yolov5调用usb摄像头及本地摄像头的方法实例
目录
- yolov5调用usb摄像头
- YOLOv5调用本地摄像头
- 总结
yolov5 调用 usb 摄像头
文章是在yolov5 v5.0版本的detect.py所修改编写
其他v1.0-v4.0没有试过,你们可以试试。
具体用法已经写在代码里面了。
import time
import cv2
import numpy as np
import torch
from models.experimental import attempt_load
from utils.datasets import letterbox
from utils.general import check_img_size, non_max_suppression,scale_coords, xyxy2xywh,set_logging,check_requirements
from utils.plots import colors, plot_one_box
from utils.torch_utils import select_device,time_synchronized
@torch.no_grad()
def detect(
#--------------------这里更改配置--------------------
#---------------------------------------------------
weights='runs/train/exp25/weights/best.pt', #训练好的模型路径 (必改)
imgsz=512, #训练模型设置的尺寸 (必改)
cap = 0, #摄像头
conf_thres=0.25, #置信度
iou_thres=0.45, #NMS IOU 阈值
max_det=1000, #最大侦测的目标数
device='', #设备
crop=True, #显示预测框
classes=None, #种类
agnostic_nms=False, #class-agnostic NMS
augment=False, #是否扩充推理
half=False, #使用FP16半精度推理
hide_labels=False, #是否隐藏标签
hide_conf=False, #是否隐藏置信度
line_thickness=3 #预测框的线宽
):
# #--------------------这里更改配置--------------------
#-----------------------------------------------------
#打开摄像头
cap = cv2.VideoCapture(cap)
#-----初始化-----
set_logging()
#设置设备
device = select_device(device)
#CUDA仅支持半精度
half &= device.type != 'cpu'
#-----加载模型-----
#加载FP32模型
model = attempt_load(weights, map_location=device)
#模型步幅
stride = int(model.stride.max())
#检查图像大小
imgsz = check_img_size(imgsz, s=stride)
#获取类名
names = model.module.names if hasattr(model, 'module') else model.names
#toFP16
if half:
model.half()
#------运行推理------
if device.type != 'cpu':
model(torch.zeros(1, 3, imgsz, imgsz).to(device).type_as(next(model.parameters()))) # 跑一次
#-----进入循环:ESC退出-----
while(True):
#设置labels--记录标签/概率/位置
labels = []
#计时
t0 = time.time()
ref,img0=cap.read()
#填充调整大小
img = letterbox(img0, imgsz, stride=stride)[0]
# 转换
img = img[:, :, ::-1].transpose(2, 0, 1) #BGR to RGB, to 3x416x416
img = np.ascontiguousarray(img)
img = torch.from_numpy(img).to(device)
#uint8 to fp16/32
img = img.half() if half else img.float()
#0 - 255 to 0.0 - 1.0
img /= 255.0
if img.ndimension() == 3:
img = img.unsqueeze(0)
# 推断
t1 = time_synchronized()
pred = model(img, augment=augment)[0]
# 添加 NMS
pred = non_max_suppression(pred, conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
t2 = time_synchronized()
#目标进程
for i, det in enumerate(pred): # 每幅图像的检测率
s, im0 = '', img0.copy()
#输出字符串
s += '%gx%g ' % img.shape[2:]
#归一化增益
gn = torch.tensor(im0.shape)[[1, 0, 1, 0]]
if len(det):
# 将框从img_大小重新缩放为im0大小
det[:, :4] = scale_coords(img.shape[2:], det[:, :4], im0.shape).round()
# 输出结果
for c in det[:, -1].unique():
#每类检测数
n = (det[:, -1] == c).sum()
#添加到字符串
s += f"{n} {names[int(c)]}{'s' * (n > 1)}, "
# 结果输出
for *xyxy, conf, cls in reversed(det):
#归一化xywh
xywh = (xyxy2xywh(torch.tensor(xyxy).view(1, 4)) / gn).view(-1).tolist()
#标签格式
line = (cls, *xywh, conf)
#整数类
c = int(cls)
#建立标签
label = None if hide_labels else (names[c] if hide_conf else f'{names[c]} {conf:.2f}')
#绘画预测框
if crop:
plot_one_box(xyxy, im0, label=label, color=colors(c, True), line_thickness=line_thickness)
#记录标签/概率/位置
labels.append([names[c],conf,xyxy])
#--------------------这里写/修改代码--------------------
#-------------------------------------------------
'''
labels里面有该图片的标签/概率/坐标(列表)
labels = [ [列表0] , [列表1] , [列表3] ,......]
其中 列表 = [标签,概率,坐标]
例如获取第一个预测框的概率值:print( float( labels[0][1]) )
'''
# 显示图片
cv2.imshow("666",im0)
#输出计算时间
print(f'消耗时间: ({time.time() - t0:.3f}s)')
key = cv2.waitKey(20)
#这里设置ESC退出
if key == 27:
break
#--------------------END--------------------
#-------------------------------------------------
cv2.destroyAllWindows()
if __name__ == "__main__":
'''
修改配置在 13-28 行
写代码-显示输出/获取预测框位置/获取预测概率值 在121-END行
'''
#检测安装包--建议注释掉
#check_requirements(exclude=('tensorboard', 'thop'))
#运行
detect()
经研究发现,yolov5-master有time_synchronized 和 time_sync 两种名字,所以如果time_synchronized报错,麻烦换成time_sync
YOLOv5调用本地摄像头
YOLOv5源码:https://github.com/ultralytics/yolov5
最近用YOLOv5做目标检测,直接调用本地摄像头会报错,需要在dataset中做一点修改。
具体如下:
在279行的这两处改成str类型
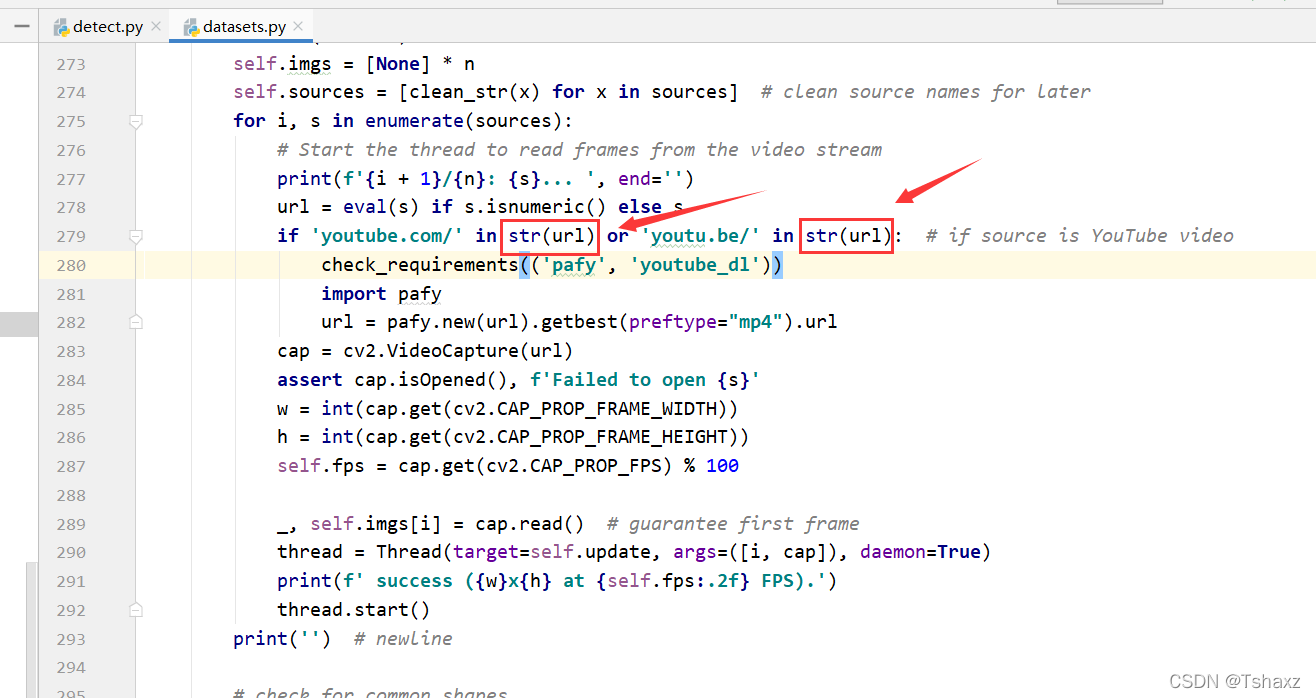
然后在detect里把这里的参数改为0

然后运行detect.py即可调用本地摄像头。
总结
到此这篇关于yolov5调用usb摄像头及本地摄像头的文章就介绍到这了,更多相关yolov5调用摄像头内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

win10+anaconda安装yolov5的方法及问题解决方案
对于yolo系列,应用广泛,在win10端也有很大的应用需求,所以这篇文章给出win10环境下的安装教程. 先给出系列文章win10+anacnda实现yolov3 YOLOV5-3.0/3.1版本 版本问题 python 3.7 torch 1.6.0 torchvision 0.7.0 cuda 10.1 注意:Yolov5-3.1只能使用torch 1.6.0 1.在网站下载对应版本的torch和torchvision的whl文件 https://download.pytorch.org/
-
教你用YOLOv5实现多路摄像头实时目标检测功能
目录 前言 一.YOLOV5的强大之处 二.YOLOV5部署多路摄像头的web应用 1.多路摄像头读取 2.模型封装 3.Flask后端处理 4.前端展示 总结 前言 YOLOV5模型从发布到现在都是炙手可热的目标检测模型,被广泛运用于各大场景之中.因此,我们不光要知道如何进行yolov5模型的训练,而且还要知道怎么进行部署应用.在本篇博客中,我将利用yolov5模型简单的实现从摄像头端到web端的部署应用demo,为读者提供一些部署思路. 一.YOLOV5的强大之处 你与目标检测高手之差一个Y
-
yolov5 win10 CPU与GPU环境搭建过程
前言 最近实习任务为黑烟检测,想起了可以尝试用yolov5来跑下,之前一直都是用的RCNN系列,这次就试试yolo系列. 一.安装pytorch 1.创建新的环境 打开Anaconda Prompt命令行输入 创建一个新环境,并激活进入环境. # 创建了名叫yolov5的,python版本为3.8的新环境 conda create -n yolov5 python=3.8 # 激活名叫yolov5的环境 conda activate yolov5 2.下载YOLOv5 github项目 下载地址
-
yolov5调用usb摄像头及本地摄像头的方法实例
目录 yolov5调用usb摄像头 YOLOv5调用本地摄像头 总结 yolov5 调用 usb 摄像头 文章是在yolov5 v5.0版本的detect.py所修改编写 其他v1.0-v4.0没有试过,你们可以试试. 具体用法已经写在代码里面了. import time import cv2 import numpy as np import torch from models.experimental import attempt_load from utils.datasets impor
-
使用FeignClient调用远程服务时整合本地的实现方法
目录 FeignClient调用远程服务时整合本地 尝试将本地方法加入Feign接口 尝试通过实现两个接口 IS->HAS FeignClient服务之间调用 服务A需调用服务B的test方法 A的application配置加 FeignClient调用远程服务时整合本地 包装一个用户服务,一部分功能需要调用远程服务,而另一部分功能调用本地方法,如: @FeignClient(value="USER-SERVICE") public interface RemoteUserSer
-
Python调用C语言开发的共享库方法实例
在helloworld工程中,编写了一个简单的两个数值相加的程序,编译成为共享库后,如何使用python对其进行调用呢? 使用ll命令列出当前目录下的共享库,其中共享库名为libhelloworld.so.0.0.0 复制代码 代码如下: ufo@ufo:~/helloworld/.libs$ ll 总用量 32 drwxr-xr-x 2 ufo ufo 4096 1月 29 14:54 ./ drwxr-xr-x 6 ufo ufo 4096 1月 29 16:08 ../ -rw-r--
-
JS实现调用本地摄像头功能示例
本文实例讲述了JS实现调用本地摄像头功能.分享给大家供大家参考,具体如下: 今天学习了一下js调用本地摄像头,其实是实现不是很麻烦,下面是代码部分,连接上Tomcat服务器,然后再到网页上打开即可以看到效果了..快来玩一下吧! <!doctype html> <html lang="en"> <head> <meta charset="utf-8" /> <title></title> <
-
vue调用本地摄像头实现拍照功能
前言: vue调用本地摄像头实现拍照功能,由于调用摄像头有使用权限,只能在本地运行,线上需用https域名才可以使用.实现效果: 1.摄像头效果: 2.拍照效果: 实现代码: <template> <div class="camera_outer"> <video id="videoCamera" :width="videoWidth" :height="videoHeight" autoplay
-
C#调用usb摄像头的实现方法
1.下载AForge类库,下载地址:https://code.google.com/archive/p/aforge/downloads,我下载的版本是:AForge.NET Framework-2.2.5.exe: 2.下载安装好后,将下载类库中的Release文件夹复制到C#项目的可执行文件文件夹,即Debug文件夹下: 3.在C#项目中添加引用,右击解决方案资源管理器下的引用上,点击添加引用,通过浏览找到Debug文件夹下的Release文件夹选择要添加的引用文件:AForge.AForg
-
C#调用USB摄像头的方法
C#调用USB摄像头使用AForge类库进行开发,供大家参考,具体内容如下 1.AForge安装 右击工程,在管理NuGet程序包中搜索Aforge类库,选择安装,如下图所示 2.进行USB摄像头类封装 a.初始化,初始化时要注意,加载的设备分辨率需要人工配置,如果配置分辨率不存在需要从默认的分辨率中选择 videoDevices = new FilterInfoCollection(FilterCategory.VideoInputDevice); if (videoDevices.Cou
-
python实现从本地摄像头和网络摄像头截取图片功能
python-----从本地摄像头和网络摄像头截取图片 ,具体代码如下所示: import cv2 # 获取本地摄像头 # folder_path 截取图片的存储目录 def get_img_from_camera_local(folder_path): cap = cv2.VideoCapture(0) i = 1 while True: ret, frame = cap.read() cv2.imshow("capture", frame) print str(i) cv2.imw
-
Python+OpenCV采集本地摄像头的视频
本文实现了用Python和OpenCV配合,调用本地摄像头采集视频,基本上函数的话看opencv的官方文档就Ok了(The OpenCV Reference Manual Release 2.4.7.0) 上代码: import cv2 import cv2.cv def getCam(): window_name='show image' cv2.namedWindow(window_name,cv2.WINDOW_NORMAL) video_cap_obj=cv2.VideoCapture
-
Qt音视频开发之利用ffmpeg实现解码本地摄像头
目录 一.前言 二.效果图 三.体验地址 四.相关代码 五.功能特点 5.1 基础功能 5.2 特色功能 5.3 视频控件 一.前言 一开始用ffmpeg做的是视频流的解析,后面增加了本地视频文件的支持,到后面发现ffmpeg也是支持本地摄像头设备的,只要是原则上打通的比如win系统上相机程序.linux上茄子程序可以正常打开就表示打通,整个解码显示过程完全一样,就是打开的时候要传入设备信息,而且参数那边可以指定分辨率和帧率等,本地摄像机一般会支持多个分辨率,用户需要哪种分辨率都可以指定该分辨率