python读写数据读写csv文件(pandas用法)
python中数据处理是比较方便的,经常用的就是读写文件,提取数据等,本博客主要介绍其中的一些用法。Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能。
一、pandas读取csv文件
数据处理过程中csv文件用的比较多。
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
下面看一下pd.read_csv常用的参数:
pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression='infer', thousands=None, decimal=b'.', lineterminator=None, quotechar='"', quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
常用参数解释:read_csv与read_table常用的参数(更多参数查看官方手册):
filepath_or_buffer #需要读取的文件及路径 sep / delimiter 列分隔符,普通文本文件,应该都是使用结构化的方式来组织,才能使用dataframe header 文件中是否需要读取列名的一行,header=None(使用names自定义列名,否则默认0,1,2,...),header=0(将首行设为列名) names 如果header=None,那么names必须制定!否则就没有列的定义了。 shkiprows= 10 # 跳过前十行 nrows = 10 # 只去前10行 usecols=[0,1,2,...] #需要读取的列,可以是列的位置编号,也可以是列的名称 parse_dates = ['col_name'] # 指定某行读取为日期格式 index_col = None /False /0,重新生成一列成为index值,0表示第一列,用作行索引的列编号或列名。可以是单个名称/数字或由多个名称/数宇组成的列表(层次化索引) error_bad_lines = False # 当某行数据有问题时,不报错,直接跳过,处理脏数据时使用 na_values = 'NULL' # 将NULL识别为空值 encoding='utf-8' #指明读取文件的编码,默认utf-8
读取csv/txt/tsv文件,返回一个DataFrame类型的对象。
举例:
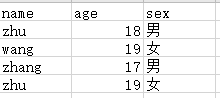
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
name age birth
0 zhu 20 2000.1.5
1 wang 20 2000.6.18
2 zhang 21 1999.11.11
3 zhu 22 1998.10.24
pandas用iloc,loc提取数据
提取行数据:
loc函数:通过行索引 “Index” 中的具体值来取行数据(如取"Index"为"A"的行)
iloc函数:通过行号来取行数据(如取第2行的数据)
import pandas as pd
import numpy as np
#创建一个Dataframe
data = pd.DataFrame(np.arange(16).reshape(4, 4), index=list('abcd'), columns=list('ABCD'))
print(data)
A B C D
a 0 1 2 3
b 4 5 6 7
c 8 9 10 11
d 12 13 14 15
loc提取'a'的行:
print(data.loc['a']) A 0 B 1 C 2 D 3 Name: a, dtype: int32
iloc提取第2行:
print(data.iloc[2]) A 8 B 9 C 10 D 11 Name: c, dtype: int32
提取列数据:
print(data.loc[:, ['A']])#取'A'列所有行,多取几列格式为 data.loc[:,['A','B']] A a 0 b 4 c 8 d 12
print(data.iloc[:, [0]]) A a 0 b 4 c 8 d 12
提取指定行,指定列:
print(data.loc[['a','b'],['A','B']]) #提取index为'a','b',列名为'A','B'中的数据 A B a 0 1 b 4 5
print(data.iloc[[0,1],[0,1]]) #提取第0、1行,第0、1列中的数据 A B a 0 1 b 4 5
提取所有行所有列:
print(data.loc[:,:])#取A,B,C,D列的所有行 print(data.iloc[:,:]) A B C D a 0 1 2 3 b 4 5 6 7 c 8 9 10 11 d 12 13 14 15
根据某个指定数据提取行:
print(data.loc[data['A']==0])#提取data数据(筛选条件: A列中数字为0所在的行数据) A B C D a 0 1 2 3
二、pandas写入csv文件
pandas将多组列表写入csv
import pandas as pd
#任意的多组列表
a = [1,2,3]
b = [4,5,6]
#字典中的key值即为csv中列名
dataframe = pd.DataFrame({'a_name':a,'b_name':b})
#将DataFrame存储为csv,index表示是否显示行名,default=True
dataframe.to_csv("test.csv",index=False,sep=',')
结果:

如果你想写入一行,就是你存储的一个列表是一行数据,你想把这一行数据写入csv文件。
这个时候可以使用csv方法,一行一行的写
import csv
with open("test.csv","w") as csvfile:
writer = csv.writer(csvfile)
#先写入columns_name
writer.writerow(["index","a_name","b_name"])
#写入一行用writerow
#write.writerow([0,1,2])
#写入多行用writerows
writer.writerows([[0,1,3],[1,2,3],[2,3,4]])
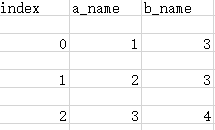
可以看到,每次写一行,就自动空行,解决办法就是在打开文件的时候加上参数newline=''
import csv
with open("F:/zhu/test/test.csv","w", newline='') as csvfile:
writer = csv.writer(csvfile)
#先写入columns_name
writer.writerow(["index","a_name","b_name"])
#写入多行用writerows
writer.writerows([[0,1,3],[1,2,3],[2,3,4]])

写入txt文件类似
(1)创建txt数据文件,创建好文件记得要关闭文件,不然读取不了文件内容
(2)读取txt文件
#读取txt文件
file=open("G:\\info.txt",'r',encoding='utf-8')
userlines=file.readlines()
file.close()
for line in userlines:
username=line.split(',')[0] #读取用户名
password=line.split(',')[1] #读取密码
print(username,password)
三、pandas查看数据表信息
1)查看维度:data.shape
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
print(data.shape)
index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4
(3, 3)
2)查看数据表基本信息:data.info
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
print(data.info)
index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4
<bound method DataFrame.info of index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4>
3)查看每一行的格式:data.dtype
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data.dtypes)
index int64
a_name int64
b_name int64
dtype: object
4)查看前2行数据、后2行数据
df.head() #默认前10行数据,注意:可以在head函数中填写参数,自定义要查看的行数 df.tail() #默认后10 行数据
import pandas as pd
data = pd.read_csv('F:/Zhu/test/test.csv')
print(data)
print(data.head(2))
print(data.tail(2))
index a_name b_name
0 0 1 3
1 1 2 3
2 2 3 4
index a_name b_name
0 0 1 3
1 1 2 3
index a_name b_name
1 1 2 3
2 2 3 4
四、数据清洗
1)NaN数值的处理:用数字0填充空值
data.fillna(value=0,inplace=True)
注意:df.fillna不会立即生效,需要设置inplace=True
2)清除字符字段的字符空格
字符串(str)的头和尾的空格,以及位于头尾的\n \t之类给删掉
data['customername']=data['customername'].map(str.strip)#如清除customername中出现的空格
3)大小写转换
data['customername']=data['customername'].str.lower()
4)删除重复出现的值
data.drop_duplicates(['customername'],inplace=True)
5)数据替换
data['customername'].replace('111','qqq',inplace=True)
参考:
《Python之pandas简介》
《Pandas中loc和iloc函数用法详解(源码+实例) 》
到此这篇关于python读写数据读写csv文件(pandas用法)的文章就介绍到这了,更多相关python读写csv内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python读写csv文件方法详细总结
python提供了大量的库,可以非常方便的进行各种操作,现在把python中实现读写csv文件的方法使用程序的方式呈现出来. 在编写python程序的时候需要csv模块或者pandas模块,其中csv模块使不需要重新下载安装的,pandas模块需要按照对应的 python版本安装. 在python2环境下安装pandas的方式是: sudo pip install pandas 在python3环境下安装pandas的方式是: sudo pip3 install pandas 1.使用csv读写
-

Python csv文件的读写操作实例详解
这篇文章主要介绍了Python csv文件的读写操作实例详解,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 python内置了csv模块,用它可以方便的操作csv文件. 1.写文件 (1)写文件的方法一 import csv # open 打开文件有多种模式,下面是常见的4种 # r:读数据,默认模式 # w:写数据,如果已有数据则会先清空 # a:向文件末尾追加数据 # x : 写数据,如果文件已存在则失败 # 第2至4种模式如果第一个参数指
-
python中csv文件的若干读写方法小结
如下所示: //用普通文本文件方式打开和操作 with open("'file.csv'") as cf: lines=cf.readlines() ...... //用普通文本方式打开,用csv模块操作 import csv with open("file.csv") as cf: lines=csv.reader(cf) for line in lines: print(line) ...... import csv headers=['id','usernam
-
Python实现的简单读写csv文件操作示例
本文实例讲述了Python实现的简单读写csv文件操作.分享给大家供大家参考,具体如下: python中有一个读写csv文件的包,直接import csv即可 新建test.csv 1.写 import csv with open("test.csv","w",encoding='utf8') as csvfile: writer=csv.writer(csvfile) writer.writerow(["index","a_name&
-
python如何读写csv数据
本文实例为大家分享了python读写csv数据的具体代码,供大家参考,具体内容如下 案例: 通过股票网站,我们获取了中国股市数据集,它以csv数据格式存储 Data,Open,High,Low,Close,Volume,Adj Close 2016-06-28,8.63,8.47,8.66,8.70,500000,8.70 2016-06-28,8.63,8.47,8.66,8.70,500000,8.70 2016-06-28,8.63,8.47,8.66,8.70,500000,8.70 .
-
python读写csv文件实例代码
Python读取与写入CSV文件需要导入Python自带的CSV模块,然后通过CSV模块中的函数csv.reader()与csv.writer()来进行CSV文件的读取与写入. 写入CSV文件 import csv # 需要import csv的文件包 out=open("aa.csv",'wb') # 注意这里如果以'w'的形式打开,每次写入的数据中间就会多一个空行,所以要用'wb' csv_write=csv.write(out,dialect='excel') # 下面进行具体的
-
python读写csv文件的方法
1.爬取豆瓣top250书籍 import requests import json import csv from bs4 import BeautifulSoup books = [] def book_name(url): res = requests.get(url) html = res.text soup = BeautifulSoup(html, 'html.parser') items = soup.find(class_="grid-16-8 clearfix").f
-
Python 3.x读写csv文件中数字的方法示例
前言 本文主要给大家介绍了关于Python3.x读写csv文件中数字的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 读写csv文件 读文件时先产生str的列表,把最后的换行符删掉:然后一个个str转换成int ## 读写csv文件 csv_file = 'datas.csv' csv = open(csv_file,'w') for i in range(1,20): csv.write(str(i) + ',') if i % 10 == 0: csv.write
-
python读写数据读写csv文件(pandas用法)
python中数据处理是比较方便的,经常用的就是读写文件,提取数据等,本博客主要介绍其中的一些用法.Pandas是一个强大的分析结构化数据的工具集;它的使用基础是Numpy(提供高性能的矩阵运算);用于数据挖掘和数据分析,同时也提供数据清洗功能. 一.pandas读取csv文件 数据处理过程中csv文件用的比较多. import pandas as pd data = pd.read_csv('F:/Zhu/test/test.csv') 下面看一下pd.read_csv常用的参数: panda
-
python用pandas读写和追加csv文件
目录 csv文件 一.创建csv文件 二.读写csv文件 1.基础python 2.pandas 三.追加csv文件 1.基础python 2.pandas 总结 csv文件 CSV文件是最常用的一个文件存储方式.逗号分隔值(Common-Separated Values,CSV)文件以纯文本形式存储表格数据(注:分隔字符也可以是其他字符).纯文本说明该文件是一个字符序列,不包含必须像二进制数字那样被解读的数据. CSV文件由任意数目记录组成,记录间以某种换行符分隔:每条记录由若干字段组成,字段
-
Python Pandas读写txt和csv文件的方法详解
目录 一.文本文件 1. read_csv() 2. to_csv() 一.文本文件 文本文件,主要包括csv和txt两种等,相应接口为read_csv()和to_csv(),分别用于读写数据 1. read_csv() 格式代码: pandas.read_csv(filepath_or_buffer, sep=', ', delimiter=None, header='infer', names=None, index_col=None, usecols=None, squeeze=False
-
python写入数据到csv或xlsx文件的3种方法
本文实例为大家分享了三种方式使用python写数据到csv或xlsx文件,供大家参考,具体内容如下 第一种:使用csv模块,写入到csv格式文件 # -*- coding: utf-8 -*- import csv with open("my.csv", "a", newline='') as f: writer = csv.writer(f) writer.writerow(["URL", "predict", "
-
python保存字典数据到csv文件的完整代码
导入包 import csv 创建或打开文件,设置文件形式 f = open('xixi.csv', mode='a',encoding='utf-8',newline='') #xixi为文件名称 设置输入数据的格式,设置'A','B','C','D','E', 'F'为列名,根据自己的需要设置自己的列名 csv_writer= csv.DictWriter(f,fieldnames=['A','B','C','D','E', 'F']) 将列名输入 csv_writer.writeheade
-
Python详解复杂CSV文件处理方法
目录 项目简介 项目笔记与心得 1.分批处理与多进程及多线程加速 2.优化算法提高效率 总结 项目简介 鉴于项目保密的需要,不便透露太多项目的信息,因此,简单介绍一下项目存在的难点: 海量数据:项目是对CSV文件中的数据进行处理,而特点是数据量大...真的大!!!拿到的第一个CSV示例文件是110多万行(小CASE),而第二个文件就到了4500万行,等到第三个文件......好吧,一直没见到第三个完整示例文件,因为太大了,据说是第二个示例文件的40多倍,大概二十亿行...... 业务逻辑复杂:项
-
Python简单爬虫导出CSV文件的实例讲解
流程:模拟登录→获取Html页面→正则解析所有符合条件的行→逐一将符合条件的行的所有列存入到CSVData[]临时变量中→写入到CSV文件中 核心代码: ####写入Csv文件中 with open(self.CsvFileName, 'wb') as csvfile: spamwriter = csv.writer(csvfile, dialect='excel') #设置标题 spamwriter.writerow(["游戏账号","用户类型","游戏
-
Python实现序列化及csv文件读取
这篇文章主要介绍了Python实现序列化及csv文件读取,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.python 序列化: 序列化指的是将对象转化为"串行化"数据形式,存储到硬盘或通过网路传输到其他地方,反序列化是指相反的过程,将读取到串行化数据转化成对象.使用pickle模块中的函数,实现序列化和反序列化操作. 序列化使用: pickle.dump(obj,file) obj是被序列化的对象,file指的是存储的文件. pi
-
python基础教程之csv文件的写入与读取
目录 csv的简单介绍 csv的写入 第一种写入方法(通过创建writer对象) 第二种写入方法(使用DictWriter可以使用字典的方式将数据写入) csv的读取 通过reader()读取 通过dictreader()读取 总结 csv的简单介绍 CSV (Comma Separated Values),即逗号分隔值(也称字符分隔值,因为分隔符可以不是逗号),是一种常用的文本格式,用以存储表格数据,包括数字或者字符.很多程序在处理数据时都会碰到csv这种格式的文件.python自带了csv模
-
php使用指定编码导出mysql数据到csv文件的方法
本文实例讲述了php使用指定编码导出mysql数据到csv文件的方法.分享给大家供大家参考.具体实现方法如下: <?php /* * PHP code to export MySQL data to CSV * * Sends the result of a MySQL query as a CSV file for download * Easy to convert to UTF-8. */ /* * establish database connection */ $conn = mysq