python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解
基本思路:
首先用开发者工具找到需要提取数据的标签列
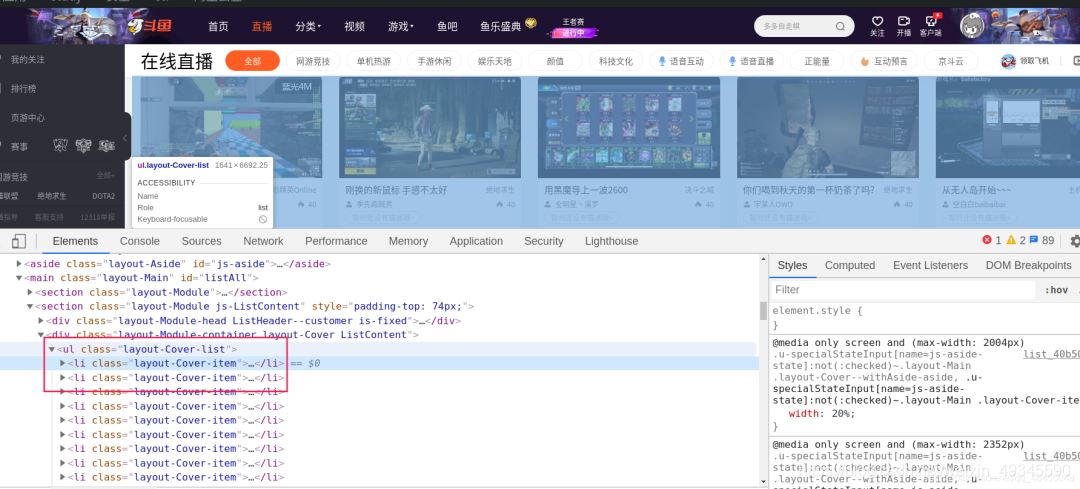
利用xpath定位需要提取数据的列表

然后再逐个提取相应的数据:
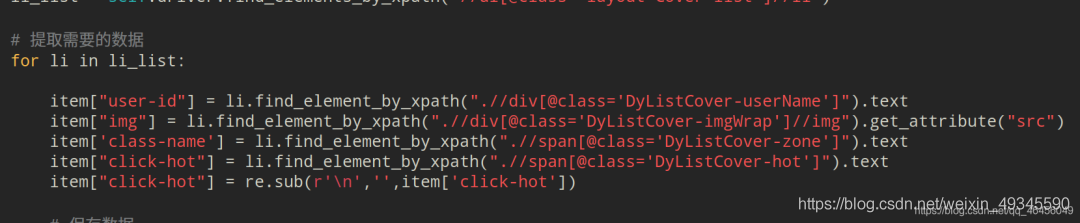
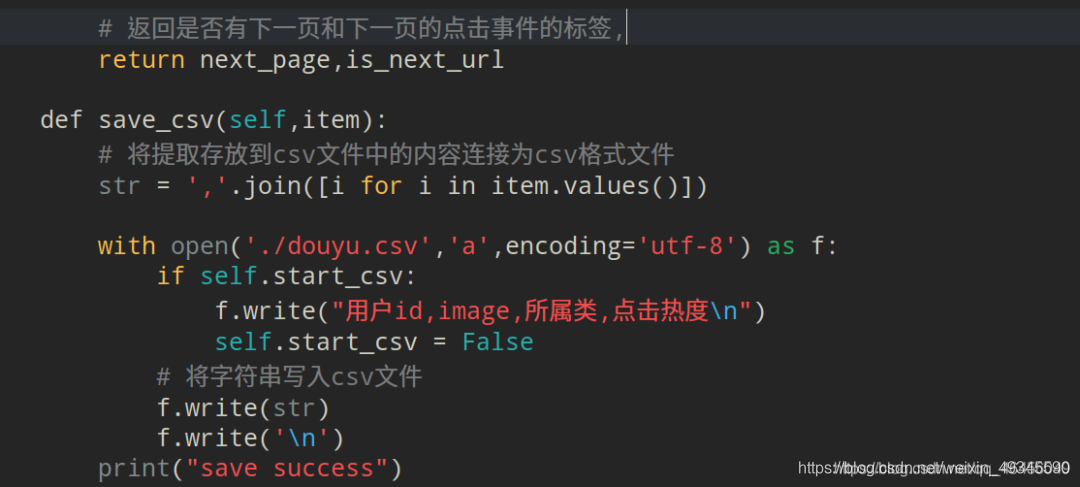
保存数据到csv:
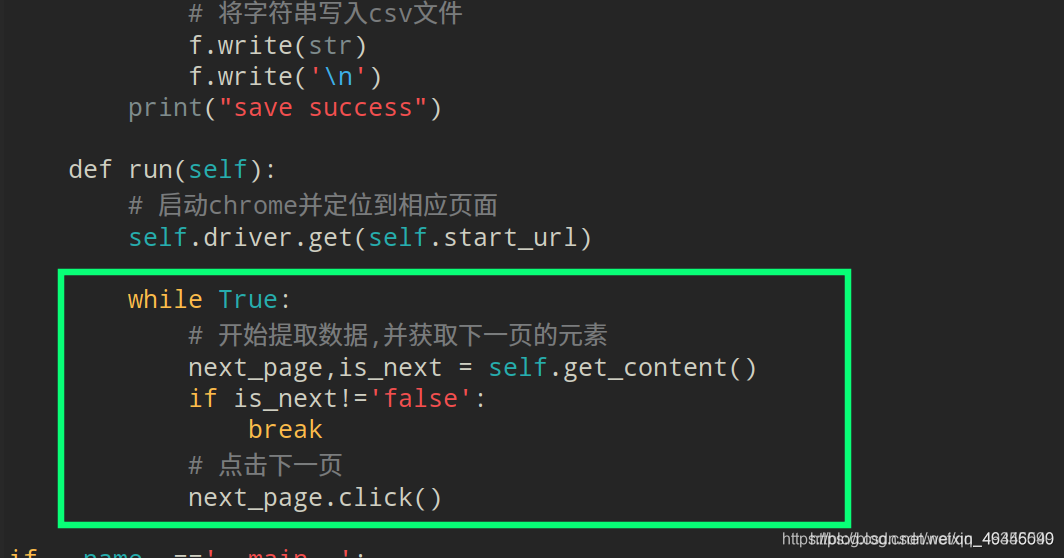
利用开发者工具找到下一页按钮所在标签:

利用xpath提取此标签对象并返回:

调用点击事件,并循环上述过程:
最终效果图:

代码:
from selenium import webdriver
import time
import re
class Douyu(object):
def __init__(self):
# 开始时的url
self.start_url = "https://www.douyu.com/directory/all"
# 实例化一个Chrome对象
self.driver = webdriver.Chrome()
# 用来写csv文件的标题
self.start_csv = True
def __del__(self):
self.driver.quit()
def get_content(self):
# 先让程序两秒,保证页面所有内容都可以加载出来
time.sleep(2)
item = {}
# 获取进入下一页的标签
next_page = self.driver.find_element_by_xpath("//span[text()='下一页']/..")
# 获取用于判断是否是最后一页的属性
is_next_url = next_page.get_attribute("aria-disabled")
# 获取存储信息的所有li标签的列表
li_list = self.driver.find_elements_by_xpath("//ul[@class='layout-Cover-list']//li")
# 提取需要的数据
for li in li_list:
item["user-id"] = li.find_element_by_xpath(".//div[@class='DyListCover-userName']").text
item["img"] = li.find_element_by_xpath(".//div[@class='DyListCover-imgWrap']//img").get_attribute("src")
item['class-name'] = li.find_element_by_xpath(".//span[@class='DyListCover-zone']").text
item["click-hot"] = li.find_element_by_xpath(".//span[@class='DyListCover-hot']").text
item["click-hot"] = re.sub(r'\n','',item['click-hot'])
# 保存数据
self.save_csv(item)
# 返回是否有下一页和下一页的点击事件的标签,
return next_page,is_next_url
def save_csv(self,item):
# 将提取存放到csv文件中的内容连接为csv格式文件
str = ','.join([i for i in item.values()])
with open('./douyu.csv','a',encoding='utf-8') as f:
if self.start_csv:
f.write("用户id,image,所属类,点击热度\n")
self.start_csv = False
# 将字符串写入csv文件
f.write(str)
f.write('\n')
print("save success")
def run(self):
# 启动chrome并定位到相应页面
self.driver.get(self.start_url)
while True:
# 开始提取数据,并获取下一页的元素
next_page,is_next = self.get_content()
if is_next!='false':
break
# 点击下一页
next_page.click()
if __name__=='__main__':
douyu_spider = Douyu()
douyu_spider.run()
到此这篇关于python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解的文章就介绍到这了,更多相关python爬虫实现自动翻页爬取某鱼数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
浅谈python爬虫使用Selenium模拟浏览器行为
前几天有位微信读者问我一个爬虫的问题,就是在爬去百度贴吧首页的热门动态下面的图片的时候,爬取的图片总是爬取不完整,比首页看到的少.原因他也大概分析了下,就是后面的图片是动态加载的.他的问题就是这部分动态加载的图片该怎么爬取到. 分析 他的代码比较简单,主要有以下的步骤:使用BeautifulSoup库,打开百度贴吧的首页地址,再解析得到id为new_list标签底下的img标签,最后将img标签的图片保存下来. headers = { 'User-Agent':'Mozilla/5.0 (Win
-

Python爬虫使用Selenium+PhantomJS抓取Ajax和动态HTML内容
1.引言 在Python网络爬虫内容提取器一文我们详细讲解了核心部件:可插拔的内容提取器类gsExtractor.本文记录了确定gsExtractor的技术路线过程中所做的编程实验.这是第二部分,第一部分实验了用xslt方式一次性提取静态网页内容并转换成xml格式.留下了一个问题:javascript管理的动态内容怎样提取?那么本文就回答这个问题. 2.提取动态内容的技术部件 在上一篇python使用xslt提取网页数据中,要提取的内容是直接从网页的source code里拿到的.但是一些Aja
-
selenium+python设置爬虫代理IP的方法
1. 背景 在使用selenium浏览器渲染技术,爬取网站信息时,一般来说,速度是很慢的.而且一般需要用到这种技术爬取的网站,反爬技术都比较厉害,对IP的访问频率应该有相当的限制.所以,如果想提升selenium抓取数据的速度,可以从两个方面出发: 第一,提高抓取频率,出现验证信息时进行破解,一般是验证码或者用户登录. 第二,使用多线程 + 代理IP, 这种方式,需要电脑有足够的内存和充足稳定的代理IP . 2. 为chrome设置代理IP from selenium import webdri
-
python爬虫利用selenium实现自动翻页爬取某鱼数据的思路详解
基本思路: 首先用开发者工具找到需要提取数据的标签列 利用xpath定位需要提取数据的列表 然后再逐个提取相应的数据: 保存数据到csv: 利用开发者工具找到下一页按钮所在标签: 利用xpath提取此标签对象并返回: 调用点击事件,并循环上述过程: 最终效果图: 代码: from selenium import webdriver import time import re class Douyu(object): def __init__(self): # 开始时的url self.start
-
python爬虫爬取监控教务系统的思路详解
这几天考了大大小小几门课,教务系统又没有成绩通知功能,为了急切想知道自己挂了多少门,于是我写下这个脚本. 设计思路: 设计思路很简单,首先对已有的成绩进行处理,变为list集合,然后定时爬取教务系统查成绩的页面,对爬取的成绩也处理成list集合,如果newList的长度增加了,就找出增加的部分,并通过邮件通知我. 脚本运行效果: 服务器: 发送邮件通知: 代码如下: import datetime import time from email.header import Header impor
-
Python爬虫设置Cookie解决网站拦截并爬取蚂蚁短租的问题
我们在编写Python爬虫时,有时会遇到网站拒绝访问等反爬手段,比如这么我们想爬取蚂蚁短租数据,它则会提示"当前访问疑似黑客攻击,已被网站管理员设置为拦截"提示,如下图所示.此时我们需要采用设置Cookie来进行爬取,下面我们进行详细介绍.非常感谢我的学生承峰提供的思想,后浪推前浪啊! 一. 网站分析与爬虫拦截 当我们打开蚂蚁短租搜索贵阳市,反馈如下图所示结果. 我们可以看到短租房信息呈现一定规律分布,如下图所示,这也是我们要爬取的信息. 通过浏览器审查元素,我们可以看到需要爬取每条租
-
scrapy实践之翻页爬取的实现
安装 Scrapy的安装很简单,官方文档也有详细的说明 http://scrapy-chs.readthedocs.io/zh_CN/0.24/intro/install.html .这里不详细说明了. 在scrapy框架中,spider具有以下几个功能 1. 定义初始爬取的url 2. 定义爬取的行为,是否跟进链接 3. 从网页中提取结构化数据 所谓的跟进链接,其实就是自动爬取该页的所有链接,然后顺着对应的链接延伸开来不断爬取,这样只需要提供一个网站首页,理论上就可以实现网站全部页面的爬取,实
-
Python爬虫实战JS逆向AES逆向加密爬取
目录 爬取目标 工具使用 项目思路解析 简易源码分享 爬取目标 网址:监管平台 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,AES,json 涉及AES对称加密问题 需要 安装node.js环境 使用npm install 安装 crypto-js 项目思路解析 确定数据 在这个网页可以看到数据是动态返回的 但是 都是加密的 如何确定是我们需要的? 突然想到 如果我分页 是不是会直接加载第二个页面 然后查看相似度 找到第
-
用python爬取分析淘宝商品信息详解技术篇
目录 背景介绍 一.模拟登陆 二.爬取商品信息 1. 定义相关参数 2. 分析并定义正则 3. 数据爬取 三.简单数据分析 1.导入库 2.中文显示 3.读取数据 4.分析价格分布 5.分析销售地分布 6.词云分析 写在最后 Tip:本文仅供学习与交流,切勿用于非法用途!!! 背景介绍 有个同学问我:"XXX,有没有办法搜集一下淘宝的商品信息啊,我想要做个统计".于是乎,闲来无事的我,又开始琢磨起这事- 一.模拟登陆 兴致勃勃的我,冲进淘宝就准备一顿乱搜: 在搜索栏里填好关键词:&qu
-
python实现模拟按键,自动翻页看u17漫画
python 适用于windows平台 使用 win32gui,win32api,win32con 包 simu_read.py 复制代码 代码如下: #-*- coding=utf-8 -*- ''' 模拟按键翻页 Usage:python simu_read.py 10 1.5 10表示翻10页,1.5表示在一页中按pgdn的时间间隔为1.5s 一页pgdn 3 次,之后按→翻到下一页 把浏览器打开到u17要看的漫画中,之后启动该程序,再切回u17 便可以自动翻页看漫画了. 仅供娱乐,了解p
-
Python使用爬虫爬取静态网页图片的方法详解
本文实例讲述了Python使用爬虫爬取静态网页图片的方法.分享给大家供大家参考,具体如下: 爬虫理论基础 其实爬虫没有大家想象的那么复杂,有时候也就是几行代码的事儿,千万不要把自己吓倒了.这篇就清晰地讲解一下利用Python爬虫的理论基础. 首先说明爬虫分为三个步骤,也就需要用到三个工具. ① 利用网页下载器将网页的源码等资源下载. ② 利用URL管理器管理下载下来的URL ③ 利用网页解析器解析需要的URL,进而进行匹配. 网页下载器 网页下载器常用的有两个.一个是Python自带的urlli
-
Python selenium爬取微信公众号文章代码详解
参照资料:selenium webdriver添加cookie: https://www.jb51.net/article/193102.html 需求: 想阅读微信公众号历史文章,但是每次找回看得地方不方便. 思路: 1.使用selenium打开微信公众号历史文章,并滚动刷新到最底部,获取到所有历史文章urls. 2.对urls进行遍历访问,并进行下载到本地. 实现 1.打开微信客户端,点击某个微信公众号->进入公众号->打开历史文章链接(使用浏览器打开),并通过开发者工具获取到cookie
-
Python自动化爬取天眼查数据的实现
首先要注册一个账号密码,通过账号密码登录,并且滑块验证,自动输入搜索关键词,进行跳转翻页爬取数据,并保存到Excel文件中. 代码运行时,滑块验证经常不通过,被吃掉,但是发现打包成exe运行没有这个问题,100%成功登录.如果大家知道这个问题麻烦请与我分享,谢谢! 废话不多说直接上代码 # coding=utf-8 from selenium import webdriver import time from PIL import Image, ImageGrab from io import