Java请求流量合并和拆分提高系统的并发量示例
目录
- 序言
- 理论基础
- 应用实践
- (一)编码与使用
- 实现细节
- 1、ConcurrentLinkedQueue
- 2、CompletableFuture
- 其它应用场景
- 1、服务间接口调用
- 小结
序言
在并发场景中,当热点缓存Key失效时,流量瞬间打到数据库中,此所谓缓存击穿现象;当大范围的缓存Key失效时,流量也会打到数据库中,此所谓缓存雪崩现象。
当使用分布式行锁时,能够有效解决缓存击穿问题;当使用分布式表锁时,能够解决缓存雪崩问题。实际操作中,分布式表锁不在考虑范围,理由是降低并发量。
本文将从另一个角度出发,将请求流量合并和拆分,以提高系统的并发量。
理论基础
流量的合并与拆分原理是将多条请求合并成一条请求,执行后再将结果拆分。在数据库与缓存架构中,缓存Key失效的瞬间,大量重复请求打到数据库中。实际上除了第一条请求为有效请求,随后的请求为无效请求,浪费数据库连接资源。
流量的合并与拆分实践是额外唤醒一个线程,每隔固定时间(比如200毫秒)发送合并后的请求,执行完成后将查询结果进行拆分,分发到原始请求中,原始请求响应用户请求。
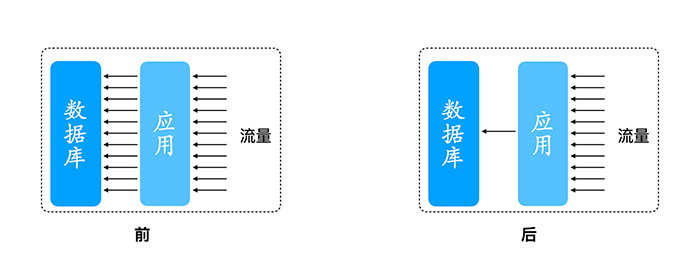
从应用到数据库之间连接资源需求显著下降,从而提高数据库连接资源利用率。
应用实践
(一)编码与使用
基于MybatisPlus提供一个内置封装的服务类QueueServiceImpl,透明的实现查询详情流量的合并与拆分,使用者可屏蔽内部实现。
<dependency>
<groupId>xin.altitude.cms</groupId>
<artifactId>ucode-cms-common</artifactId>
<version>1.4.4</version>
</dependency>
对于一定时间区间内的所有请求,合并成一条请求处理。
@Override
public BuOrder getOrderById(Long orderId) {
return getById(orderId);
}
举例说明,如果特定时间区间内汇集了相同的主键请求,那么合并后的请求查询一次数据库便能够响应所有的请求。
子类重写父类方法,可修改合并与拆分的行为。
@Override
protected RequstConfig createRequstConfig() {
RequstConfig config = new RequstConfig();
/* 单次最大合并请求数量 */
config.setMaxRequestSize(100);
/* 核心线程池大小 */
config.setCorePoolSize(1);
/* 请求间隔(毫秒) */
config.setRequestInterval(200);
return config;
}
实现细节
1、ConcurrentLinkedQueue
使用ConcurrentLinkedQueue并发安全队列用于缓冲和接收请求,定时任务以固定频率从队列中消费数据,将多条请求条件合并后汇总查询。
2、CompletableFuture
CompletableFuture类是合并与拆分的关键类,原始请求将查询条件封装成CompletableFuture对象,提交到队列中后陷入阻塞,定时任务分批次组装查询条件,得到结果后将结果拆分并存入CompletableFuture对象中,原始请求线程被唤醒,继续响应用户请求。
其它应用场景
应用于数据库间流量的合并请求与拆分,首先提高数据库连接资源(稀缺资源)利用率,其次提高网络间数据传输效率。100条数据收发100次与100条数据收发一次的效率差别。
1、服务间接口调用
服务间API接口调用同样适用于流量的合并与拆分:比如向订单服务发送Http API请求,同一时刻有100个用户发起查询请求,使用流量合并与拆分的思想可将多个订单查询请求转换成批查询请求,得到结果后分发到不同的请求线程,响应用户请求。
小结
在本文中,选用的队列是本地并发安全的队列,在分布式系统中,本地队列是否合适?此处选用本地队列基于两点考虑:一是无严格的分布式的需求;二是CompletableFuture类不支持序列化。考虑使用Redis做分布式队列的想法无法实现,你用本地队列,尽管会有少量查询条件数据冗余(不影响结果),回避了分布式队列的网络IO延迟,反而有更优的查询效率。
本方案仅在高并发场景受益,属于针对并发场景进行架构的优化,普通项目使用常规操作即可。
以上就是Java请求流量合并和拆分提高系统的并发量示例的详细内容,更多关于Java流量合并拆分提高系统的并发量的资料请关注我们其它相关文章!
相关推荐
-
详解java解决分布式环境中高并发环境下数据插入重复问题
java 解决分布式环境中 高并发环境下数据插入重复问题 前言 原因:服务器同时接受到的重复请求 现象:数据重复插入 / 修改操作 解决方案 : 分布式锁 对请求报文生成 摘要信息 + redis 实现分布式锁 工具类 分布式锁的应用 package com.nursling.web.filter.context; import com.nursling.nosql.redis.RedisUtil; import com.nursling.sign.SignType; import com.nu
-
Java Semaphore实现高并发场景下的流量控制
目录 前言 Semaphore介绍 代码演示 补充 独占锁与共享锁 公平锁与非公平锁 可重入锁 前言 在java开发的工作中是否会出现这样的场景,你需要实现一些异步运行的任务,该任务可能存在消耗大量内存的情况,所以需要对任务进行并发控制.如何优雅的实现并发控制呢?下面我会给大家介绍一个类--Semaphore,能很优雅的实现并发控制,继续往下看吧. Semaphore介绍 首先我们看一下Semaphore类的构造函数是如何实现的. public Semaphore(int permits, bo
-
浅谈Java高并发解决方案以及高负载优化方法
目录 1.HTML静态化 2.图片服务器分离 3.数据库集群和库表散列 4.缓存 5.镜像 6.负载均衡 1)硬件四层交换 2)软件四层交换 一.高并发高负载类网站关注点之数据库 需要注意的是: 二.高并发高负载网站的系统架构之HTML静态化 网站HTML静态化解决方案 : 三.高并发高负载类网站关注点之缓存.负载均衡.存储 负载均衡/加速 存储 四.高并发高负载网站的系统架构之图片服务器分离 利用Apache实现图片服务器的分离,缘由: 环境介绍: 步骤: 五.高并发高负载网站的系统架构之数据
-

Java使用代码模拟高并发操作的示例
在java中,使用了synchronized关键字和Lock锁实现了资源的并发访问控制,在同一时间只允许唯一了线程进入临界区访问资源(读锁除外),这样子控制的主要目的是为了解决多个线程并发同一资源造成的数据不一致的问题.在另外一种场景下,一个资源有多个副本可供同时使用,比如打印机房有多个打印机.厕所有多个坑可供同时使用,这种情况下,Java提供了另外的并发访问控制--资源的多副本的并发访问控制,今天使用的Semaphore即是其中的一种. Java通过代码模拟高并发可以以最快的方式发现我们系统中
-
java实用型-高并发下RestTemplate的正确使用说明
目录 前言 一.RestTemplate是什么? 二.如何使用 1.创建一个bean 2.使用步骤 三.高并发下的RestTemplate使用 1.设置预热功能 2.合理设置maxtotal数量 总结 前言 如果java项目里有调用第三方的http接口,我们可以使用RestTemplate去远程访问.也支持配置连接超时和响应超时,还可以配置各种长连接策略,也可以支持长连接预热,在高并发下,合理的配置使用能够有效提高第三方接口响应时间. 一.RestTemplate是什么? RestTemplat
-
Java请求流量合并和拆分提高系统的并发量示例
目录 序言 理论基础 应用实践 (一)编码与使用 实现细节 1.ConcurrentLinkedQueue 2.CompletableFuture 其它应用场景 1.服务间接口调用 小结 序言 在并发场景中,当热点缓存Key失效时,流量瞬间打到数据库中,此所谓缓存击穿现象:当大范围的缓存Key失效时,流量也会打到数据库中,此所谓缓存雪崩现象. 当使用分布式行锁时,能够有效解决缓存击穿问题:当使用分布式表锁时,能够解决缓存雪崩问题.实际操作中,分布式表锁不在考虑范围,理由是降低并发量. 本文将从另
-
java IO流将一个文件拆分为多个子文件代码示例
文件分割与合并是一个常见需求,比如:上传大文件时,可以先分割成小块,传到服务器后,再进行合并.很多高大上的分布式文件系统(比如:google的GFS.taobao的TFS)里,也是按block为单位,对文件进行分割或合并. 看下基本思路: 如果有一个大文件,指定分割大小后(比如:按1M切割) step 1: 先根据原始文件大小.分割大小,算出最终分割的小文件数N step 2: 在磁盘上创建这N个小文件 step 3: 开多个线程(线程数=分割文件数),每个线程里,利用RandomAccessF
-
如何实用Java实现合并、拆分PDF文档
前言 处理PDF文档时,我们可以通过合并的方式,来任意组几个不同的PDF文件或者通过拆分将一个文件分解成多个子文件,这样的好处是对文档的存储.管理很方便.下面将通过Java程序代码介绍具体的PDF合并.拆分的方法. 工具:Free Spire.PDF for Java 2.0.0 (免费版) 注:2.0.0版本的比之前的1.1.0版本在功能上做了很大提升,支持所有收费版的功能,只是在文档页数上有一定限制,要求不超过10页,但是对于常规的不是很大的文件,这个类库就非常实用. jar文件导入: 方法
-
C# 如何合并和拆分PDF文件
一.合并和拆分PDF文件的方式 PDF文件使用了工业标准的压缩算法,易于传输与储存.它还是页独立的,一个PDF文件包含一个或多个"页",可以单独处理各页,特别适合多处理器系统的工作.PDF文件结构主要可以分为四个部分:首部.文件体.交叉引用表.尾部.PDF操作类库非常多,如下图所示,常用的类库有:Spire.Pdf.iTextSharp. 二.使用 Spire.Pdf 合并和拆分PDF文件 使用 Nuget 添加Spire.Pdf 类库,然后添加如下代码: /// <summar
-
Java 实战项目之小说在线阅读系统的实现流程
一.项目简述 功能包括(管理员和游客角色): 1:用户及主要操作功能 游客可以浏览网站的主页,但是需要注册为会员后部分小 说才能对网络小说进免费行阅读或阅读.用户可以收藏书 架,留言评论,上次阅读,阅读历史,章节选择等等功 能. 2:管理模块 网络小说管理模块包括不同网络小说类别的添加,删除以 及网络小说的上传,删除管理.可以包括武侠小书,都市 言情,穿越小书等各个类等等功能. 二.项目运行 环境配置: Jdk1.8 + Tomcat8.5 + mysql + Eclispe (IntelliJ
-
Java毕业设计实战之在线网盘系统的实现
一.项目简述 功能:用户的邮箱注册.验证码验证以及用户登录. 不需要注册账号,也可以上传满足条件的临时文件,但是只4小时内有效. 文件的管理,上传.下载.重命名.删除.查看统计数据.分类管理等. 文件夹的管理,创建.删除.重命名. 文件的分享,支持通过链接和二维码的分享方式等等,以及管理员对用户的管理等等. 二.项目运行 环境配置: Jdk1.8 + Tomcat8.5 + mysql + Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持) 项目技术:
-
Java实战之实现在线小说阅读系统
目录 环境配置 项目技术 效果图 读者用户控制器 图书管理控制层 图书订单管理控制层 角色管理控制层 历史控制层 环境配置 Jdk1.8 + Tomcat8.5 + mysql + Eclispe(IntelliJ IDEA,Eclispe,MyEclispe,Sts都支持) 项目技术 Layui+Springboot+ SpringMVC + HTML + FTP+ JavaScript + JQuery + Ajax + maven等等. 效果图 读者用户控制器 @Controller pu
-
Java多线程编程小实例模拟停车场系统
下面分享的是一个Java多线程模拟停车场系统的小实例(Java的应用还是很广泛的,哈哈),具体代码如下: Park类 public class Park { boolean []park=new boolean[3]; public boolean equals() { return true; } } Car: public class Car { private String number; private int position=0; public Car(String number)
-
php数组合并与拆分实例分析
本文实例讲述了php数组合并与拆分的方法.分享给大家供大家参考.具体如下: <?php $array1 = array("A","B","C","D"); $array2 = array("1","2","3","4"); $array3 = array("!","@","#",&q
-
PHPExcel合并与拆分单元格的方法
本文实例讲述了PHPExcel合并与拆分单元格的方法.分享给大家供大家参考,具体如下: $objPHPExcel; $filepath="c:\temp.xlsx"; try { $objReader = PHPExcel_IOFactory::createReader('Excel2007'); $objPHPExcel = $objReader->load($filepath); } catch (Exception $e) { die(); } $column_index