容进行调整即可. 使用 Pyecharts 进行数据可视化时可提供直观.交互丰富.可高度个性化定制的数据可视化图表.案例中的代码内容基于 Pyecharts 1.x 版本 . HeatMap:热力图 1.基本设置 class HeatMap( # 初始化配置项
-
Python数据相关系数矩阵和热力图轻松实现教程
对其中的参数进行解释 plt.subplots(figsize=(9, 9))设置画面大小,会使得整个画面等比例放大的 sns.heapmap()这个当然是用来生成热力图的啦 df是DataFrame, pandas的这个类还是很常用的啦~ df.corr()就是得到这个dataframe的相关系数矩阵 把这个矩阵直接丢给sns.heapmap中做参数就好啦 sns.heapmap中annot=True,意思是显式热力图上的数值大小. sns.heapmap中square=True,意思是将图变
-
Python数据可视化绘图实例详解
目录 利用可视化探索图表 1.数据可视化与探索图 2.常见的图表实例 数据探索实战分享 1.2013年美国社区调查 2.波士顿房屋数据集 利用可视化探索图表 1.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 2.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matpl
-
Python数据可视化探索实例分享
目录 一.数据可视化与探索图 二.常见的图表实例 1.折线图 2.散布图 3.直方图.长条图 4. 圆饼图.箱形图 三.社区调查 四.波士顿房屋数据集 一.数据可视化与探索图 数据可视化是指用图形或表格的方式来呈现数据.图表能够清楚地呈现数据性质, 以及数据间或属性间的关系,可以轻易地让人看图释义.用户通过探索图(Exploratory Graph)可以了解数据的特性.寻找数据的趋势.降低数据的理解门槛. 二.常见的图表实例 本章主要采用 Pandas 的方式来画图,而不是使用 Matplotl
-
基于Python数据可视化利器Matplotlib,绘图入门篇,Pyplot详解
Pyplot matplotlib.pyplot是一个命令型函数集合,它可以让我们像使用MATLAB一样使用matplotlib.pyplot中的每一个函数都会对画布图像作出相应的改变,如创建画布.在画布中创建一个绘图区.在绘图区上画几条线.给图像添加文字说明等.下面我们就通过实例代码来领略一下他的魅力. import matplotlib.pyplot as plt plt.plot([1,2,3,4]) plt.ylabel('some numbers') plt.show() 上图是我们通
-
Python数据可视化之绘制柱状图和条形图
一.实验目的: 1.掌握Python中柱状图.条形图绘图函数的使用 2.利用上述绘图函数实现数据可视化 二.实验内容: 1.练习python中柱状图.条形图绘图函数的用法,掌握相关参数的概念 2.根据步骤一绘图函数要求,处理实验数据 3.根据步骤二得到的实验数据,绘制柱状图.条形图 4.练习如何通过调整参数使图片呈现不同效果,例如颜色.图例位置.背景网格.坐标轴刻度和标记等 三.实验过程(附结果截图): 1. 练习python中柱状图.条形图绘图函数的用法,掌握相关参数的概念 (1)练习绘制条形
-
Python数据可视化之用Matplotlib绘制常用图形
一.散点图 散点图用两组数据构成多个坐标点,考察坐标点的分布,判断两变量之间是否存在某种关联或总结坐标点的分布模式. 特点:判断变量之间是否存在数量关联趋势,表示离群点的分布规律. 散点图绘制: plt.scatter(x,y) # 以默认的形状颜色绘制散点图 实例: 假设我们获取到了上海2020年5,10月份每天白天的最高气温(分别位于列表a.b),那么此时如何观察气温和随时间变化的某种规律. # 绘制图形所需的数据 y_5 = [11,17,16,11,12,11,12,13,10,14,8