C语言数据结构之vector底层实现机制解析
目录
- 一、vector底层实现机制刨析
- 二、vector的核心框架接口的模拟实现
- 1.vector的迭代器实现
- 2.reserve()扩容
- 3.尾插尾删(push_back(),pop_back())
- 4.对insert()插入时迭代器失效刨析
- 5.对erase()数据删除时迭代器失效刨析
一、vector底层实现机制刨析
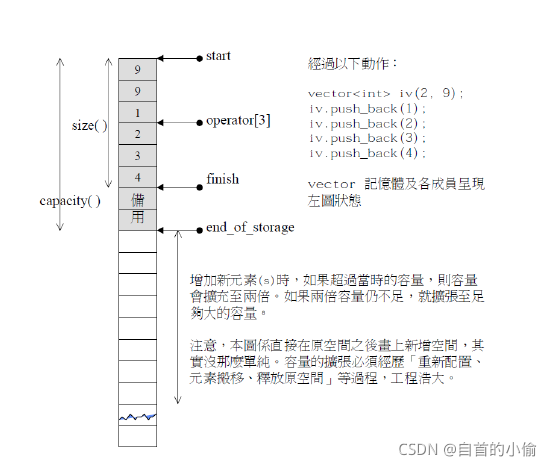
通过分析 vector 容器的源代码不难发现,它就是使用 3 个迭代器(可以理解成指针)来表示的:
其中statrt指向vector 容器对象的起始字节位置;
finish指向当前最后一个元素的末尾字节
end_of指向整个 vector 容器所占用内存空间的末尾字节。
如图 演示了以上这 3 个迭代器分别指向的位置
如图 演示了以上这 2个迭代器分别指向的位置
在此基础上,将 3 个迭代器两两结合,还可以表达不同的含义,例如:
start 和 finish 可以用来表示 vector 容器中目前已被使用的内存空间;
finish 和 end_of可以用来表示 vector 容器目前空闲的内存空间;
start和 end_of可以用表示 vector 容器的容量。
二、vector的核心框架接口的模拟实现
1.vector的迭代器实现
typedef T* Iteratot;
typedef T* const_Iteratot;
Iteratot cend()const {
return final_end;
}
Iteratot cbegin()const {
return start;
}
Iteratot end() {
return final_end;
}
Iteratot begin() {
return start;
}
vector的迭代器是一个原生指针,他的迭代器和String相同都是操作指针来遍历数据:
- begin()返回的是vector 容器对象的起始字节位置;
- end()返回的是当前最后一个元素的末尾字节;
2.reserve()扩容
void reserve(size_t n) {
if (n > capacity()) {
T* temp = new T [n];
//把statrt中的数据拷贝到temp中
size_t size1 = size();
memcpy(temp, start, sizeof(T*) * size());
start = temp;
final_end = start + size1;
finally = start + n;
}
}
当 vector 的大小和容量相等(size==capacity)也就是满载时,如果再向其添加元素,那么 vector 就需要扩容。vector 容器扩容的过程需要经历以下 3 步:
- 完全弃用现有的内存空间,重新申请更大的内存空间;
- 将旧内存空间中的数据,按原有顺序移动到新的内存空间中;
- 最后将旧的内存空间释放。
这也就解释了,为什么 vector 容器在进行扩容后,与其相关的指针、引用以及迭代器可能会失效的原因。
由此可见,vector 扩容是非常耗时的。为了降低再次分配内存空间时的成本,每次扩容时 vector 都会申请比用户需求量更多的内存空间(这也就是 vector 容量的由来,即 capacity>=size),以便后期使用。
vector 容器扩容时,不同的编译器申请更多内存空间的量是不同的。以 VS 为例,它会扩容现有容器容量的 50%。
使用memcpy拷贝问题
reserve扩容就是开辟新空间用memcpy将老空间的数据拷贝到新开空间中。
假设模拟实现的vector中的reserve接口中,使用memcpy进行的拷贝,以下代码会发生什么问题?
int main()
{
bite::vector<bite::string> v;
v.push_back("1111");
v.push_back("2222");
v.push_back("3333");
return 0;
}
问题分析:
- memcpy是内存的二进制格式拷贝,将一段内存空间中内容原封不动的拷贝到另外一段内存空间中
- 如果拷贝的是自定义类型的元素,memcpy即高效又不会出错,但如果拷贝的是自定义类型元素,并且自定义类型元素中涉及到资源管理时,就会出错,因为memcpy的拷贝实际是浅拷贝。
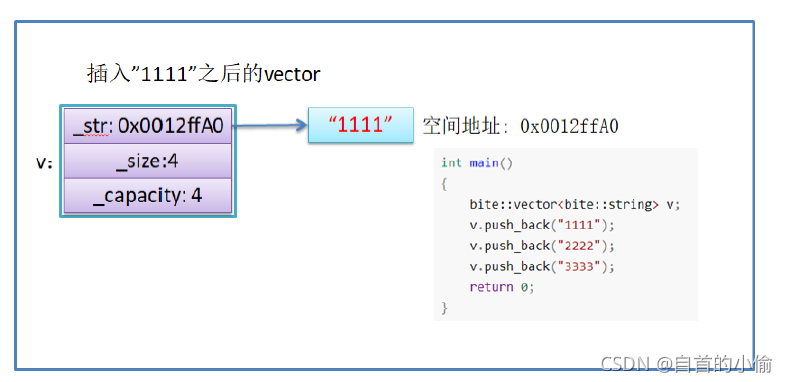

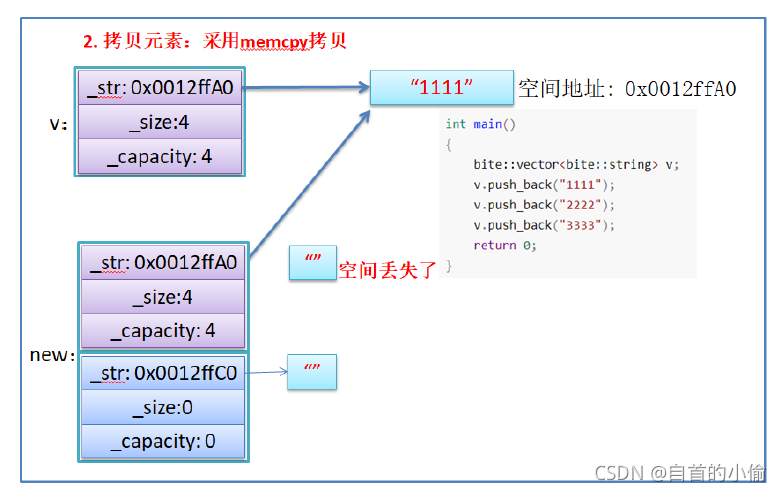

结论:如果对象中涉及到资源管理时,千万不能使用memcpy进行对象之间的拷贝,因为memcpy是浅拷贝,否则可能会引起内存泄漏甚至程序崩溃。
3.尾插尾删(push_back(),pop_back())
void push_back(const T&var) {
if (final_end ==finally) {
size_t newcode = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcode);
}
*final_end = var;
++final_end;
void pop_back() {
final_end--;
}
插入问题一般先要判断空间是否含有闲置空间,如果没有,就要开辟空间。我们final_end==finally来判断是否含有闲置空间。如果容器含没有空间先开辟4字节空间,当满了后开2capacoity()空间。在final_end部插入数据就行了。对final_end加以操作。
4.对insert()插入时迭代器失效刨析
Iteratot insert(Iteratot iterator,const T&var) {
assert(iterator <= final_end && iterator >= start);
size_t pos = iterator - start;
if (final_end == finally) {
size_t newcode = capacity() == 0 ? 4 : capacity() * 2;
reserve(newcode);
}
//插入操作
auto it = final_end;
while (it >= start+pos) {
*(it+1)=*it;
it--;
}
*iterator = var;
final_end++;
return iterator;
}
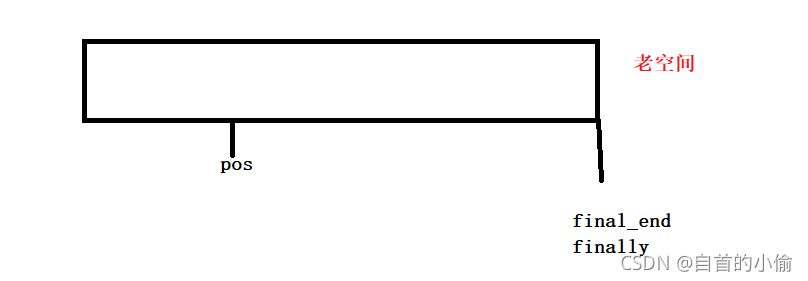
假设这是一段vector空间要在pos插入数据,但是刚刚好final_end和final在同一位置,这个容器满了,要对这这个容器做扩容操作。首先对开辟和这个空间的2呗大小的空间

接着把老空间数据拷贝到新空间中释放老空间。

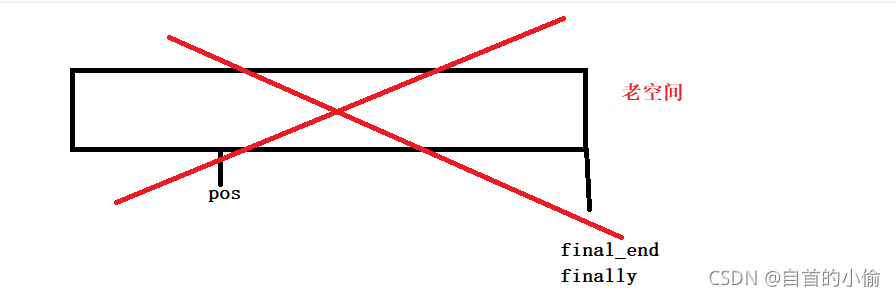
由于老空间释放了pos指向的内存不见了。pos指针就成了野指针。
这如何解决呢就是在老空间解决之间保存这个指针,接着让他重新指向新空间的原来位置。
而insert()函数返回了这个位置迭代器这为迭代器失效提供了方法,这个方法就是重新赋值。让这个指针重新指向该指向的位置。
5.对erase()数据删除时迭代器失效刨析
Iteratot erase(Iteratot iterator) {
assert(iterator <= final_end && iterator >= start);
auto it = iterator;
while (it <final_end) {
*it = *(it+1);
it++;
}
final_end--;
return iterator;
}
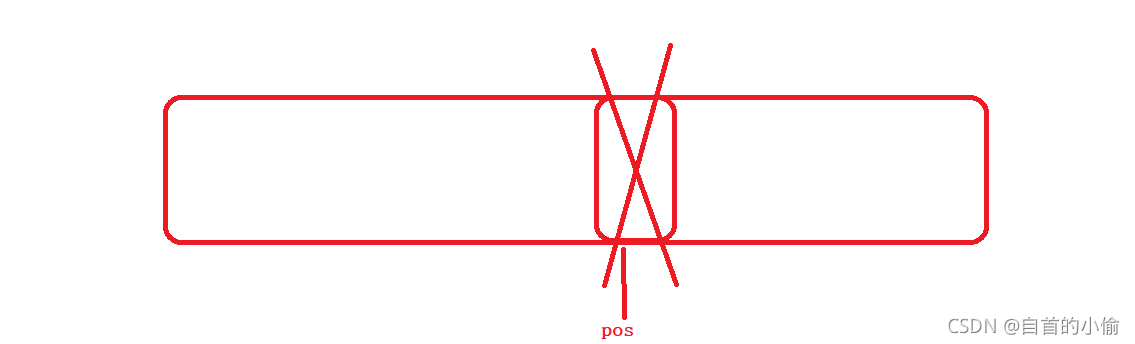
vector使用erase删除元素,其返回值指向下一个元素,但是由于vector本身的性质(存在一块连续的内存上),删掉一个元素后,其后的元素都会向前移动,所以此时指向下一个元素的迭代器其实跟刚刚被删除元素的迭代器是一样的。
以下为解决迭代器失效方案:
#include <vector>
#include <iostream>
using namespace std;
int main()
{
int a[] = {1, 4, 3, 7, 9, 3, 6, 8, 3, 3, 5, 2, 3, 7};
vector<int> vector_int(a, a + sizeof(a)/sizeof(int));
/*方案一*/
// for(int i = 0; i < vector_int.size(); i++)
// {
// if(vector_int[i] == 3)
// {
// vector_int.erase(vector_int.begin() + i);
// i--;
// }
// }
/*方案二*/
// for(vector<int>::iterator itor = vector_int.begin(); itor != vector_int.end(); ++itor)
// {
// if (*itor == 3)
// {
// vector_int.erase(itor);
// --itor;
// }
// }
/*方案三*/
vector<int>::iterator v = vector_int.begin();
while(v != vector_int.end())
{
if(*v == 3)
{
v = vector_int.erase(v);
cout << *v << endl;
}
else{
v++;
}
}
/*方案四*/
// vector<int>::iterator v = vector_int.begin();
// while(v != vector_int.end())
// {
// if(*v == 3)
// {
// vector_int.erase(v);
// }
// else{
// v++;
// }
// }
for(vector<int>::iterator itor = vector_int.begin(); itor != vector_int.end(); itor++)
{
cout << * itor << " ";
}
cout << endl;
return 0;
}
一共有四种方案。
方案一表明vector可以用下标访问元素,显示出其随机访问的强大。并且由于vector的连续性,且for循环中有迭代器的自加,所以在删除一个元素后,迭代器需要减1。
方案二与方案一在迭代器的处理上是类似的,不过对元素的访问采用了迭代器的方法。
方案三与方案四基本一致,只是方案三利用了erase()函数的返回值是指向下一个元素的性质,又由于vector的性质(连续的内存块),所以方案四在erase后并不需要对迭代器做加法。
以上就是C语言数据结构之vector底层实现机制解析的详细内容,更多关于C语言 vector底层机制的资料请关注我们其它相关文章!
相关推荐
-

C语言编程数据结构线性表之顺序表和链表原理分析
目录 线性表的定义和特点 线性结构的特点 线性表 顺序存储 顺序表的元素类型定义 顺序表的增删查改 初始化顺序表 扩容顺序表 尾插法增加元素 头插法 任意位置删除 任意位置添加 线性表的链式存储 数据域与指针域 初始化链表 尾插法增加链表结点 头插法添加链表结点 打印链表 任意位置的删除 双向链表 测试双向链表(主函数) 初始化双向链表 头插法插入元素 尾插法插入元素 尾删法删除结点 头删法删除结点 doubly-Linked list.c文件 doubly-Linkedlist.h 线性表的定
-
C语言数据结构单链表接口函数全面讲解教程
目录 前言 一.链表的概念及结构 1.概念 二.链表的使用 1.遍历整个链表 2.尾插 3.头插 4.头删 5.尾删 6.任意位置插入数据 7.任意位置删除数据 后记 前言 上一期数据结构专栏我们学习了顺序表后:C语言数据结构顺序表 在运用时,细心的同学可能会发现,如果要头插.尾插或者任意位置.如果原先的空间已经被占满了,你是需要扩容的,动态链表扩容往往是2倍,但是扩容后,如果后面没有使用完全扩容后空间就会造成空间浪费,为了解决这个问题,我们今天将学习链表. 提示:以下是本篇文章正文内容,下面案
-
使用C语言实现vector动态数组的实例分享
下面是做项目时实现的一个动态数组,先后加入了好几个之后的项目,下面晒下代码. 头文件: # ifndef __CVECTOR_H__ # define __CVECTOR_H__ # define MIN_LEN 256 # define CVEFAILED -1 # define CVESUCCESS 0 # define CVEPUSHBACK 1 # define CVEPOPBACK 2 # define CVEINSERT 3 # define CVERM 4 # define EXP
-
C语言数据结构进阶之栈和队列的实现
目录 栈的实现: 一.栈的概念和性质 二.栈的实现思路 三.栈的相关变量内存布局图 四.栈的初始化和销毁 五.栈的接口实现: 1.入栈 2.出栈 3.获取栈顶的数据 4.获取栈的元素个数 5.判断栈是否为空 队列的实现: 一.队列的概念和性质 二.队列的实现思路 三.队列相关变量的内存布局图 四.队列的初始化和销毁 五.队列的接口实现: 1. 入数据 2.出数据 3.取队头数据 4.取队尾数据 5.获取队列元素个数 6.判断队列是否为空 总结 栈的实现: 一.栈的概念和性质 栈(stack)又名
-
C语言数据结构创建及遍历十字链表
目录 一.十字链表是什么? 二.十字链表的存储结构 三.代码实现 1.引入头文件并定义结构体 2.建立十字链表 3.遍历十字链表 4.调用函数 本文需要读者有一定的代码基础,了解指针,链表,数组相关知识. 一.十字链表是什么? 十字链表常用于表示稀疏矩阵,可视作稀疏矩阵的一种链式表示,因此,这里以稀疏矩阵为背景介绍十字链表.不过,十字链表的应用远不止稀疏矩阵,一切具有正交关系的结构,都可用十字链表存储. 二.十字链表的存储结构 1.用于总结点的存储结构 m:总行数 n:总列数 len:总元素个数
-
C语言数据结构时间复杂度及空间复杂度简要分析
目录 一.时间复杂度和空间复杂度是什么? 1.1算法效率定义 1.2时间复杂度概念 1.3空间复杂度概念 二.如何计算常见算法的时间复杂度和空间复杂度 2.1时间复杂度计算 2.2空间复杂度计算 2.3快速推倒大O渐进表达法 三.一些特殊的情况 总结 一.时间复杂度和空间复杂度是什么? 1.1算法效率定义 算法效率分为两种,一种是时间效率--时间复杂度,另一种是空间效率--空间复杂度 1.2时间复杂度概念 时间复杂度,简言之就是你写一个代码,它解决一个问题上需要走多少步骤,需要花费多长时间.打个
-
C语言数据结构之单向链表详解分析
链表的概念:链表是一种动态存储分布的数据结构,由若干个同一结构类型的结点依次串连而成. 链表分为单向链表和双向链表. 链表变量一般用指针head表示,用来存放链表首结点的地址. 每个结点由数据部分和下一个结点的地址部分组成,即每个结点都指向下一个结点.最后一个结点称为表尾,其下一个结点的地址部分的值为NULL(表示为空地址). 特别注意:链表中的各个结点在内存中是可以不连续存放的,具体存放位置由系统分配. 例如:int *ptr ; 因此不可以用ptr++的方式来寻找下一个结点. 使用链表的优点
-
C语言数据结构之复杂链表的拷贝
题目: 给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点. 构造这个链表的 深拷贝. 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值.新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态.复制链表中的指针都不应指向原链表中的节点 . 例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y
-
C语言数据结构之vector底层实现机制解析
目录 一.vector底层实现机制刨析 二.vector的核心框架接口的模拟实现 1.vector的迭代器实现 2.reserve()扩容 3.尾插尾删(push_back(),pop_back()) 4.对insert()插入时迭代器失效刨析 5.对erase()数据删除时迭代器失效刨析 一.vector底层实现机制刨析 通过分析 vector 容器的源代码不难发现,它就是使用 3 个迭代器(可以理解成指针)来表示的: 其中statrt指向vector 容器对象的起始字节位置: finish指
-
PHP底层运行机制与工作原理详解
最近搭建服务器,突然感觉lamp之间到底是怎么工作的,或者是怎么联系起来?平时只是写程序,重来没有思考过他们之间的工作原理: PHP底层工作原理 图1 php结构 从图上可以看出,php从下到上是一个4层体系 ①Zend引擎 Zend整体用纯c实现,是php的内核部分,它将php代码翻译(词法.语法解析等一系列编译过程)为可执行opcode的处理并实现相应的处理方法.实现了基本的数据结构(如hashtable.oo).内存分配及管理.提供了相应的api方法供外部调用,是一切的核心,所有的外围功能
-
Golang 语言map底层实现原理解析
在开发过程中,map是必不可少的数据结构,在Golang中,使用map或多或少会遇到与其他语言不一样的体验,比如访问不存在的元素会返回其类型的空值.map的大小究竟是多少,为什么会报"cannot take the address of"错误,遍历map的随机性等等. 本文希望通过研究map的底层实现,以解答这些疑惑. 基于Golang 1.8.3 1. 数据结构及内存管理 hashmap的定义位于 src/runtime/hashmap.go 中,首先我们看下hashmap和buck
-
C语言数据结构顺序表中的增删改(头插头删)教程示例详解
目录 头插操作 头删操作 小结 头插操作 继上一章内容(C语言数据结构顺序表中的增删改教程示例详解),继续讲讲顺序表的基础操作. 和尾插不一样,尾插出手阔绰直接的开空间,咱头插能开吗?好像没听说过哪个接口可以在数据前面开一片空间吧,那我们思路就只有一个了——挪数据.那应该从第一位开始挪吗?注意,这和 memcpy 函数机制是一样的,并不意味着后面数据一起挪动,也不会彼此独立,而是相互影响,挪动的数据会对后面数据进行覆盖. 那我们的逻辑就应该是从后往前挪,那我们就直接定一个下标,指向这段空间的最后
-
C语言数据结构之二叉树的非递归后序遍历算法
C语言数据结构之二叉树的非递归后序遍历算法 前言: 前序.中序.后序的非递归遍历中,要数后序最为麻烦,如果只在栈中保留指向结点的指针,那是不够的,必须有一些额外的信息存放在栈中. 方法有很多,这里只举一种,先定义栈结点的数据结构 typedef struct{Node * p; int rvisited;}SNode //Node 是二叉树的结点结构,rvisited==1代表p所指向的结点的右结点已被访问过. lastOrderTraverse(BiTree bt){ //首先,从根节点开始,
-
C语言数据结构之判断循环链表空与满
C语言数据结构之判断循环链表空与满 前言: 何时队列为空?何时为满? 由于入队时尾指针向前追赶头指针,出队时头指针向前追赶尾指针,故队空和队满时头尾指针均相等.因此,我们无法通过front=rear来判断队列"空"还是"满". 注:先进入的为'头',后进入的为'尾'. 解决此问题的方法至少有三种: 其一是另设一个布尔变量以匹别队列的空和满: 其二是少用一个元素的空间,约定入队前,测试尾指针在循环意义下加1后是否等于头指针,若相等则认为队满(注意:rear所指的单元始
-
C语言数据结构实现字符串分割的实例
C语言数据结构实现字符串分割的实例 以下为"字符串分割"的简单示例: 1. 用c语言实现的版本 #include<stdio.h> /* 根据空格分隔字符串 */ int partition(char *src, char *par, int pos) { int i,j; i = pos; //取到第一个非空格字符 while(src[i] == ' ') { ++i; } if(src[i] != '\0') { j = 0; while((src[i] != '\0'
-
C语言数据结构链表队列的实现
C语言数据结构链表队列的实现 1.写在前面 队列是一种和栈相反的,遵循先进先出原则的线性表. 本代码是严蔚敏教授的数据结构书上面的伪代码的C语言实现代码. 分解代码没有包含在内的代码如下: #include <stdio.h> #include <stdlib.h> #define OK 1 #define ERROR 0 typedef int QElemtype; typedef int status; 2.代码分解 2.1对队列和节点的结构定义 typedef struct
-
C语言数据结构之串插入操作
C语言数据结构之串插入操作 实例代码: /* 串的堆分配存储表示 */ #include<stdio.h> #include<string.h> #include<stdlib.h> #define OK 1 #define ERROR 0 #define TRUE 1 #define FALSE 0 #define OVERFLOW -2 typedef int Status; typedef struct { char *ch; //如果是非空串,则按串长分配存储区
-
C语言数据结构递归之斐波那契数列
C语言数据结构递归之斐波那契数列 因为自己对递归还是不太熟练,于是做POJ1753的时候就很吃力,就是翻棋子直到棋盘上所有棋子的颜色一样为止,求最少翻多少次,方法是枚举递归.然后就打算先做另一道递归的题(从数组中取出n个元素的组合),但是同样在递归的问题上不太理解.好吧,于是复习CPP,在第229页的时候,看到了斐波那契数列,回想起之前做过的一道题目,发现可以用递归的方法来做.于是决定优化一下之前的代码. 以下这段摘自<C primer plus> 斐波那契数列的定义如下:第一个和第二个数字都