C语言一篇精通链表的各种操作
目录
- 前言
- 一、链表的介绍
- 1.什么是链表
- 2.链表的分类
- 2.1.根据方向
- 2.2.头结点
- 2.3.循环/非循环
- 二、链表的实现
- 1.结构体
- 2.开辟结点
- 3.打印
- 4.尾插
- 5.头插
- 6.测试
- 7.头删/尾删
- 8.查找
- 9.在pos的前面插入x
- 10.删除pos位置的值
- 三、主函数Test
- 结束语
前言
关于线性表的一些相关介绍,大家可以看看我们之前写的点我-链表
点我-顺序表,里面有一些相关的知识介绍,都是比较基础的,一些比较常见的操作里面也有具体的介绍与实现到,然后呢,今天我们学习的是链表,相比于之前的操作实现更加具有深度,对于一些比较简单的操作这里就不加说明了。而且涉及到之前未说到的一些知识,对此我们可以强化对其认识,这就是写这篇博客的目的。
编译工具:vs2019,小伙伴们可以一起跟着来敲敲代码。
开始之前:很有必要提醒大家注意二级指针的使用,为什么会用到二级指针,我的博客也有一些相关介绍,简单来说,传值参数并不改变实参,传址参数改变形参。
一、链表的介绍
1.什么是链表
简单来说,就是一条链子连接成的表,上面的链接也有比较正式规矩的介绍。
与顺序表相比,链表的最大特点就是不要求物理空间连续,插入不需要移动大量的数据

怎么去联系各个结点呢?
从上图其实不难发现,搞个指针连接起来就行了。既要有数据域和指针域,注意一点:最后一个元素的指针域为NULL。上面的箭头实际并不存在,只是为了看起来比较直接,形象化起来。那要怎么去表示出来了?可以用结构体的自引用。
2.链表的分类
之前并没说到链表的类型有哪些,根据类型的不同,我们实际上可以对其进行分类,由于都是基于单链表实现操作,因此需要学好单链表,进行深化学习。
2.1.根据方向
单向/双向链表
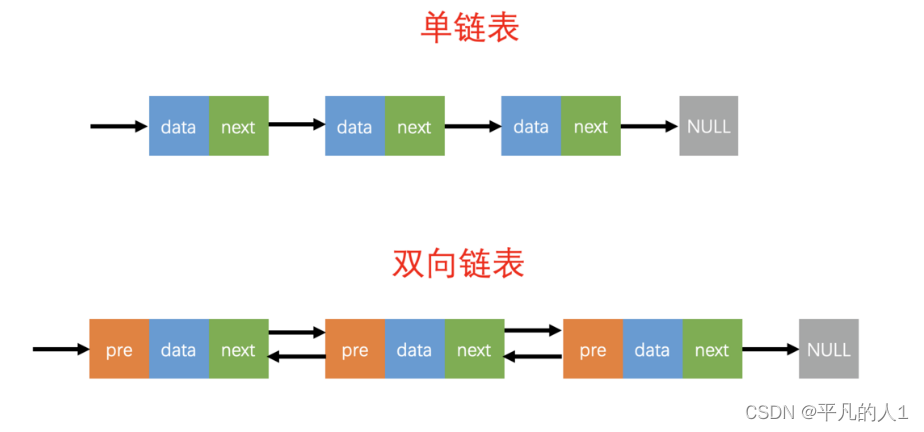
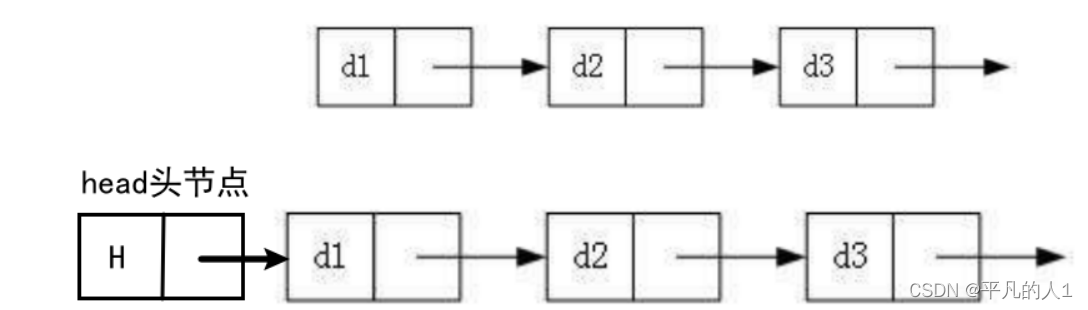
2.2.头结点
带头结点/不带头结点
2.3.循环/非循环
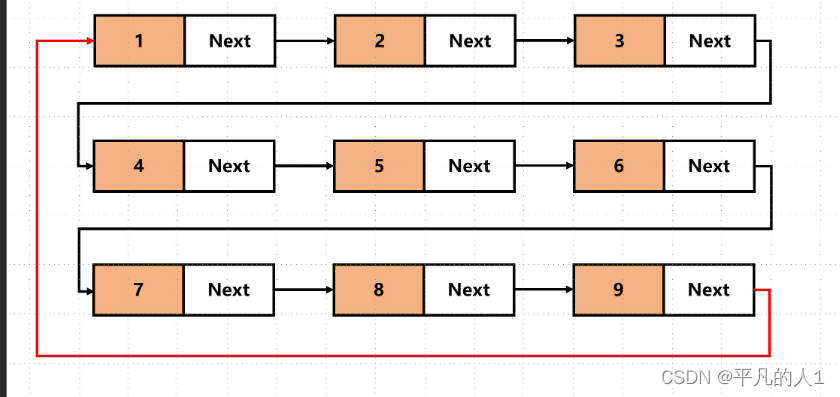
二、链表的实现
链表的实现当然离不开我们自己动手去敲代码了,这首先需要准备好我们的编译环境,vs2019,同时,每次写完一块模板,我们要去测试一下有没有bug,方便我们去找错误,进行调试,这样会大大减少我们的工作量。
1.结构体
链表我们该如何去表示呢?其实,通过上面的例子,我们大致已经知道,需要一个地方来存放数据,另一个地方存放下一个结点的地址。我们可以通过结构体来定义,具体代码如下:
#include <stdio.h>
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data;
struct SListNode* next;
}SLTNode;
2.开辟结点
后续操作会频繁动态开辟一个头结点,我们不妨把它封装成一个函数,便于后面方便使用。当然,你如果觉得自己每次都可以自己写的话,也不必写成一个函数。
//创建新结点
SLTNode* BuySListNode(SLTDataType x) {
SLTNode* newnode = (SLTNode*)malloc(sizeof(SLTNode));
newnode->data = x;
newnode->next = NULL;
return newnode;
}
注意点:新结点的指针域置为空!
3.打印
先别急,我们先来试试水,先尝试自己动手写一下打印的函数。
这里为了比较更加形象起来,每次打印的时候都会用->来连接,同时,最后用NULL结尾
void SListPrint(SLTNode* phead)
{
SLTNode*cur = phead;
while (cur != NULL)
{
printf("%d->", cur->data);
cur = cur->next;
}
printf("NULL\n");
}
4.尾插
什么是尾插?根据字面意思,就是将新结点插入到到链表的尾部。
为了让大家更好理解,特地上网找了一张图片,一起来看看把
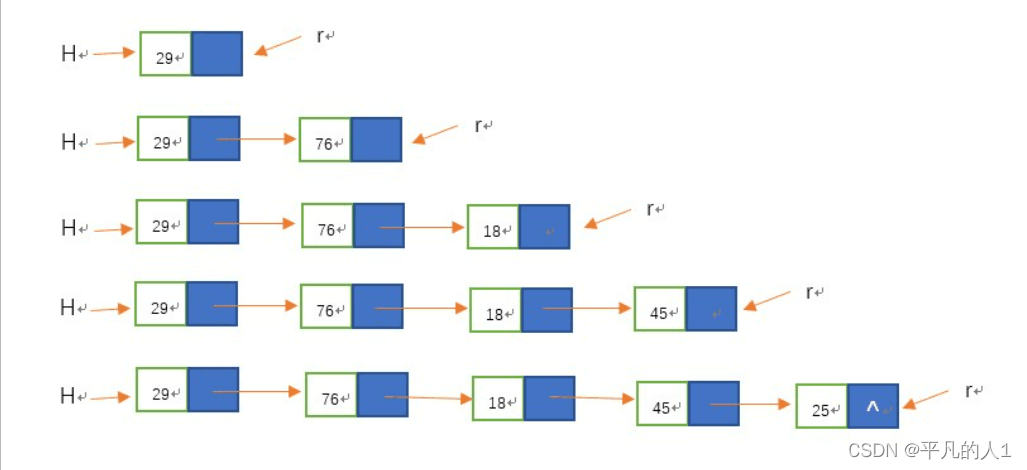
每一次插入一个数都放在最后一个位置,同时,最后一个结点的指针域置为空,关键的就是,我们如何找到当前链表的尾结点呢?前面已经说了,最后一个结点的指针域为空,我们可以以此为突破点。注意:当链表为空时,你会怎么处理?想想。这里先不说了,直接看看我们的代码。
//尾插
void SListPushBack(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x);
if (*pphead == NULL)
{
*pphead = newnode;
}
else {
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
tail = tail->next;
}
tail->next = newnode;
}
}
细心的你应该注意到了,这里我们使用的都是二级指针pphead
因为假设我们使用一级指针,直接传入头指针phead时,头指针本身就是一级指针的了,当我们需要更改该指针指向的地址时,改动只会在函数内部生效,main函数中的phead指针并没有被改变。要想改变的话,就需要二级指针来进行操作了
5.头插
有尾插自然就会有头插,相比较与尾插而言,头插显得更加简单了,直接把新的结点放在头结点前不就ok了?
//头插
void SListPushFront(SLTNode** pphead, SLTDataType x)
{
SLTNode* newnode = BuySListNode(x);
newnode->next = *pphead;
*pphead = newnode;
}
6.测试
好了,到这里,我们已经有一些函数了,不急,我们先来测试测试效果如何
void TestSList1()
{
SLTNode* plist = NULL;
SListPushBack(&plist, 1);
SListPushBack(&plist, 2);
SListPushBack(&plist, 3);
SListPushBack(&plist, 4);
SListPushFront(&plist, 0);
SListPrint(plist);
}
int main()
{
TestSList1();
}
运行结果如下:

我们必须养成边写代码边测试的习惯,这有利于我们及时发现自己的错误,不易导致后面出现一大堆bug而自己却不知道错在哪。当然,除此之外,我们还可以通过调试的方法,快速准确发现自己的bug,这也是我们需要养成的。这些都是需要我们去关注的点。
好啦,下面我不会在像上面那么详细的说明了,我们直接来个头删尾删
7.头删/尾删
有头插尾插,自然有头删尾删,其实,不知道你们发现,不管是插还是删,关于头部的操作都是比较简单了,我们先来个开胃菜,头删:可不能直接删哦,我们要记录头结点的下一个位置,如何直接删了头结点的话,那就麻烦,会造成野指针的,自己好好捋捋。
//头删
void SListpopFront(SLTNode**pphead)
{
SLTNode* next = (*pphead)->next;
free(*pphead);
*pphead = next;
}
尾删:说起尾删,就要多注意点了,要看具体情况而言了,直接来看代码把
//尾删
void SListPopBack(SLTNode** pphead)
{
//链表为空
if (*pphead == NULL)
{
return;
}
//只有一个结点
else if ((*pphead)->next == NULL)
{
free(*pphead);
*pphead = NULL;
}
//有一个以上的结点
else {
SLTNode* prev = NULL;
SLTNode* tail = *pphead;
while (tail->next != NULL)
{
prev = tail;
tail = tail->next;
}
free(tail);
prev->next = NULL;
}
}
尾删的关键点在于找到最后一个结点,最后一个结点的指针域为空。
1.链表为空时,不需要删,
2.链表只有一个结点,那它自己就是最后一个结点了,
3.多个结点就按常规处理就ok了,该说清楚的还是要说清楚的。
8.查找
查找这个操作其实是比较简单的,在这里说是为了后面的使用,想要找到摸个元素,直接去调用函数即可,不用自己一次次去遍历。
SLTNode* SListFind(SLTNode* phead, SLTDataType x)
{
SLTNode* cur = phead;
while (cur)
{
if (cur->data == x)
{
return cur;
}
cur = cur->next;
}
return NULL;
}
9.在pos的前面插入x
除了基本的头尾增加,我们还可能还需要在某一个特定节点前后进行插入,这就需要我们玩转起来了,变得更加灵活。
两个核心点:
1.pos 的位置
2.插入的操作(这里可能有的同学会有一些疑惑,其实只要知道一点,插入的位置是已经知道的了)
//在pos的前面插入x
void SListInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x)
{
if (pos == *pphead) {
SListPushFront(pphead,x);
}
else {
SLTNode* newnode = BuySListNode(x);
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = newnode;
newnode->next = pos;
}
}
10.删除pos位置的值
关键的一点,如何找到pos,找到之后链表跳过它,然后删除即可。
//删除pos位置的值
void SListErase(SLTNode** pphead, SLTNode* pos)
{
if (pos == *pphead)
{
SListpopFront(pphead);
}
else
{
SLTNode* prev = *pphead;
while (prev->next != pos)
{
prev = prev->next;
}
prev->next = pos->next;
free(pos);
}
}
三、主函数Test
这个没啥好说的,自己可以去试试
这只是单纯的试试函数能不能调用起来,自己可以动气手来试一试
结束语
好啦,这次想说的主要都讲完了,其实学数据结构除了实现之外,我们还需要及时去刷一些OJ题,提高我们的能力,使自己的知识融会贯通起来
相关推荐
-
C语言数据结构 双向链表的建立与基本操作
C语言数据结构 双向链表的建立与基本操作 双向链表比单链表有更好的灵活性,其大部分操作与线性表相同.下面总结双向链表与单链表之间的不同之处及我在实现过程中所遇到的问题. 1.双向链表的建立 双向链表在初始化时,要给首尾两个节点分配内存空间.成功分配后,要将首节点的prior指针和尾节点的next指针指向NULL,这是十分关键的一步,因为这是之后用来判断空表的条件.同时,当链表为空时,要将首节点的next指向尾节点,尾节点的prior指向首节点. 2.双向链表的插入操作 由于定义双向链表时指针域中
-
C语言 数据结构链表的实例(十九种操作)
C语言 数据结构链表的实例(十九种操作) #include <stdio.h> #include <string.h> #include <stdlib.h> /*************************************************************************************/ /* 第一版博主 原文地址 http://www.cnblogs.com/renyuan/archive/2013/05/21/30915
-
C语言链表完整操作演示
本文实例为大家分享了C链表操作演示的具体代码,供大家参考,具体内容如下 头文件:link_0505.h /* 链表演示 */ #ifndef __LINK_0505 #define __LINK_0505 typedef struct node{ int num; struct node* p_next; }node; typedef struct { node head,tail; }link; //链表的初始化函数 void link_init(link *); //链表的清理函数 void
-
C语言实现带头结点的链表的创建、查找、插入、删除操作
本文实例讲述了C语言实现带头结点的链表的创建.查找.插入.删除操作.是数据结构中链表部分的基础操作.分享给大家供大家参考.具体方法如下: #include <stdio.h> #include <stdlib.h> typedef struct node { int data; struct node* next;// 这个地方注意结构体变量的定义规则 } Node, *PNode; Node* createLinklist(int length) { int i = 0; PNo
-

C语言创建和操作单链表数据结构的实例教程
1,为什么要用到链表 数组作为存放同类数据的集合,给我们在程序设计时带来很多的方便,增加了灵活性.但数组也同样存在一些弊病.如数组的大小在定义时要事先规定,不能在程序中进行调整,这样一来,在程序设计中针对不同问题有时需要3 0个大小的数组,有时需要5 0个数组的大小,难于统一.我们只能够根据可能的最大需求来定义数组,常常会造成一定存储空间的浪费. 我们希望构造动态的数组,随时可以调整数组的大小,以满足不同问题的需要.链表就是我们需要的动态数组.它是在程序的执行过程中根据需要有数据存储就向系统要求
-
C语言实现数据结构和双向链表操作
数据结构 双向链表的实现 双向链表中的每一个结点都含有两个指针域,一个指针域存放其后继结点的存储地址,另一个指针域则存放其前驱结点的存储地址. 双向链表结点的类型描述: //双向链表的类型描述 typedef int ElemType; typedef struct node{ ElemType data; struct node *prior,*next; }DuLNode,*DuLinkList; 其中,prior域存放的是其前驱结点的存储地址,next域存放的是其后继结点的存储地址. 双
-
C语言单链表常见操作汇总
C语言的单链表是常用的数据结构之一,本文总结了单链表的常见操作,实例如下: #include<stdio.h> #include<stdlib.h> //定义单链表结构体 typedef int ElemType; typedef struct Node { ElemType data; struct Node *next; }LNode,*LinkList; //创建单链表 void Build(LinkList L) { int n; LinkList p,q; p=L; pr
-
C语言 超详细模拟实现单链表的基本操作建议收藏
目录 1 链表的概念及结构 2 链表的分类 3 链表的实现无头+单向+非循环链表增删查改实现 3.1 链表的定义 3.2 链表数据的打印 3.3 链表的尾插 3.4 链表空间的动态申请 3.5 链表的头插 3.6 链表的尾删 3.7 链表的头删 3.8 链表任意位置的前插入 3.9 链表任意位置的后插入 3.10 链表的任意位置的删除 3.11 链表的任意位置的前删除 3.12 链表的任意位置的后删除 3.13 链表的销毁 3.14 链表的总结 1 链表的概念及结构 概念:链表是一种物理存储结构
-
C语言一篇精通链表的各种操作
目录 前言 一.链表的介绍 1.什么是链表 2.链表的分类 2.1.根据方向 2.2.头结点 2.3.循环/非循环 二.链表的实现 1.结构体 2.开辟结点 3.打印 4.尾插 5.头插 6.测试 7.头删/尾删 8.查找 9.在pos的前面插入x 10.删除pos位置的值 三.主函数Test 结束语 前言 关于线性表的一些相关介绍,大家可以看看我们之前写的点我-链表 点我-顺序表,里面有一些相关的知识介绍,都是比较基础的,一些比较常见的操作里面也有具体的介绍与实现到,然后呢,今天我们学习的是链
-
一文弄懂C语言如何实现单链表
目录 一.单链表与顺序表的区别: 一.顺序表: 二.链表 二.关于链表中的一些函数接口的作用及实现 1.头文件里的结构体和函数声明等等 2.创建接口空间 3.尾插尾删 4.头插头删 5.单链表查找 6.中间插入(在pos后面进行插入) 7.中间删除(在pos后面进行删除) 8.单独打印链表和从头到尾打印链表 9.test.c 总结 一.单链表与顺序表的区别: 一.顺序表: 1.内存中地址连续 2.长度可以实时变化 3.不支持随机查找 4.适用于访问大量元素的,而少量需要增添/删除的元素的程序 5
-
C语言实现无头单向链表的示例代码
目录 一.易错的接口实现 1.1 新节点开辟函数 1.2 尾插 1.3 尾删 二.常见简单接口 2.1 打印链表 2.2 节点计数器 2.3 判断是否为空链表 2.4 通过值查找节点 2.5 头插 2.6 头删 2.7 在任意节点后插入节点 2.8 在任意节点后删除节点 2.9 销毁链表 三.头文件相关内容 3.1 引用的库函数 3.2 结构体声明 一.易错的接口实现 1.1 新节点开辟函数 由于创建一个新节点是频繁的操作,所以封装为一个接口最佳. 链表节点的属性有:(1)数值.(2)指向下一个
-
C语言数据结构之单向链表详解分析
链表的概念:链表是一种动态存储分布的数据结构,由若干个同一结构类型的结点依次串连而成. 链表分为单向链表和双向链表. 链表变量一般用指针head表示,用来存放链表首结点的地址. 每个结点由数据部分和下一个结点的地址部分组成,即每个结点都指向下一个结点.最后一个结点称为表尾,其下一个结点的地址部分的值为NULL(表示为空地址). 特别注意:链表中的各个结点在内存中是可以不连续存放的,具体存放位置由系统分配. 例如:int *ptr ; 因此不可以用ptr++的方式来寻找下一个结点. 使用链表的优点
-
C语言数据结构之复杂链表的拷贝
题目: 给你一个长度为 n 的链表,每个节点包含一个额外增加的随机指针 random ,该指针可以指向链表中的任何节点或空节点. 构造这个链表的 深拷贝. 深拷贝应该正好由 n 个 全新 节点组成,其中每个新节点的值都设为其对应的原节点的值.新节点的 next 指针和 random 指针也都应指向复制链表中的新节点,并使原链表和复制链表中的这些指针能够表示相同的链表状态.复制链表中的指针都不应指向原链表中的节点 . 例如,如果原链表中有 X 和 Y 两个节点,其中 X.random --> Y
-
C语言三分钟精通时间复杂度与空间复杂度
目录 一.时间复杂度 1)O(n)的含义 2)复杂表达式的简化 3)O(n)不一定优于O(n^2) 4)递归的时间复杂度 二.空间复杂度 1)O(1)空间复杂度 2)O(n)空间复杂度 3)O(mn)空间 复杂度 4)递归算法空间算法复杂度分析 一.时间复杂度 1)O(n)的含义 程序消耗的时间用算法的操作单元数来表示 假设数据的规模为n,则用f(n)表示操作单元数的大小,而f(n)常被简化 O表示的是一般的情况,而不是上界或下界.并且它是在数据量级非常大的
-
C语言实现无头单链表详解
目录 链表的结构体描述(节点) 再定义一个结构体(链表) 断言处理 & 判空处理 创建链表 创建节点 头插法 打印链表 尾插法 指定位置插入 头删法 尾删法 指定位置删除 查找链表 删除所有指定相同的元素 总结 再封装的方式,用 c++ 的思想做无头链表 链表的结构体描述(节点) #include <stdio.h> #include <stdlib.h> #include <assert.h> typedef int DataType; //节点 typede
-
Go语言利用接口实现链表插入功能详解
目录 1. 接口定义 1.1 空接口 1.2 实现单一接口 1.3 接口多方法实现 2. 多态 2.1 为不同数据类型的实体提供统一的接口 2.2 多接口的实现 3. 系统接口调用 4. 接口嵌套 5. 类型断言 5.1 断言判断 5.2 多类型判断 6. 使用接口实现链表插入 1. 接口定义 Interface 类型可以定义一组方法,不需要实现,并且不能包含任何的变量,称之为接口 接口不需要显示的实现,只需要一个变量,含有接口类型中的所有方法,那么这个变量就实现了这个接口,如果一个变量含有多个
-
C语言数据结构之单链表的实现
目录 一.为什么使用链表 二.链表的概念 三.链表的实现 3.1 创建链表前须知 3.2 定义结构体 3.3 申请一个节点 3.4 链表的头插 3.5 链表的尾插 3.6 链表的尾删 3.7 链表的头删 3.8 寻找某节点 3.9 在指定节点前插入节点 3.10 删除指定节点前的节点 3.11 链表的销毁 一.为什么使用链表 在学习链表以前,我们存储数据用的方式就是数组.使用数组的好处就是便于查找数据,但缺点也很明显. 使用前需声明数组的长度,一旦声明长度就不能更改 插入和删除操作需要移动大量的
-
详解C语言内核中的链表与结构体
Windows内核中是无法使用vector容器等数据结构的,当我们需要保存一个结构体数组时,就需要使用内核中提供的专用链表结构LIST_ENTRY通过一些列链表操作函数对结构体进行装入弹出等操作,如下代码是本人总结的内核中使用链表存储多个结构体的通用案例. 首先实现一个枚举用户进程功能,将枚举到的进程存储到链表结构体内. #include <ntifs.h> #include <windef.h> extern PVOID PsGetProcessPeb(_In_ PEPROCES