python扫描线填充算法详解
本文实例为大家分享了python扫描线填充算法,供大家参考,具体内容如下
介绍
1.用水平扫描线从上到下扫描由点线段构成的多段构成的多边形。
2.每根扫描线与多边形各边产生一系列交点。将这些交点按照x坐标进行分类,将分类后的交点成对取出,作为两个端点,以所填的色彩画水平直线。
3.多边形被扫描完毕后,填色也就完成。
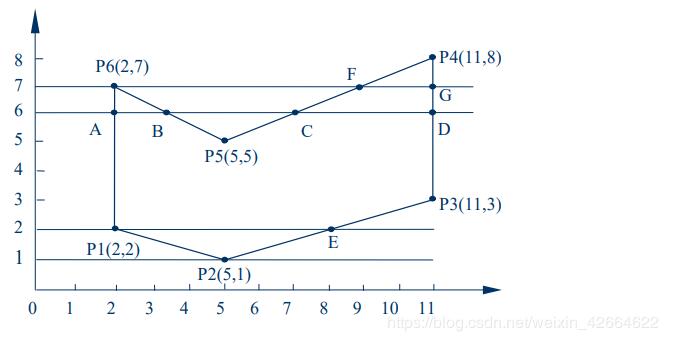
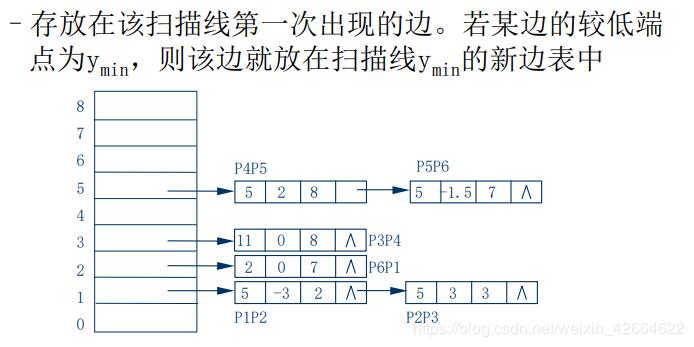
数据结构
活性边表:

新边表:
代码(使用数组)
import numpy as np
from PIL import Image
from PIL import ImageDraw
from PIL import ImageFont
array = np.ndarray((660, 660, 3), np.uint8)
array[:, :, 0] = 255
array[:, :, 1] = 255
array[:, :, 2] = 255
for i in range(0,660,1):
array[i,330]=(0,0,0)
for j in range(0,660,1):
array[330,j]=(0,0,0)
def creat_Net(point, row, y_min,y_max ):
Net = [([ ] * y_max ) for i in range(y_max )]
point_count = point.shape[0]
for j in range(0, point_count):
x = np.zeros(10)
first = int(min(point[(j+1)%point_count][1] , point[j][1]))
x[1] = 1/((point[(j+1)%point_count][1]-point[j][1])/(point[(j+1)%point_count][0]-point[j][0])) # x 的增量
x[2] = max(point[(j+1)%point_count][1] , point[j][1])
if(point[(j+1)%point_count][1] < point[j][1]):
x[0] = point[(j+1)%point_count][0]
else:
x[0] = point[j][0]
Net[first].append(x)
return Net
def draw_line(i,x ,y ):
for j in range(int(x),int(y)+1):
array[330-i,j+330]=(20,20,20)
def polygon_fill(point):
y_min = np.min(point[:,1])
y_max = np.max(point[:,1])
Net = creat_Net(point, y_max - y_min + 1, y_min, y_max)
x_sort = [] * 3
for i in range(y_min, y_max):
x = Net[i]
if(len(x) != 0):
for k in x :
x_sort.append(k)
x_image = [] * 3
for cell in x_sort:
x_image.append(cell[0])
x_image.sort()
if(len(x_image) >= 3 and x_image[0]==x_image[1] and x_image[2]>x_image[1]):
x_image[1] = x_image[2]
draw_line(i, x_image[0], x_image[1])
linshi = [] * 3
for cell in x_sort:
if cell[2] > i:
cell[0] += cell[1]
linshi.append(cell)
x_sort = linshi[:]
x_image = [] * 3
for cell in x_sort:
x_image.append(cell[0])
x_image.sort()
draw_line(i, x_image[0],x_image[1])
def main():
point = [[55,40], [100,80], [100,160],[55,180], [10,160], [10,80]]
point = np.array(point)
polygon_fill( point )
image = Image.fromarray(array)
image.save('saomao.jpg')
image.show()
if __name__ == "__main__":
main()
实例:
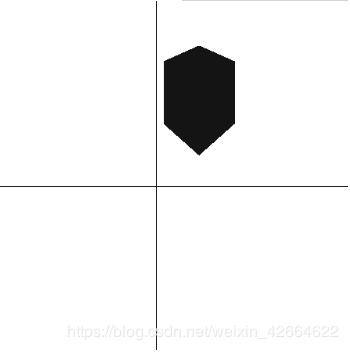
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python实现螺旋矩阵的填充算法示例
本文实例讲述了Python实现螺旋矩阵的填充算法.分享给大家供大家参考,具体如下: afanty的分析: 关于矩阵(二维数组)填充问题自己动手推推,分析下两个下表的移动规律就很容易咯. 对于螺旋矩阵,不管它是什么鬼,反正就是依次向右.向下.向右.向上移动. 向右移动:横坐标不变,纵坐标加1 向下移动:纵坐标不变,横坐标加1 向右移动:横坐标不变,纵坐标减1 向上移动:纵坐标不变,横坐标减1 代码实现: #coding=utf-8 import numpy ''''' Author: afanty
-
python扫描线填充算法详解
本文实例为大家分享了python扫描线填充算法,供大家参考,具体内容如下 介绍 1.用水平扫描线从上到下扫描由点线段构成的多段构成的多边形. 2.每根扫描线与多边形各边产生一系列交点.将这些交点按照x坐标进行分类,将分类后的交点成对取出,作为两个端点,以所填的色彩画水平直线. 3.多边形被扫描完毕后,填色也就完成. 数据结构 活性边表: 新边表: 代码(使用数组) import numpy as np from PIL import Image from PIL import ImageDraw
-
OpenGL扫描线填充算法详解
本文实例为大家分享了OpenGL扫描线填充算法,供大家参考,具体内容如下 说明 把最近一系列的图形学经典算法实现了一下.课业繁忙,关于该系列的推导随后再写.但是在注释里已经有较为充分的分析. 分情况讨论 注意对于横线需要特别讨论,但是对于垂直线却不必特别讨论.想一想为什么? 代码 #include <iostream> #include <GLUT/GLUT.h> #include <map> #include <vector> #include <l
-
Python实现KPM算法详解
目录 知识点说明: 一.要获取KPM算法的next[]数组 二.KMP函数 知识点说明: 先说前缀,和后缀吧 比如有一个串:abab 则在下标为3处的(前缀和后缀都要比下标出的长度小1,此处下标为3出的长度是4) 前缀为:a,ab,aba 后缀为:b,ba,bab 一.要获取KPM算法的next[]数组 简单说一下原理吧,首先k,用来存放前缀的下标,首先初始化j=0(j用来表示模式串的下标,一直去模式串的每一位与前面的进行比较,如果相等,则记录下当前位置与前面的哪个位置相同,我们这里主要是要记录
-
python快排算法详解
快排是python经典算法之一. 1.下面讲解的是什么是快排和快排的图示. 2.快排是一种解决排序问题的运算方法. 3.快排的原理:在数组中任意选择一个数字作为基准,用数组的数据和基准数据进行比较,比基准数字打的数字的基准数字的右边,比基准数字小的数字在基准数字的左边, 第一次排序之后分为比基准数据大或比基准数据小两个部分,用刚开始的方法继续排序,直到每个排序分组中只有一个数据或没有数据为止. 4.下面以[ 7 91 23 1 6 3 79 2 ]数组为例子,进行快排运算. 5.选基准:选择数组
-
Python 蚁群算法详解
目录 蚁群算法简介 TSP问题描述 蚁群算法原理 代码实现 总结 蚁群算法简介 蚁群算法(Ant Clony Optimization, ACO)是一种群智能算法,它是由一群无智能或有轻微智能的个体(Agent)通过相互协作而表现出智能行为,从而为求解复杂问题提供了一个新的可能性.蚁群算法最早是由意大利学者Colorni A., Dorigo M. 等于1991年提出.经过20多年的发展,蚁群算法在理论以及应用研究上已经得到巨大的进步. 蚁群算法是一种仿生学算法,是由自然界中蚂蚁觅食的行为而启发
-
python算法演练_One Rule 算法(详解)
这样某一个特征只有0和1两种取值,数据集有三个类别.当取0的时候,假如类别A有20个这样的个体,类别B有60个这样的个体,类别C有20个这样的个体.所以,这个特征为0时,最有可能的是类别B,但是,还是有40个个体不在B类别中,所以,将这个特征为0分到类别B中的错误率是40%.然后,将所有的特征统计完,计算所有的特征错误率,再选择错误率最低的特征作为唯一的分类准则--这就是OneR. 现在用代码来实现算法. # OneR算法实现 import numpy as np from sklearn.da
-
python实现决策树C4.5算法详解(在ID3基础上改进)
一.概论 C4.5主要是在ID3的基础上改进,ID3选择(属性)树节点是选择信息增益值最大的属性作为节点.而C4.5引入了新概念"信息增益率",C4.5是选择信息增益率最大的属性作为树节点. 二.信息增益 以上公式是求信息增益率(ID3的知识点) 三.信息增益率 信息增益率是在求出信息增益值在除以. 例如下面公式为求属性为"outlook"的值: 四.C4.5的完整代码 from numpy import * from scipy import * from mat
-
python中实现k-means聚类算法详解
算法优缺点: 优点:容易实现 缺点:可能收敛到局部最小值,在大规模数据集上收敛较慢 使用数据类型:数值型数据 算法思想 k-means算法实际上就是通过计算不同样本间的距离来判断他们的相近关系的,相近的就会放到同一个类别中去. 1.首先我们需要选择一个k值,也就是我们希望把数据分成多少类,这里k值的选择对结果的影响很大,Ng的课说的选择方法有两种一种是elbow method,简单的说就是根据聚类的结果和k的函数关系判断k为多少的时候效果最好.另一种则是根据具体的需求确定,比如说进行衬衫尺寸的聚
-
Python编程实现蚁群算法详解
简介 蚁群算法(ant colony optimization, ACO),又称蚂蚁算法,是一种用来在图中寻找优化路径的机率型算法.它由Marco Dorigo于1992年在他的博士论文中提出,其灵感来源于蚂蚁在寻找食物过程中发现路径的行为.蚁群算法是一种模拟进化算法,初步的研究表明该算法具有许多优良的性质.针对PID控制器参数优化设计问题,将蚁群算法设计的结果与遗传算法设计的结果进行了比较,数值仿真结果表明,蚁群算法具有一种新的模拟进化优化方法的有效性和应用价值. 定义 各个蚂蚁在没有事先告诉
-
python里反向传播算法详解
反向传播的目的是计算成本函数C对网络中任意w或b的偏导数.一旦我们有了这些偏导数,我们将通过一些常数 α的乘积和该数量相对于成本函数的偏导数来更新网络中的权重和偏差.这是流行的梯度下降算法.而偏导数给出了最大上升的方向.因此,关于反向传播算法,我们继续查看下文. 我们向相反的方向迈出了一小步--最大下降的方向,也就是将我们带到成本函数的局部最小值的方向. 图示演示: 反向传播算法中Sigmoid函数代码演示: # 实现 sigmoid 函数 return 1 / (1 + np.exp(-x))