MySQL 到Oracle 实时数据同步
目录
- 第一步:配置MySQL 连接
- 第二步:配置 Oracle连接
- 第四步:进行数据校验
- 其他数据库的同步操作
摘要:很多 DBA 同学经常会遇到要从一个数据库实时同步到另一个数据库的问题,同构数据还相对容易,遇上异构数据、表多、数据量大等情况就难以同步。本文亲测了一种方式,可以非常方便地完成 MySQL 数据实时同步到Oracle,跟大家分享一下,希望对你有帮助。
本次 MySQL 数据实时同步到 Oracle大概只花了几分钟就完成。使用的工具是Tapdata Cloud ,这个工具是永久免费的。
MySQL 到Oracle 实时数据同步实操分享
第一步:配置MySQL 连接
1.点击 Tapdata Cloud 操作后台左侧菜单栏的【连接管理】,然后点击右侧区域【连接列表】右上角的【创建连接】按钮,打开连接类型选择页面,然后选择MySQL

【连 接 名 称】:设置连接的名称,多个连接的名称不能重复
【数据库地址】:数据库 IP / Host
【端 口】:数据库端口
【数据库名称】:tapdata 数据库连接是以一个 db 为一个数据源。这里的 db 是指一个数据库实例中的 database,而不是一个 mysql 实例。
【账 号】:可以访问数据库的账号
【密 码】:数据库账号对应的密码
【时 间 时 区】:默认使用该数据库的时区;若指定时区,则使用指定后的时区设置
3.测试连接,提示测试通过

4.测试通过后保存连接即可。
第二步:配置 Oracle连接

第三步:选择同步模式-全量/增量/全+增
进入Tapdata Cloud 操作后台任务管理页面,点击添加任务按钮进入任务设置流程
根据刚才建好的连接,选定源端与目标端。

在以上选项设置完毕后,下一步选择同步类型,平台提供全量同步、增量同步、全量+增量同步,设定写入模式和读取数量。
如果选择的是全量+增量同步,在全量任务执行完毕后,Tapdata Agent 会自动进入增量同步状态。在该状态中,Tapdata Agent 会持续监听源端的数据变化(包括:写入、更新、删除),并实时的将这些数据变化写入目标端。

第四步:进行数据校验
一般同步完成后,我都习惯性进行一下数据校验,防止踩坑。
Tapdata Cloud 有三种校验模式,我常用最快的快速count校验 ,只需要选择到要校验的表,不用设置其他复杂的参数和条件,简单方便。

在进行表全字段值校验时,还支持进行高级校验。通过高级校验可以添加JS校验逻辑,可以对源和目标的数据进行校验。
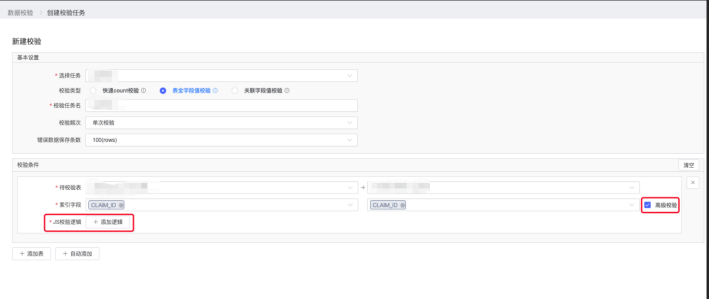
还有一个校验方式关联字段值校验 ,创建关联字段值校验时,除了要选择待校验表外,还需要针对每一个表设置索引字段。

相比自己写代码,简直不要太方便了。以上就是 MySQL数据实时同步到 Oracle 的操作分享,希望上面的操作分享对你有帮助!码字不易,转载请注明出处~
其他数据库的同步操作
其他数据库数据实时同步到 Oracle、MySQL、PG、SQL Server、MongoDB、ES 、达梦、Kafka、GP、MQ、ClickHouse、Hazelcast Cloud、ADB MySQL、ADB PostgreSQL、KunDB、TiDB、Dummy DB 的方式也都是先配置源和目标的连接,然后新建任务选择同步模式:全量/增量/全量+增量,因为步骤相同,其他就不再贴图说明了。创建连接的时候,有没有发现:DB2、Sybase、Gbase 几个数据库现在是灰色锁定状态,应该是在开发中了,可能后续也会支持这些数据库的同步功能。Tapdata Cloud 是承诺永久免费使用的,不过要求更高、有预算的朋友也可以使用企业版,具体可访问Tapdata官网:tapdata.net ,还可以申请试用。
到此这篇关于MySQL 到Oracle 实时数据同步的文章就介绍到这了,更多相关MySQL 到Oracle 实时数据同步内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Oracle通过LogMiner实现数据同步迁移
写在前面 最近在研究如何实现Oracle数据库之间的数据同步,网上的资料确实比较少.最好用的Oracle数据库同步工具是:GoldenGate ,而GoldenGate是要收费的.那么还有什么好的办法来同步Oracle的数据吗?没错,就是使用LogMiner来实现Oracle数据同步迁移. 实现过程 1.创建目录 在服务器上创建/home/oracle/tools/oracle11g/oradata/orcl/LOGMNR目录来存储数据库的字典信息,如下所示. mkdir -p /home/or
-
通过LogMiner实现Oracle数据库同步迁移
目录 通过LogMiner实现Oracle数据同步迁移 一.实现过程 1.创建目录 2.配置LogMiner 3.开启日志追加模式 4.重启数据库 5.创建数据同步用户 6.创建数据字典 7.加入需要分析的日志文件 8.查看正在使用的日志文件 9.使用Lominer分析日志 10.查看分析结果 11.常见问题 通过LogMiner实现Oracle数据同步迁移 为了实现Oracle数据库之间的数据同步,网上的资料比较少的时候.最好用的Oracle数据库同步工具是:GoldenGate ,而Gold
-

Oracle同步数据到kafka的方法
目录 环境准备 软件准备 下载地址 实施过程 Oracle主机(A)配置 Kafka主机(B)配置 配置apache-maven工具 配置Kafka 2.13-2.6.0 配置kafka-connect-oracle-maste 启动kafka-connect-oracle 启动kafka消费者 启动数据库JOB 环境准备 软件准备 CentOS Linux 7.6.1810 (2台,A主机,B主机) Oracle 11.2.0.4(A主机安装) Kafka 2.13-2.6.0 (B主机安装)
-
MySQL 到Oracle 实时数据同步
目录 第一步:配置MySQL 连接 第二步:配置 Oracle连接 第四步:进行数据校验 其他数据库的同步操作 摘要:很多 DBA 同学经常会遇到要从一个数据库实时同步到另一个数据库的问题,同构数据还相对容易,遇上异构数据.表多.数据量大等情况就难以同步.本文亲测了一种方式,可以非常方便地完成 MySQL 数据实时同步到Oracle,跟大家分享一下,希望对你有帮助. 本次 MySQL 数据实时同步到 Oracle大概只花了几分钟就完成.使用的工具是Tapdata Cloud ,这个工具是永久免费
-
MySQL 到Oracle 实时数据同步
目录 第一步:配置MySQL 连接 第二步:配置 Oracle连接 第四步:进行数据校验 其他数据库的同步操作 摘要:很多 DBA 同学经常会遇到要从一个数据库实时同步到另一个数据库的问题,同构数据还相对容易,遇上异构数据.表多.数据量大等情况就难以同步.本文亲测了一种方式,可以非常方便地完成 MySQL 数据实时同步到Oracle,跟大家分享一下,希望对你有帮助. 本次 MySQL 数据实时同步到 Oracle大概只花了几分钟就完成.使用的工具是Tapdata Cloud ,这个工具是永久免费
-
MySQL 到 ClickHouse 实时数据同步实操
摘要: 很多 DBA 同学经常会遇到要从一个数据库实时同步到另一个数据库的问题,同构数据还相对容易,遇上异构数据.表多.数据量大等情况就难以同步.我自己亲测了一种方式,可以非常方便地完成 MySQL 数据实时同步到ClickHouse,跟大家分享一下,希望对你有帮助. MySQL 到 ClickHouse 实时数据同步实操分享 本次 MySQL 数据实时同步到ClickHouse大概只花了几分钟就完成.使用的工具是Tapdata Cloud ,这个工具是永久免费的. @[TOC](MySQL 到
-
MySQL高性能实现Canal数据同步神器
目录 简介 配置MySQL centos7 安装 canal java客户端 简介 Canal是阿里巴巴基于Java开源的数据同步工具.平时业务场景使用比较多的如下: 同步数据到ES.Redis缓存中. 数据同步. 业务需要监听数据. 图片来源阿里巴巴github仓库:https://github.com/alibaba/canal 配置MySQL 跟配置主从复制类似. 数据执行如下命令: -- 给canal单独创建用户 用户名:canal 密码:123456 create user 'cana
-
浅析Mysql和Oracle分页的区别
目录 MySQL使用limit进行分页 Oracle使用rownum进行分页 Mysql与Oracle级联查询 Mysql省市区级联查询 Mysql与Oracle插入数据存在修改不存在新增 MySQL使用limit进行分页 select * from stu limit m,n; // m=(pageIndex-1)*pageSize,n=pageSize -- 返回总条,查询表添加字段sql_calc_found_rows select sql_calc_found_rows a.* from
-
减少mysql主从数据同步延迟问题的详解
基于局域网的master/slave机制在通常情况下已经可以满足'实时'备份的要求了.如果延迟比较大,就先确认以下几个因素: 1. 网络延迟2. master负载3. slave负载一般的做法是,使用多台slave来分摊读请求,再从这些slave中取一台专用的服务器,只作为备份用,不进行其他任何操作,就能相对最大限度地达到'实时'的要求了 另外,再介绍2个可以减少延迟的参数 –slave-net-timeout=seconds 参数含义:当slave从主数据库读取log数据失败后,等待多久重新
-
详解Mysql如何实现数据同步到Elasticsearch
目录 一.同步原理 二.logstash-input-jdbc 三.go-mysql-elasticsearch 四.elasticsearch-jdbc 五.logstash-input-jdbc实现同步 六.go-mysql-elasticsearch实现同步 七.elasticsearch-jdbc实现同步 一.同步原理 基于Mysql的binlog日志订阅:binlog日志是Mysql用来记录数据实时的变化 Mysql数据同步到ES中分为两种,分别是全量同步和增量同步 全量同步表示第一次
-
MySQL特定表全量、增量数据同步到消息队列-解决方案
目录 1.原始需求 2.解决方案 3.canal介绍.安装 canal的工作原理 架构 安装 4.验证 1.原始需求 既要同步原始全量数据,也要实时同步MySQL特定库的特定表增量数据,同时对应的修改.删除也要对应. 数据同步不能有侵入性:不能更改业务程序,并且不能对业务侧有太大性能压力. 应用场景:数据ETL同步.降低业务服务器压力. 2.解决方案 3.canal介绍.安装 canal是阿里巴巴旗下的一款开源项目,纯Java开发.基于数据库增量日志解析,提供增量数据订阅&消费,目前主要支持了M
-
mysql 触发器实现两个表的数据同步
mysql通过触发器实现两个表的同步 目前,在本地测试成功. 假设本地的两个数据库a和b,a下有表table1(id, val) b下有表table2(id, val) 假设希望当table1中数据更新,table2中数据同步更新. 代码: DELIMITER $$ CREATE /*[DEFINER = { user | CURRENT_USER }]*/ TRIGGER `a`.`触发器名` BEFORE UPDATE ON `a`.`table1` FOR EACH ROW BEGIN I
-
怎么使 Mysql 数据同步
怎么使 Mysql 数据同步 先假设有主机 A 和 B ( Linux 系统),主机 A 的 IP 分别是 1.2.3.4 (当然,也可以是动态的),主机 B 的 IP 是 5.6.7.8 .两个主机都装上了 PHP+Mysql ,现在操作的是主机 A 上的资料,如果另外一个主机 B 想跟 A 的资料进行同步,应该怎么做呢? OK,我们现在就动手. 首先,如果要想两个主机间的资料同步,一种方法就是主机 A 往主机 B 送资料,另外一种主法就是主机 B 到主机 A 上拿资料,因为 A 的 IP 是