python pandas移动窗口函数rolling的用法
超级好用的移动窗口函数
最近经常使用移动窗口函数,觉得很方便,功能强大,代码简单,故将pandas中的移动窗口函数都做介绍。它都是以rolling打头的函数,后接具体的函数,来显示该移动窗口函数的功能。
rolling_count 计算各个窗口中非NA观测值的数量
函数
pandas.rolling_count(arg, window, freq=None, center=False, how=None)
arg : DataFrame 或 numpy的ndarray 数组格式
window : 指移动窗口的大小,为整数
freq :
center : 布尔型,默认为False, 指取中间的
how : 字符串,默认为“mean”,为down- 或re-sampling
import pandas as pd
import numpy as np
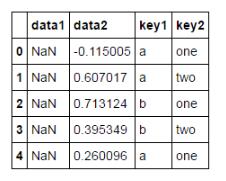
df = pd.DataFrame({'key1':['a','a','b','b','a'],
'key2':['one','two','one','two','one'],
'data1':np.nan,
'data2':np.random.randn(5)})
df
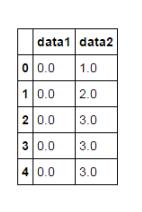
pd.rolling_count(df[['data1','data2']],window = 3)
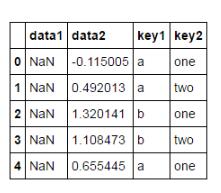
rolling_sum 移动窗口的和
pandas.rolling_sum(arg, window, min_periods=None, freq=None, center=False, how=None, **kwargs)
arg : 为Series或DataFrame
window : 窗口的大小
min_periods : 最小的观察数值个数
freq :
center : 布尔型,默认为False, 指取中间的
how : 取值的方式,默认为None
pd.rolling_sum(df,window = 2,min_periods = 1)
rolling_mean 移动窗口的均值
pandas.rolling_mean(arg, window, min_periods=None, freq=None, center=False, how=None, **kwargs)
rolling_median 移动窗口的中位数
pandas.rolling_median(arg, window, min_periods=None, freq=None, center=False, how='median', **kwargs)
rolling_var 移动窗口的方差
pandas.rolling_var(arg, window, min_periods=None, freq=None, center=False, how=None, **kwargs)
rolling_std 移动窗口的标准差
pandas.rolling_std(arg, window, min_periods=None, freq=None, center=False, how=None, **kwargs)
rolling_min 移动窗口的最小值
pandas.rolling_min(arg, window, min_periods=None, freq=None, center=False, how='min', **kwargs)
rolling_max 移动窗口的最大值
pandas.rolling_min(arg, window, min_periods=None, freq=None, center=False, how='min', **kwargs)
rolling_corr 移动窗口的相关系数
pandas.rolling_corr(arg1, arg2=None, window=None, min_periods=None, freq=None, center=False, pairwise=None, how=None)
rolling_corr_pairwise 配对数据的相关系数
等价于: rolling_corr(…, pairwise=True)
pandas.rolling_corr_pairwise(df1, df2=None, window=None, min_periods=None, freq=None, center=False)
rolling_cov 移动窗口的协方差
pandas.rolling_cov(arg1, arg2=None, window=None, min_periods=None, freq=None, center=False, pairwise=None, how=None, ddof=1)
rolling_skew 移动窗口的偏度(三阶矩)
pandas.rolling_skew(arg, window, min_periods=None, freq=None, center=False, how=None, **kwargs)
rolling_kurt 移动窗口的峰度(四阶矩)
pandas.rolling_kurt(arg, window, min_periods=None, freq=None, center=False, how=None, **kwargs)
rolling_apply 对移动窗口应用普通数组函数
pandas.rolling_apply(arg, window, func, min_periods=None, freq=None, center=False, args=(), kwargs={})
rolling_quantile 移动窗口分位数函数
pandas.rolling_quantile(arg, window, quantile, min_periods=None, freq=None, center=False)
rolling_window 移动窗口
pandas.rolling_window(arg, window=None, win_type=None, min_periods=None, freq=None, center=False, mean=True, axis=0, how=None, **kwargs)
ewma 指数加权移动
ewma(arg[, com, span, halflife, ...])
ewmstd 指数加权移动标准差
ewmstd(arg[, com, span, halflife, ...])
ewmvar 指数加权移动方差
ewmvar(arg[, com, span, halflife, ...])
ewmcorr 指数加权移动相关系数
ewmcorr(arg1[, arg2, com, span, halflife, ...])
ewmcov 指数加权移动协方差
ewmcov(arg1[, arg2, com, span, halflife, ...])
以上这篇python pandas移动窗口函数rolling的用法就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
对pandas中时间窗函数rolling的使用详解
在建模过程中,我们常常需要需要对有时间关系的数据进行整理.比如我们想要得到某一时刻过去30分钟的销量(产量,速度,消耗量等),传统方法复杂消耗资源较多,pandas提供的rolling使用简单,速度较快. 函数原型和参数说明 DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None) window:表示时间窗的大小,注意有两种形式
-
python pandas移动窗口函数rolling的用法
超级好用的移动窗口函数 最近经常使用移动窗口函数,觉得很方便,功能强大,代码简单,故将pandas中的移动窗口函数都做介绍.它都是以rolling打头的函数,后接具体的函数,来显示该移动窗口函数的功能. rolling_count 计算各个窗口中非NA观测值的数量 函数 pandas.rolling_count(arg, window, freq=None, center=False, how=None) arg : DataFrame 或 numpy的ndarray 数组格式 window :
-

Python Pandas数据合并pd.merge用法详解
目录 前言 语法 参数 1.连接键 2.索引连接 3.多连接键 4.连接方法 5.连接指示 总结 前言 实现类似SQL的join操作,通过pd.merge()方法可以自由灵活地操作各种逻辑的数据连接.合并等操作 可以将两个DataFrame或Series合并,最终返回一个合并后的DataFrame 语法 pd.merge(left, right, how = 'inner', on = None, left_on = None, right_on = None, left_index = Fal
-
python pandas中的agg函数用法
目录 pandas中的agg函数 pandas详解 聚合运算agg() 1. 创建DataFrame对象 2. 单列聚合 3. 多列聚合 4. 多种聚合运算 5. 多种聚合运算并更改列名 6. 不同的列运用不同的聚合函数 7. 使用自定义的聚合函数 8. 方便的descibe pandas中的agg函数 python中的agg函数通常用于调用groupby()函数之后,对数据做一些聚合操作,包括sum,min,max以及其他一些聚合函数 如下所示: >>> df = pd.read_ex
-
Python pandas用法最全整理
1.首先导入pandas库,一般都会用到numpy库,所以我们先导入备用: import numpy as npimport pandas as pd 2.导入CSV或者xlsx文件: df = pd.DataFrame(pd.read_csv('name.csv',header=1))df = pd.DataFrame(pd.read_excel('name.xlsx')) 3.用pandas创建数据表: df = pd.DataFrame({"id":[1001,1002,1003
-
Python Pandas pandas.read_sql_query函数实例用法分析
Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.Pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一.本文主要介绍一下Pandas中read_sql_query方法的使用. pandas.read_sql_query(sql,con,index_col = None,coerce_float =
-
Python Pandas pandas.read_sql函数实例用法
Pandas是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具.Pandas提供了大量能使我们快速便捷地处理数据的函数和方法.你很快就会发现,它是使Python成为强大而高效的数据分析环境的重要因素之一.本文主要介绍一下Pandas中read_sql方法的使用. pandas.read_sql(sql,con,index_col = None,coerce_float = True,params
-
Python Pandas数据分析之iloc和loc的用法详解
Pandas 是一套用于 Python 的快速.高效的数据分析工具.它可以用于数据挖掘和数据分析,同时也提供数据清洗功能.本篇目录如下: 一.iloc 1.定义 iloc索引器用于按位置进行基于整数位置的索引或者选择. 2.语法 df.iloc [row selection, column selection] 3.代码示例 (1)导入数据 (2)选择单行或单列 (3)选择多行或多列 (4)注意 iloc选择一行时返回Series,选择多行返回DataFrame,通过传递列表可转为DataFra
-
Python pandas.replace的用法详解
目录 1. pandas.replace()介绍 2. 单值替换 2.1 全局替换 2.2 选定条件替换 3. 多值替换 3.1 多个值替换同一个值 3.2 多个值替换不同值 4. 模糊查询替换 5. 缺失值替换 5.1 method的用法 (向前/后填充) 5.2 limit的用法 (限制最大填充间隔) 补充:使用实例代码 总结 1. pandas.replace()介绍 pandas.Series.replace 官方文档 Series.replace(to_replace=None, va
-
Python Pandas中loc和iloc函数的基本用法示例
目录 1 loc和iloc的含义 2 用法 2.1 loc函数的用法 2.2 iloc函数的用法 补充:Pandas中loc和iloc函数实例 总结 1 loc和iloc的含义 loc表示location的意思:iloc中的loc意思相同,前面的i表示integer,所以它只接受整数作为参数. 2 用法 import pandas as pd import numpy as np # np.random.randn(5, 2)表示返回5x2的矩阵,index表示行的编号,columns表示列的编
-
Python pandas中apply函数简介以及用法详解
目录 1.基本信息 2.语法结构 3.使用案例 3.1 DataFrame使用apply 3.2 Series使用apply 3.3 其他案例 4.总结 参考链接: 1.基本信息 Pandas 的 apply() 方法是用来调用一个函数(Python method),让此函数对数据对象进行批量处理.Pandas 的很多对象都可以使用 apply() 来调用函数,如 Dataframe.Series.分组对象.各种时间序列等. 2.语法结构 apply() 使用时,通常放入一个 lambd