elasticsearch的灵魂唯一master选举机制原理分析
master作为cluster的灵魂必须要有,还必须要唯一,否则集群就出大问题了。因此master选举在cluster分析中尤为重要。对于这个问题我将分两篇来分析。第一篇也就是本篇,首先会简单说一说mater选举的一些算法,及elasticsearch的选举原理。第二篇也就是下一篇,会结合zenDiscovery代码为仔细分析elasticsearch的master选举的实现。
简单来说master的作用跟单个jvm中的同步关键字synchronized相同,集群中多节点协调工作必须要保证数据的一致性,但是不同节点分布在不同的jvm中,不可能用jvm的同步机制。所以需要一个“锁”,节点操作集群中的资源时都通过它来解决一致性问题,这就是master。关于分布式系统的master选举算法有很多,最有名的当然要数paxos算法,在它的基础上出现了非常多的变体算法。关于这个算法请参考相关网页和资料,不是一两句话能说清楚的,这里不再祥述。但是paxos的功能远远超出了master选举,一致性向才是它的目标,任何需要实现一致性的问题都可以使用该算法,因此zookeeper功能远远不止master选举。
还有一种比较简单的算法就是Bully,它通过一定的直接给每个节点赋予一唯一的ID,这些ID是可以排序的,每次master选举都会选举ID最大的节点。这种实现非常简单。但是会存在一些问题,在master负载过重时它会假死,于是第二大节点就成为了master节点。因此假死master节点因负载减轻又活了过来,于是他又被选为master,然后又假死……,这种情况可能一直存在导致系统不稳定。
集群还有一个问题就是brain split:一个集群因为网络问题导致多个master选举出来而分裂。这也是master选举必须要解决的问题。elasticsearch的master选举原理我觉得是在bully的基础上做了改进。相比于paxos实现的zookeeper它完美的解决了master选举问题,但不如zookeeper强大,因为zookeeper功能远远超出了master选举,它的master选举却不需要这么多功能。它原理如下:
- 对所有可以成为master的节点根据nodeId排序,每次选举每个节点都把自己所知道节点排一次序,然后选出第一个(第0位)节点,暂且认为它是master节点。
- 如果对某个节点的投票数达到一定的值(可以成为master节点数n/2+1)并且该节点自己也选举自己,那这个节点就是master。否则重新选举。
- 对于brain split问题,需要把候选master节点最小值设置为可以成为master节点数n/2+1(quorum )
以上就是master选举的三条原则,其实第三天包含在第二条之中,为了说明brain split问题这里单独拿出来说一下。下面看一下ElectMasterService的相关代码,来补充说明一下一上的文字描述:
public DiscoveryNode electMaster(Iterable<DiscoveryNode> nodes) {
List<DiscoveryNode> sortedNodes = sortedMasterNodes(nodes);
if (sortedNodes == null || sortedNodes.isEmpty()) {
return null;
}
return sortedNodes.get(0);
}
上面就是选举master的方法,可以看到,它的做法就是对候选节点排序然后直接将第一个返回。当然这只是上面所说的第一条。其实只有这个是不能够保证maser选举顺利的,之前也看到一些文章分析elasticsearch的master选举,只提到了这个点和这一部分代码,应该是作者没有仔细研究Discovery代码而导致的疏忽。如果每个节点都只是选举自己排序后的节点的第一个肯定会导致brain split和选举不一致。master比较的方法也比较简单如下所示:
private static class NodeComparator implements Comparator<DiscoveryNode> {
@Override
public int compare(DiscoveryNode o1, DiscoveryNode o2) {
if (o1.masterNode() && !o2.masterNode()) {
return -1;
}
if (!o1.masterNode() && o2.masterNode()) {
return 1;
}
return o1.id().compareTo(o2.id());
}
}
以上是节点排序比较器,可以看到它只是比较了nodeId,因此是按nodeId排序。从这两两段代码来看很像是bully算法的实现。为了解决brain split问题开发者加入了master候选数据量限制,代码如下:
public boolean hasEnoughMasterNodes(Iterable<DiscoveryNode> nodes) {
if (minimumMasterNodes < 1) {
return true;
}
int count = 0;
for (DiscoveryNode node : nodes) {
if (node.masterNode()) {
count++;
}
}
return count >= minimumMasterNodes;
}
通过比较节点能“看到”的候选master数量和配置的最小值来确定是否可以进行选举,如果数量不够会导致选举不能进行,这样就可以保证集群不会被分裂。下面以一个图(图片来自于elasticsearch官网)来说明:
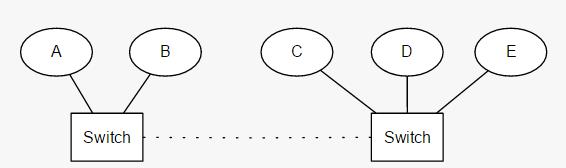
假设之前选举了A节点为master,两个switch之间突然断线了,这样就分词了两部分。CDE和AB,因为 minimumMasterNodes的数目为3(集群中5个节点都可以成为master,3=5/2+1),因此cde会可以进行选举假设C成为master。AB两个节点因为少于3所以无法选举,只能一直寻求加入集群,要么线路连通加入到CDE中要么就一直处于寻找集群状态,这样就保证了集群不分裂。
总结一下,本篇介绍了master选举的两种算法和elasticsearch的选举原理,并分析了它原理中的两条,第二条将在下一篇discovery中接下分析。
以上就是elasticsearch的灵魂唯一master选举机制原理分析的详细内容,更多关于elasticsearch唯一master选举机制的资料请关注我们其它相关文章!
相关推荐
-
SpringBoot集成ElasticSearch的示例代码
目录 一.Elasticseach介绍 1.简单介绍 2.对比关系: 3.详细说明: 4.查出数据的解释 二.SpringBoot集成Elasticseach 1.引入依赖 2.添加配置 3.创建pojo类与索引对应 4.SpringData封装了基础的增删改查,自定义增删改查 5.测试方法--增删改查 一.Elasticseach介绍 1.简单介绍 官网:开源搜索:Elasticsearch.ELK Stack 和 Kibana 的开发者 | Elastic https://www.elast
-
elasticsearch的zenDiscovery和master选举机制原理分析
目录 前言 join的代码 findMaster方法 总结 前言 上一篇通过 ElectMasterService源码,分析了master选举的原理的大部分内容:master候选节点ID排序保证选举一致性及通过设置最小可见候选节点数目避免brain split.节点排序后选举只能保证局部一致性,如果发生节点接收到了错误的集群状态就会选举出错误的master,因此必须有其它措施来保证选举的一致性.这就是上一篇所提到的第二点:被选举的数量达到一定的数目同时自己也选举自己,这个节点才能成为master
-
java 通过聚合查询实现elasticsearch的group by后的数量
通过聚合查询获取group by 后的数量 /** * 获取key的个数 * * @param key 要group by的字段名 * @param index 索引名称 * @return id的个数 */ public static int getKeyCount(String key, String index) { int count = 0; TransportClient client = null; try { client = connectionPool.getConnecti
-

Springboot集成Elasticsearch的步骤与相关功能
目录 集成配置步骤 步骤1:加入 Maven 相关依赖 步骤2:配置 elasticsearch 的主机和端口 步骤3:配置 Elaseticsearch 客户端 步骤4:创建文档实体 步骤5:创建 controller,service, dao 层 相关功能实现 1. 添加文档 2. 修改文档 3. 根据ID查询文档 4. 根据ID删除文档 5. 查询所有文档 6. 条件查询(单个条件) 7. 条件查询(多条件) 8. 分页查询(降序) 9. 分页查询(升序) 10. 分页查
-
Elasticsearch映射字段数据类型及管理
目录 Elasticsearch映射管理 一 映射介绍 1.1 字段数据类型 1.2 映射参数 二 创建索引 三 查看索引 Elasticsearch映射管理 在Elasticsearch 6.0.0或更高版本中创建的索引只包含一个mapping type. 在5.x中使用multiple mapping types创建的索引将继续像以前一样在Elasticsearch 6.x中运行. Mapping types将在Elasticsearch 7.0.0中完全删除 一 映射介绍 在创建索引的时候
-
elasticsearch的灵魂唯一master选举机制原理分析
master作为cluster的灵魂必须要有,还必须要唯一,否则集群就出大问题了.因此master选举在cluster分析中尤为重要.对于这个问题我将分两篇来分析.第一篇也就是本篇,首先会简单说一说mater选举的一些算法,及elasticsearch的选举原理.第二篇也就是下一篇,会结合zenDiscovery代码为仔细分析elasticsearch的master选举的实现. 简单来说master的作用跟单个jvm中的同步关键字synchronized相同,集群中多节点协调工作必须要保证数据的
-
PHP进阶学习之类的自动加载机制原理分析
本文实例讲述了PHP类的自动加载机制.分享给大家供大家参考,具体如下: 前言 我们在常见的PHP的主流框架中通常写好一个类只需写好相应的命名空间或直接实例化类就可以实现类的使用.而不需要使用原生的方式把类文件一个个用require.include引入包含进来,这归功于PHP的类自动加载机制,也是本文讨论的要点. 一.概念 在PHP代码中,不需要显式地使用文件路径将类库文件包含进来,便可使用该文件中定义的类库,这种技术称作自动加载. 在使用类或者定义了命名空间的类时,只需要直接实例化使用,PHP机
-
Python语法垃圾回收机制原理解析
一 引入 解释器在执行到定义变量的语法时,会申请内存空间来存放变量的值,而内存的容量是有限的,这就涉及到变量值所占用内存空间的回收问题,当一个变量值没有用了(简称垃圾)就应该将其占用的内存给回收掉,那什么样的变量值是没有用的呢? 由于变量名是访问到变量值的唯一方式,所以当一个变量值不再关联任何变量名时,我们就无法再访问到该变量值了,该变量值就是没有用的,就应该被当成一个垃圾回收. 毫无疑问,内存空间的申请与回收是非常耗费精力的事情,而且存在很大的危险性,稍有不慎就有可能引发内存溢出问题,好在Cp
-
JAVA中实现原生的 socket 通信机制原理
本文介绍了JAVA中实现原生的 socket 通信机制原理,分享给大家,具体如下: 当前环境 jdk == 1.8 知识点 socket 的连接处理 IO 输入.输出流的处理 请求数据格式处理 请求模型优化 场景 今天,和大家聊一下 JAVA 中的 socket 通信问题.这里采用最简单的一请求一响应模型为例,假设我们现在需要向 baidu 站点进行通信.我们用 JAVA 原生的 socket 该如何实现. 建立 socket 连接 首先,我们需要建立 socket 连接(核心代码) impor
-
Java等待唤醒机制原理实例解析
这篇文章主要介绍了Java等待唤醒机制原理实例解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 线程的状态 首先了解一下什么是线程的状态,线程状态就是当线程被创建(new),并且启动(start)后,它不是一启动就进入了执行状态(run),也不是一直都处于执行状态. 这里说一下Java 的Thread类里面有一个State方法,这个方法里面涵盖了6种线程的状态,如下: public enum State { // 尚未启动的线程的线程状态.
-
SpringBoot服务监控机制原理解析(面试官常问)
前言 任何一个服务如果没有监控,那就是两眼一抹黑,无法知道当前服务的运行情况,也就无法对可能出现的异常状况进行很好的处理,所以对任意一个服务来说,监控都是必不可少的. 就目前而言,大部分微服务应用都是基于 SpringBoot 来构建,所以了解 SpringBoot 的监控特性是非常有必要的,而 SpringBoot 也提供了一些特性来帮助我们监控应用. 本文基于 SpringBoot 2.3.1.RELEASE 版本演示. SpringBoot 监控 SpringBoot 中的监控可以分为 H
-
PHP反射机制原理与用法详解
本文实例讲述了PHP反射机制原理与用法.分享给大家供大家参考,具体如下: 反射 面向对象编程中对象被赋予了自省的能力,而这个自省的过程就是反射. 反射,直观理解就是根据到达地找到出发地和来源.比如,一个光秃秃的对象,我们可以仅仅通过这个对象就能知道它所属的类.拥有哪些方法. 反射是指在PHP运行状态中,扩展分析PHP程序,导出或提出关于类.方法.属性.参数等的详细信息,包括注释.这种动态获取信息以及动态调用对象方法的功能称为反射API. 如何使用反射API <?php class person{
-
理解zookeeper选举机制
zookeeper集群 配置多个实例共同构成一个集群对外提供服务以达到水平扩展的目的,每个服务器上的数据是相同的,每一个服务器均可以对外提供读和写的服务,这点和redis是相同的,即对客户端来讲每个服务器都是平等的. 这篇主要分析leader的选择机制,zookeeper提供了三种方式: LeaderElection AuthFastLeaderElection FastLeaderElection 默认的算法是FastLeaderElection,所以这篇主要分析它的选举机制. 选择机制中的概
-
PHP面向对象自动加载机制原理与用法分析
本文实例讲述了PHP面向对象自动加载机制原理与用法.分享给大家供大家参考,具体如下: 在学习PHP的面向对象的时候,会知道很多"语法糖",也就是魔术方法.有一个加自动加载的魔术方法,叫:__autoload(); 先看一段代码 <?php function __autoload($classname) { $filename = "./". $classname .".php"; include_once($filename); } new