PyTorch一小时掌握之神经网络分类篇
目录
- 概述
- 导包
- 设置超参数
- 读取数据
- 可视化展示
- 建立模型
- 训练模型
- 完整代码
概述
对于 MNIST 手写数据集的具体介绍, 我们在 TensorFlow 中已经详细描述过, 在这里就不多赘述. 有兴趣的同学可以去看看之前的文章: https://www.jb51.net/article/222183.htm
在上一节的内容里, 我们用 PyTorch 实现了回归任务, 在这一节里, 我们将使用 PyTorch 来解决分类任务.
导包
import torchvision import torch import torch.nn as nn import torch.nn.functional as F import torch.optim as optim import matplotlib.pyplot as plt
设置超参数
# 设置超参数 n_epochs = 3 batch_size_train = 64 batch_size_test = 1000 learning_rate = 0.01 momentum = 0.5 log_interval = 10 random_seed = 1 torch.manual_seed(random_seed)
读取数据
# 数据读取
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
# 调试输出
print(example_targets)
print(example_data.shape)
输出结果:
tensor([7, 6, 7, 5, 6, 7, 8, 1, 1, 2, 4, 1, 0, 8, 4, 4, 4, 9, 8, 1, 3, 3, 8, 6,
2, 7, 5, 1, 6, 5, 6, 2, 9, 2, 8, 4, 9, 4, 8, 6, 7, 7, 9, 8, 4, 9, 5, 3,
1, 0, 9, 1, 7, 3, 7, 0, 9, 2, 5, 1, 8, 9, 3, 7, 8, 4, 1, 9, 0, 3, 1, 2,
3, 6, 2, 9, 9, 0, 3, 8, 3, 0, 8, 8, 5, 3, 8, 2, 8, 5, 5, 7, 1, 5, 5, 1,
0, 9, 7, 5, 2, 0, 7, 6, 1, 2, 2, 7, 5, 4, 7, 3, 0, 6, 7, 5, 1, 7, 6, 7,
2, 1, 9, 1, 9, 2, 7, 6, 8, 8, 8, 4, 6, 0, 0, 2, 3, 0, 1, 7, 8, 7, 4, 1,
3, 8, 3, 5, 5, 9, 6, 0, 5, 3, 3, 9, 4, 0, 1, 9, 9, 1, 5, 6, 2, 0, 4, 7,
3, 5, 8, 8, 2, 5, 9, 5, 0, 7, 8, 9, 3, 8, 5, 3, 2, 4, 4, 6, 3, 0, 8, 2,
7, 0, 5, 2, 0, 6, 2, 6, 3, 6, 6, 7, 9, 3, 4, 1, 6, 2, 8, 4, 7, 7, 2, 7,
4, 2, 4, 9, 7, 7, 5, 9, 1, 3, 0, 4, 4, 8, 9, 6, 6, 5, 3, 3, 2, 3, 9, 1,
1, 4, 4, 8, 1, 5, 1, 8, 8, 0, 7, 5, 8, 4, 0, 0, 0, 6, 3, 0, 9, 0, 6, 6,
9, 8, 1, 2, 3, 7, 6, 1, 5, 9, 3, 9, 3, 2, 5, 9, 9, 5, 4, 9, 3, 9, 6, 0,
3, 3, 8, 3, 1, 4, 1, 4, 7, 3, 1, 6, 8, 4, 7, 7, 3, 3, 6, 1, 3, 2, 3, 5,
9, 9, 9, 2, 9, 0, 2, 7, 0, 7, 5, 0, 2, 6, 7, 3, 7, 1, 4, 6, 4, 0, 0, 3,
2, 1, 9, 3, 5, 5, 1, 6, 4, 7, 4, 6, 4, 4, 9, 7, 4, 1, 5, 4, 8, 7, 5, 9,
2, 9, 4, 0, 8, 7, 3, 4, 2, 7, 9, 4, 4, 0, 1, 4, 1, 2, 5, 2, 8, 5, 3, 9,
1, 3, 5, 1, 9, 5, 3, 6, 8, 1, 7, 9, 9, 9, 9, 9, 2, 3, 5, 1, 4, 2, 3, 1,
1, 3, 8, 2, 8, 1, 9, 2, 9, 0, 7, 3, 5, 8, 3, 7, 8, 5, 6, 4, 1, 9, 7, 1,
7, 1, 1, 8, 6, 7, 5, 6, 7, 4, 9, 5, 8, 6, 5, 6, 8, 4, 1, 0, 9, 1, 4, 3,
5, 1, 8, 7, 5, 4, 6, 6, 0, 2, 4, 2, 9, 5, 9, 8, 1, 4, 8, 1, 1, 6, 7, 5,
9, 1, 1, 7, 8, 7, 5, 5, 2, 6, 5, 8, 1, 0, 7, 2, 2, 4, 3, 9, 7, 3, 5, 7,
6, 9, 5, 9, 6, 5, 7, 2, 3, 7, 2, 9, 7, 4, 8, 4, 9, 3, 8, 7, 5, 0, 0, 3,
4, 3, 3, 6, 0, 1, 7, 7, 4, 6, 3, 0, 8, 0, 9, 8, 2, 4, 2, 9, 4, 9, 9, 9,
7, 7, 6, 8, 2, 4, 9, 3, 0, 4, 4, 1, 5, 7, 7, 6, 9, 7, 0, 2, 4, 2, 1, 4,
7, 4, 5, 1, 4, 7, 3, 1, 7, 6, 9, 0, 0, 7, 3, 6, 3, 3, 6, 5, 8, 1, 7, 1,
6, 1, 2, 3, 1, 6, 8, 8, 7, 4, 3, 7, 7, 1, 8, 9, 2, 6, 6, 6, 2, 8, 8, 1,
6, 0, 3, 0, 5, 1, 3, 2, 4, 1, 5, 5, 7, 3, 5, 6, 2, 1, 8, 0, 2, 0, 8, 4,
4, 5, 0, 0, 1, 5, 0, 7, 4, 0, 9, 2, 5, 7, 4, 0, 3, 7, 0, 3, 5, 1, 0, 6,
4, 7, 6, 4, 7, 0, 0, 5, 8, 2, 0, 6, 2, 4, 2, 3, 2, 7, 7, 6, 9, 8, 5, 9,
7, 1, 3, 4, 3, 1, 8, 0, 3, 0, 7, 4, 9, 0, 8, 1, 5, 7, 3, 2, 2, 0, 7, 3,
1, 8, 8, 2, 2, 6, 2, 7, 6, 6, 9, 4, 9, 3, 7, 0, 4, 6, 1, 9, 7, 4, 4, 5,
8, 2, 3, 2, 4, 9, 1, 9, 6, 7, 1, 2, 1, 1, 2, 6, 9, 7, 1, 0, 1, 4, 2, 7,
7, 8, 3, 2, 8, 2, 7, 6, 1, 1, 9, 1, 0, 9, 1, 3, 9, 3, 7, 6, 5, 6, 2, 0,
0, 3, 9, 4, 7, 3, 2, 9, 0, 9, 5, 2, 2, 4, 1, 6, 3, 4, 0, 1, 6, 9, 1, 7,
0, 8, 0, 0, 9, 8, 5, 9, 4, 4, 7, 1, 9, 0, 0, 2, 4, 3, 5, 0, 4, 0, 1, 0,
5, 8, 1, 8, 3, 3, 2, 1, 2, 6, 8, 2, 5, 3, 7, 9, 3, 6, 2, 2, 6, 2, 7, 7,
6, 1, 8, 0, 3, 5, 7, 5, 0, 8, 6, 7, 2, 4, 1, 4, 3, 7, 7, 2, 9, 3, 5, 5,
9, 4, 8, 7, 6, 7, 4, 9, 2, 7, 7, 1, 0, 7, 2, 8, 0, 3, 5, 4, 5, 1, 5, 7,
6, 7, 3, 5, 3, 4, 5, 3, 4, 3, 2, 3, 1, 7, 4, 4, 8, 5, 5, 3, 2, 2, 9, 5,
8, 2, 0, 6, 0, 7, 9, 9, 6, 1, 6, 6, 2, 3, 7, 4, 7, 5, 2, 9, 4, 2, 9, 0,
8, 1, 7, 5, 5, 7, 0, 5, 2, 9, 5, 2, 3, 4, 6, 0, 0, 2, 9, 2, 0, 5, 4, 8,
9, 0, 9, 1, 3, 4, 1, 8, 0, 0, 4, 0, 8, 5, 9, 8])
torch.Size([1000, 1, 28, 28])
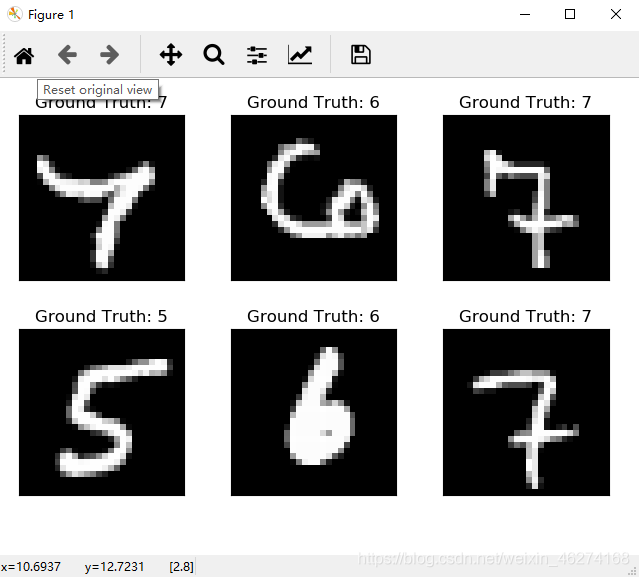
可视化展示
# 画图 (前6个)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
输出结果:
建立模型
# 创建model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
训练模型
# 训练
train_losses = []
train_counter = []
test_losses = []
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
def train(epoch):
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
def test():
network.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
输出结果:
Train Epoch: 1 [0/60000 (0%)] Loss: 2.297471
Train Epoch: 1 [6400/60000 (11%)] Loss: 1.934886
Train Epoch: 1 [12800/60000 (21%)] Loss: 1.242982
Train Epoch: 1 [19200/60000 (32%)] Loss: 0.979296
Train Epoch: 1 [25600/60000 (43%)] Loss: 1.277279
Train Epoch: 1 [32000/60000 (53%)] Loss: 0.721533
Train Epoch: 1 [38400/60000 (64%)] Loss: 0.759595
Train Epoch: 1 [44800/60000 (75%)] Loss: 0.469635
Train Epoch: 1 [51200/60000 (85%)] Loss: 0.422614
Train Epoch: 1 [57600/60000 (96%)] Loss: 0.417603Test set: Avg. loss: 0.1988, Accuracy: 9431/10000 (94%)
Train Epoch: 2 [0/60000 (0%)] Loss: 0.277207
Train Epoch: 2 [6400/60000 (11%)] Loss: 0.328862
Train Epoch: 2 [12800/60000 (21%)] Loss: 0.396312
Train Epoch: 2 [19200/60000 (32%)] Loss: 0.301772
Train Epoch: 2 [25600/60000 (43%)] Loss: 0.253600
Train Epoch: 2 [32000/60000 (53%)] Loss: 0.217821
Train Epoch: 2 [38400/60000 (64%)] Loss: 0.395815
Train Epoch: 2 [44800/60000 (75%)] Loss: 0.265737
Train Epoch: 2 [51200/60000 (85%)] Loss: 0.323627
Train Epoch: 2 [57600/60000 (96%)] Loss: 0.236692Test set: Avg. loss: 0.1233, Accuracy: 9622/10000 (96%)
Train Epoch: 3 [0/60000 (0%)] Loss: 0.500148
Train Epoch: 3 [6400/60000 (11%)] Loss: 0.338118
Train Epoch: 3 [12800/60000 (21%)] Loss: 0.452308
Train Epoch: 3 [19200/60000 (32%)] Loss: 0.374940
Train Epoch: 3 [25600/60000 (43%)] Loss: 0.323300
Train Epoch: 3 [32000/60000 (53%)] Loss: 0.203830
Train Epoch: 3 [38400/60000 (64%)] Loss: 0.379557
Train Epoch: 3 [44800/60000 (75%)] Loss: 0.334822
Train Epoch: 3 [51200/60000 (85%)] Loss: 0.361676
Train Epoch: 3 [57600/60000 (96%)] Loss: 0.218833Test set: Avg. loss: 0.0911, Accuracy: 9723/10000 (97%)
完整代码
import torchvision
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
import matplotlib.pyplot as plt
# 设置超参数
n_epochs = 3
batch_size_train = 64
batch_size_test = 1000
learning_rate = 0.01
momentum = 0.5
log_interval = 100
random_seed = 1
torch.manual_seed(random_seed)
# 数据读取
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_train, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('./data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,))
])),
batch_size=batch_size_test, shuffle=True)
examples = enumerate(test_loader)
batch_idx, (example_data, example_targets) = next(examples)
# 调试输出
print(example_targets)
print(example_data.shape)
# 画图 (前6个)
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(example_data[i][0], cmap='gray', interpolation='none')
plt.title("Ground Truth: {}".format(example_targets[i]))
plt.xticks([])
plt.yticks([])
plt.show()
# 创建model
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 10, kernel_size=5)
self.conv2 = nn.Conv2d(10, 20, kernel_size=5)
self.conv2_drop = nn.Dropout2d()
self.fc1 = nn.Linear(320, 50)
self.fc2 = nn.Linear(50, 10)
def forward(self, x):
x = F.relu(F.max_pool2d(self.conv1(x), 2))
x = F.relu(F.max_pool2d(self.conv2_drop(self.conv2(x)), 2))
x = x.view(-1, 320)
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
return F.log_softmax(x)
network = Net()
optimizer = optim.SGD(network.parameters(), lr=learning_rate,
momentum=momentum)
# 训练
train_losses = []
train_counter = []
test_losses = []
test_counter = [i * len(train_loader.dataset) for i in range(n_epochs + 1)]
def train(epoch):
network.train()
for batch_idx, (data, target) in enumerate(train_loader):
optimizer.zero_grad()
output = network(data)
loss = F.nll_loss(output, target)
loss.backward()
optimizer.step()
if batch_idx % log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
train_losses.append(loss.item())
train_counter.append(
(batch_idx * 64) + ((epoch - 1) * len(train_loader.dataset)))
torch.save(network.state_dict(), './model.pth')
torch.save(optimizer.state_dict(), './optimizer.pth')
def test():
network.eval()
test_loss = 0
correct = 0
with torch.no_grad():
for data, target in test_loader:
output = network(data)
test_loss += F.nll_loss(output, target, size_average=False).item()
pred = output.data.max(1, keepdim=True)[1]
correct += pred.eq(target.data.view_as(pred)).sum()
test_loss /= len(test_loader.dataset)
test_losses.append(test_loss)
print('\nTest set: Avg. loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
for epoch in range(1, n_epochs + 1):
train(epoch)
test()
到此这篇关于PyTorch一小时掌握之神经网络分类篇的文章就介绍到这了,更多相关PyTorch神经网络分类内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Pytorch实现神经网络的分类方式
本文用于利用Pytorch实现神经网络的分类!!! 1.训练神经网络分类模型 import torch from torch.autograd import Variable import matplotlib.pyplot as plt import torch.nn.functional as F import torch.utils.data as Data torch.manual_seed(1)#设置随机种子,使得每次生成的随机数是确定的 BATCH_SIZE = 5#设置batch
-

PyTorch一小时掌握之神经网络分类篇
目录 概述 导包 设置超参数 读取数据 可视化展示 建立模型 训练模型 完整代码 概述 对于 MNIST 手写数据集的具体介绍, 我们在 TensorFlow 中已经详细描述过, 在这里就不多赘述. 有兴趣的同学可以去看看之前的文章: https://www.jb51.net/article/222183.htm 在上一节的内容里, 我们用 PyTorch 实现了回归任务, 在这一节里, 我们将使用 PyTorch 来解决分类任务. 导包 import torchvision import to
-
PyTorch一小时掌握之神经网络气温预测篇
目录 概述 导包 数据读取 数据预处理 构建网络模型 数据可视化 完整代码 概述 具体的案例描述在此就不多赘述. 同一数据集我们在机器学习里的随机森林模型中已经讨论过. 导包 import numpy as np import pandas as pd import datetime import matplotlib.pyplot as plt from pandas.plotting import register_matplotlib_converters from sklearn.pre
-
PyTorch一小时掌握之图像识别实战篇
目录 概述 预处理 导包 数据读取与预处理 数据可视化 主体 加载参数 建立模型 设置哪些层需要训练 优化器设置 训练模块 开始训练 测试 测试网络效果 测试训练好的模型 测试数据预处理 展示预测结果 概述 今天我们要来做一个进阶的花分类问题. 不同于之前做过的鸢尾花, 这次我们会分析 102 中不同的花. 是不是很上头呀. 预处理 导包 常规操作, 没什么好解释的. 缺模块的同学自行pip -install. import numpy as np import time from matplo
-
PyTorch一小时掌握之autograd机制篇
目录 概述 代码实现 手动定义求导 计算流量 反向传播计算 线性回归 导包 构造 x, y 构造模型 参数 & 损失函数 训练模型 完整代码 概述 PyTorch 干的最厉害的一件事情就是帮我们把反向传播全部计算好了. 代码实现 手动定义求导 import torch # 方法一 x = torch.randn(3, 4, requires_grad=True) # 方法二 x = torch.randn(3,4) x.requires_grad = True b = torch.randn(3
-
PyTorch一小时掌握之迁移学习篇
目录 概述 为什么使用迁移学习 更好的结果 节省时间 加载模型 ResNet152 冻层实现 模型初始化 获取需更新参数 训练模型 获取数据 完整代码 概述 迁移学习 (Transfer Learning) 是把已学训练好的模型参数用作新训练模型的起始参数. 迁移学习是深度学习中非常重要和常用的一个策略. 为什么使用迁移学习 更好的结果 迁移学习 (Transfer Learning) 可以帮助我们得到更好的结果. 当我们手上的数据比较少的时候, 训练非常容易造成过拟合的现象. 使用迁移学习可以
-
PyTorch一小时掌握之基本操作篇
目录 创建数据 torch.empty() torch.zeros() torch.ones() torch.tensor() torch.rand() 数学运算 torch.add() torch.sub() torch.matmul() 索引操作 创建数据 torch.empty() 创建一个空张量矩阵. 格式: torch.empty(*size, *, out=None, dtype=None, layout=torch.strided, device=None, requires_gr
-
Pytorch实现基于CharRNN的文本分类与生成示例
1 简介 本篇主要介绍使用pytorch实现基于CharRNN来进行文本分类与内容生成所需要的相关知识,并最终给出完整的实现代码. 2 相关API的说明 pytorch框架中每种网络模型都有构造函数,在构造函数中定义模型的静态参数,这些参数将对模型所包含weights参数的维度进行设置.在运行时,模型的实例将接收动态的tensor数据并调用forword,在得到模型输出之后便可以和真实的标签数据进行误差计算,并通过优化器进行反向传播以调整模型的参数.下面重点介绍NLP常用到的模型和相关方法. 2
-
利用pytorch实现对CIFAR-10数据集的分类
步骤如下: 1.使用torchvision加载并预处理CIFAR-10数据集. 2.定义网络 3.定义损失函数和优化器 4.训练网络并更新网络参数 5.测试网络 运行环境: windows+python3.6.3+pycharm+pytorch0.3.0 import torchvision as tv import torchvision.transforms as transforms import torch as t from torchvision.transforms import
-
Pytorch 实现计算分类器准确率(总分类及子分类)
分类器平均准确率计算: correct = torch.zeros(1).squeeze().cuda() total = torch.zeros(1).squeeze().cuda() for i, (images, labels) in enumerate(train_loader): images = Variable(images.cuda()) labels = Variable(labels.cuda()) output = model(images) prediction = to
-
Python机器学习应用之基于天气数据集的XGBoost分类篇解读
目录 一.XGBoost 1 XGBoost的优点 2 XGBoost的缺点 二.实现过程 1 数据集 2 实现 三.Keys XGBoost的重要参数 一.XGBoost XGBoost并不是一种模型,而是一个可供用户轻松解决分类.回归或排序问题的软件包. 1 XGBoost的优点 简单易用.相对其他机器学习库,用户可以轻松使用XGBoost并获得相当不错的效果. 高效可扩展.在处理大规模数据集时速度快效果好,对内存等硬件资源要求不高. 鲁棒性强.相对于深度学习模型不需要精细调参便能取得接近的