详解tensorflow之过拟合问题实战
过拟合问题实战
1.构建数据集
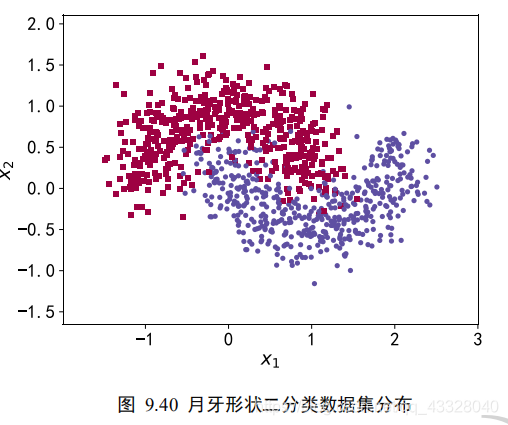
我们使用的数据集样本特性向量长度为 2,标签为 0 或 1,分别代表了 2 种类别。借助于 scikit-learn 库中提供的 make_moons 工具我们可以生成任意多数据的训练集。
import matplotlib.pyplot as plt # 导入数据集生成工具 import numpy as np import seaborn as sns from sklearn.datasets import make_moons from sklearn.model_selection import train_test_split from tensorflow.keras import layers, Sequential, regularizers from mpl_toolkits.mplot3d import Axes3D
为了演示过拟合现象,我们只采样了 1000 个样本数据,同时添加标准差为 0.25 的高斯噪声数据:
def load_dataset(): # 采样点数 N_SAMPLES = 1000 # 测试数量比率 TEST_SIZE = None # 从 moon 分布中随机采样 1000 个点,并切分为训练集-测试集 X, y = make_moons(n_samples=N_SAMPLES, noise=0.25, random_state=100) X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=TEST_SIZE, random_state=42) return X, y, X_train, X_test, y_train, y_test
make_plot 函数可以方便地根据样本的坐标 X 和样本的标签 y 绘制出数据的分布图:
def make_plot(X, y, plot_name, file_name, XX=None, YY=None, preds=None, dark=False, output_dir=OUTPUT_DIR):
# 绘制数据集的分布, X 为 2D 坐标, y 为数据点的标签
if dark:
plt.style.use('dark_background')
else:
sns.set_style("whitegrid")
axes = plt.gca()
axes.set_xlim([-2, 3])
axes.set_ylim([-1.5, 2])
axes.set(xlabel="$x_1$", ylabel="$x_2$")
plt.title(plot_name, fontsize=20, fontproperties='SimHei')
plt.subplots_adjust(left=0.20)
plt.subplots_adjust(right=0.80)
if XX is not None and YY is not None and preds is not None:
plt.contourf(XX, YY, preds.reshape(XX.shape), 25, alpha=0.08, cmap=plt.cm.Spectral)
plt.contour(XX, YY, preds.reshape(XX.shape), levels=[.5], cmap="Greys", vmin=0, vmax=.6)
# 绘制散点图,根据标签区分颜色m=markers
markers = ['o' if i == 1 else 's' for i in y.ravel()]
mscatter(X[:, 0], X[:, 1], c=y.ravel(), s=20, cmap=plt.cm.Spectral, edgecolors='none', m=markers, ax=axes)
# 保存矢量图
plt.savefig(output_dir + '/' + file_name)
plt.close()
def mscatter(x, y, ax=None, m=None, **kw):
import matplotlib.markers as mmarkers
if not ax: ax = plt.gca()
sc = ax.scatter(x, y, **kw)
if (m is not None) and (len(m) == len(x)):
paths = []
for marker in m:
if isinstance(marker, mmarkers.MarkerStyle):
marker_obj = marker
else:
marker_obj = mmarkers.MarkerStyle(marker)
path = marker_obj.get_path().transformed(
marker_obj.get_transform())
paths.append(path)
sc.set_paths(paths)
return sc
X, y, X_train, X_test, y_train, y_test = load_dataset() make_plot(X,y,"haha",'月牙形状二分类数据集分布.svg')
2.网络层数的影响
为了探讨不同的网络深度下的过拟合程度,我们共进行了 5 次训练实验。在𝑛 ∈ [0,4]时,构建网络层数为n + 2层的全连接层网络,并通过 Adam 优化器训练 500 个 Epoch
def network_layers_influence(X_train, y_train):
# 构建 5 种不同层数的网络
for n in range(5):
# 创建容器
model = Sequential()
# 创建第一层
model.add(layers.Dense(8, input_dim=2, activation='relu'))
# 添加 n 层,共 n+2 层
for _ in range(n):
model.add(layers.Dense(32, activation='relu'))
# 创建最末层
model.add(layers.Dense(1, activation='sigmoid'))
# 模型装配与训练
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
model.fit(X_train, y_train, epochs=N_EPOCHS, verbose=1)
# 绘制不同层数的网络决策边界曲线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
print(preds)
title = "网络层数:{0}".format(2 + n)
file = "网络容量_%i.png" % (2 + n)
make_plot(X_train, y_train, title, file, XX, YY, preds, output_dir=OUTPUT_DIR + '/network_layers')





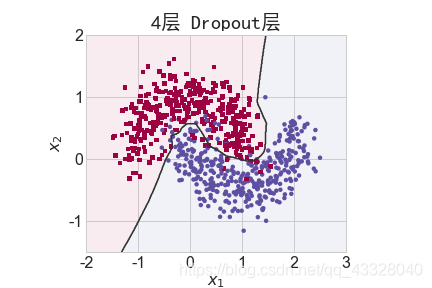
3.Dropout的影响
为了探讨 Dropout 层对网络训练的影响,我们共进行了 5 次实验,每次实验使用 7 层的全连接层网络进行训练,但是在全连接层中间隔插入 0~4 个 Dropout 层并通过 Adam优化器训练 500 个 Epoch
def dropout_influence(X_train, y_train):
# 构建 5 种不同数量 Dropout 层的网络
for n in range(5):
# 创建容器
model = Sequential()
# 创建第一层
model.add(layers.Dense(8, input_dim=2, activation='relu'))
counter = 0
# 网络层数固定为 5
for _ in range(5):
model.add(layers.Dense(64, activation='relu'))
# 添加 n 个 Dropout 层
if counter < n:
counter += 1
model.add(layers.Dropout(rate=0.5))
# 输出层
model.add(layers.Dense(1, activation='sigmoid'))
# 模型装配
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练
model.fit(X_train, y_train, epochs=N_EPOCHS, verbose=1)
# 绘制不同 Dropout 层数的决策边界曲线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "无Dropout层" if n == 0 else "{0}层 Dropout层".format(n)
file = "Dropout_%i.png" % n
make_plot(X_train, y_train, title, file, XX, YY, preds, output_dir=OUTPUT_DIR + '/dropout')




4.正则化的影响
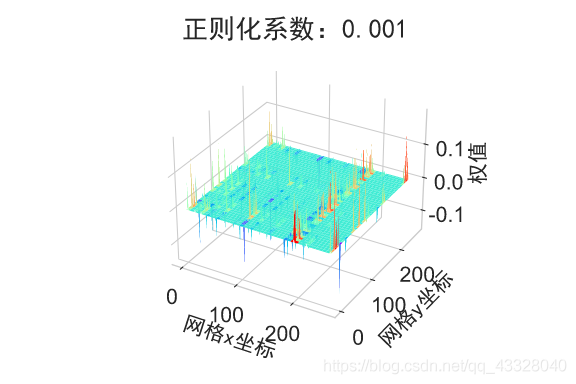
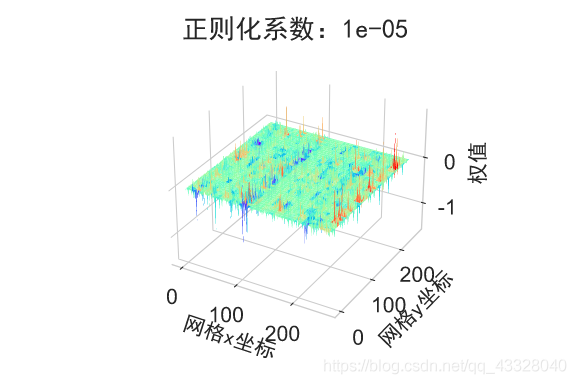
为了探讨正则化系数𝜆对网络模型训练的影响,我们采用 L2 正则化方式,构建了 5 层的神经网络,其中第 2,3,4 层神经网络层的权值张量 W 均添加 L2 正则化约束项:
def build_model_with_regularization(_lambda): # 创建带正则化项的神经网络 model = Sequential() model.add(layers.Dense(8, input_dim=2, activation='relu')) # 不带正则化项 # 2-4层均是带 L2 正则化项 model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda))) model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda))) model.add(layers.Dense(256, activation='relu', kernel_regularizer=regularizers.l2(_lambda))) # 输出层 model.add(layers.Dense(1, activation='sigmoid')) model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy']) # 模型装配 return model
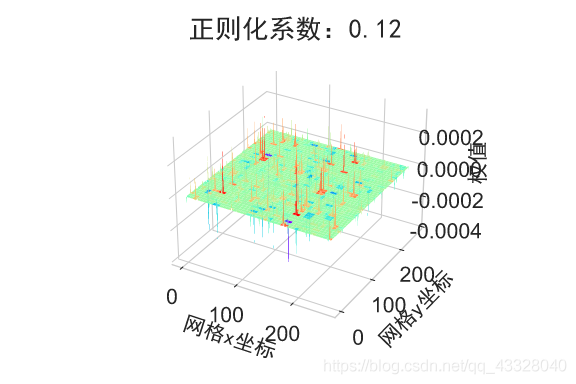
下面我们首先来实现一个权重可视化的函数
def plot_weights_matrix(model, layer_index, plot_name, file_name, output_dir=OUTPUT_DIR):
# 绘制权值范围函数
# 提取指定层的权值矩阵
weights = model.layers[layer_index].get_weights()[0]
shape = weights.shape
# 生成和权值矩阵等大小的网格坐标
X = np.array(range(shape[1]))
Y = np.array(range(shape[0]))
X, Y = np.meshgrid(X, Y)
# 绘制3D图
fig = plt.figure()
ax = fig.gca(projection='3d')
ax.xaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.yaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
ax.zaxis.set_pane_color((1.0, 1.0, 1.0, 0.0))
plt.title(plot_name, fontsize=20, fontproperties='SimHei')
# 绘制权值矩阵范围
ax.plot_surface(X, Y, weights, cmap=plt.get_cmap('rainbow'), linewidth=0)
# 设置坐标轴名
ax.set_xlabel('网格x坐标', fontsize=16, rotation=0, fontproperties='SimHei')
ax.set_ylabel('网格y坐标', fontsize=16, rotation=0, fontproperties='SimHei')
ax.set_zlabel('权值', fontsize=16, rotation=90, fontproperties='SimHei')
# 保存矩阵范围图
plt.savefig(output_dir + "/" + file_name + ".svg")
plt.close(fig)
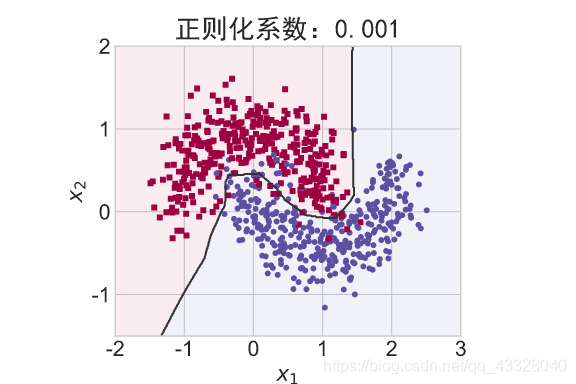
在保持网络结构不变的条件下,我们通过调节正则化系数 𝜆 = 0.00001,0.001,0.1,0.12,0.13 来测试网络的训练效果,并绘制出学习模型在训练集上的决策边界曲线
def regularizers_influence(X_train, y_train):
for _lambda in [1e-5, 1e-3, 1e-1, 0.12, 0.13]: # 设置不同的正则化系数
# 创建带正则化项的模型
model = build_model_with_regularization(_lambda)
# 模型训练
model.fit(X_train, y_train, epochs=N_EPOCHS, verbose=1)
# 绘制权值范围
layer_index = 2
plot_title = "正则化系数:{}".format(_lambda)
file_name = "正则化网络权值_" + str(_lambda)
# 绘制网络权值范围图
plot_weights_matrix(model, layer_index, plot_title, file_name, output_dir=OUTPUT_DIR + '/regularizers')
# 绘制不同正则化系数的决策边界线
# 可视化的 x 坐标范围为[-2, 3]
xx = np.arange(-2, 3, 0.01)
# 可视化的 y 坐标范围为[-1.5, 2]
yy = np.arange(-1.5, 2, 0.01)
# 生成 x-y 平面采样网格点,方便可视化
XX, YY = np.meshgrid(xx, yy)
preds = model.predict_classes(np.c_[XX.ravel(), YY.ravel()])
title = "正则化系数:{}".format(_lambda)
file = "正则化_%g.svg" % _lambda
make_plot(X_train, y_train, title, file, XX, YY, preds, output_dir=OUTPUT_DIR + '/regularizers')
regularizers_influence(X_train, y_train)






到此这篇关于详解tensorflow之过拟合问题实战的文章就介绍到这了,更多相关tensorflow 过拟合内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
tensorflow使用L2 regularization正则化修正overfitting过拟合方式
L2正则化原理: 过拟合的原理:在loss下降,进行拟合的过程中(斜线),不同的batch数据样本造成红色曲线的波动大,图中低点也就是过拟合,得到的红线点低于真实的黑线,也就是泛化更差. 可见,要想减小过拟合,减小这个波动,减少w的数值就能办到. L2正则化训练的原理:在Loss中加入(乘以系数λ的)参数w的平方和,这样训练过程中就会抑制w的值,w的(绝对)值小,模型复杂度低,曲线平滑,过拟合程度低(奥卡姆剃刀),参考公式如下图: (正则化是不阻碍你去拟合曲线的,并不是所有参数都会被无脑抑制,实
-
详解tensorflow之过拟合问题实战
过拟合问题实战 1.构建数据集 我们使用的数据集样本特性向量长度为 2,标签为 0 或 1,分别代表了 2 种类别.借助于 scikit-learn 库中提供的 make_moons 工具我们可以生成任意多数据的训练集. import matplotlib.pyplot as plt # 导入数据集生成工具 import numpy as np import seaborn as sns from sklearn.datasets import make_moons from sklearn.m
-

用十张图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下TensorFlow的数据读取机制,文章的最后还会给出实战代码以供参考. TensorFlow读取机制图解 首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示: 假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg--我们只需要把
-
详解TensorFlow在windows上安装与简单示例
本文介绍了详解TensorFlow在windows上安装与简单示例,分享给大家,具体如下: 安装说明 平台:目前可在Ubuntu.Mac OS.Windows上安装 版本:提供gpu版本.cpu版本 安装方式:pip方式.Anaconda方式 Tips: 在Windows上目前支持python3.5.x gpu版本需要cuda8,cudnn5.1 安装进度 2017/3/4进度: Anaconda 4.3(对应python3.6)正在安装,又删除了,一无所有了 2017/3/5进度: Anaco
-
详解Tensorflow不同版本要求与CUDA及CUDNN版本对应关系
参考官网地址: Windows端:https://tensorflow.google.cn/install/source_windows CPU Version Python version Compiler Build tools tensorflow-1.11.0 3.5-3.6 MSVC 2015 update 3 Cmake v3.6.3 tensorflow-1.10.0 3.5-3.6 MSVC 2015 update 3 Cmake v3.6.3 tensorflow-1.9.0
-
详解高性能缓存Caffeine原理及实战
目录 一.简介 二.Caffeine 原理 2.1.淘汰算法 2.1.1.常见算法 2.1.2.W-TinyLFU 算法 2.2.高性能读写 2.2.1.读缓冲 2.2.2.写缓冲 三.Caffeine 实战 3.1.配置参数 3.2.项目实战 四.总结 一.简介 下面是Caffeine 官方测试报告. 由上面三幅图可见:不管在并发读.并发写还是并发读写的场景下,Caffeine 的性能都大幅领先于其他本地开源缓存组件. 本文先介绍 Caffeine 实现原理,再讲解如何在项目中使用 Caffe
-
详解TensorFlow训练网络两种方式
TensorFlow训练网络有两种方式,一种是基于tensor(array),另外一种是迭代器 两种方式区别是: 第一种是要加载全部数据形成一个tensor,然后调用model.fit()然后指定参数batch_size进行将所有数据进行分批训练 第二种是自己先将数据分批形成一个迭代器,然后遍历这个迭代器,分别训练每个批次的数据 方式一:通过迭代器 IMAGE_SIZE = 1000 # step1:加载数据集 (train_images, train_labels), (val_images,
-
详解Pytorch 使用Pytorch拟合多项式(多项式回归)
使用Pytorch来编写神经网络具有很多优势,比起Tensorflow,我认为Pytorch更加简单,结构更加清晰. 希望通过实战几个Pytorch的例子,让大家熟悉Pytorch的使用方法,包括数据集创建,各种网络层结构的定义,以及前向传播与权重更新方式. 比如这里给出 很显然,这里我们只需要假定 这里我们只需要设置一个合适尺寸的全连接网络,根据不断迭代,求出最接近的参数即可. 但是这里需要思考一个问题,使用全连接网络结构是毫无疑问的,但是我们的输入与输出格式是什么样的呢? 只将一个x作为输入
-
详解Tensorflow数据读取有三种方式(next_batch)
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
详解tensorflow载入数据的三种方式
Tensorflow数据读取有三种方式: Preloaded data: 预加载数据 Feeding: Python产生数据,再把数据喂给后端. Reading from file: 从文件中直接读取 这三种有读取方式有什么区别呢? 我们首先要知道TensorFlow(TF)是怎么样工作的. TF的核心是用C++写的,这样的好处是运行快,缺点是调用不灵活.而Python恰好相反,所以结合两种语言的优势.涉及计算的核心算子和运行框架是用C++写的,并提供API给Python.Python调用这些A
-
详解Shell编程之if语句实战(小结)
对于if语句,其实很多人都肯定的听说过,那么if语句到底是什么,简单的说,就类似于汉语里面的如果----那么,if语句是linux运维人员在实际环境中使用的最频繁也是最重要的语句!!! 一.if条件语句 1.单分支语句结构 第一种语法如下: if <条件表达式> then 指令 fi 第二种语法 if <条件表达式>; then 指令 fi 在以上这两种方式中我还是喜欢用第一种,这个是看个人习惯的.在上面的两个语法中<条件表达式>可以是 test [] [[]] (()