Java应用服务器之tomcat会话复制集群配置的示例详解
会话是识别用户,跟踪用户访问行为的一个手段,通过cookie(存在客户端)或session(存在服务端)来判断本次请求是那个客户端发送过来;常用的会话保持有绑定会话,就是前边我们聊的在代理上通过算法或通过给客户端响应首部加cookie这种方式来保持同一cookie或同一ip地址的请求始终发送到同一后端server进行响应;但是这样的会话绑定的方式存在一个问题,就是当后端某一server宕机,那么之前上面的所有会话信息将消失,那么后续的客户端来请求,代理是否要把请求调度到后端宕机的server呢?如果说调度上去呢,那么用户之前的会话信息又没有了,如果说不调度呢,那么用户将不能够得到服务;所以对于这种情况我们需要把会话都同步到后端所有server上,即便某一台或几台后端server宕机了,不会导致用户的会话信息丢失,同样服务也是可用的;这种冗余的方式保存会话信息,使得用户的会话信息能够在任何一台后端server上都会有;这也意味着只要有用户来请求,前端调度器可以任意把请求调度到后端的某一台server上,然后服务端把本次请求的用户会话信息通过广播的方式,通知给其他后端server,这样一来这个客户端后续来请求,不管调度到后端那一台server上,因为后端server上都有这个客户端之前请求的会话信息,所以不管到那一台都能够识别;对于tomcat来讲,它内部就有一个组件支持这样的功能,它可以基于多播通信的方式,把会话信息同步给后端其他节点,这个组件就是cluster;
示例:使用tomcat cluster组件来定义tomcat的会话复制集群
环境说明
| 名称 | ip地址 | 端口 |
| 代理Nginx | 192.168.0.41 | 80 |
| 应用服务tomcatA | 192.168.0.42 | 8080 |
| 应用服务tomcatB | 192.168.0.43 | 8080 |
准备测试页面,以及配置tomcatA

提示:以上是myapp里的内容以及文件目录结构
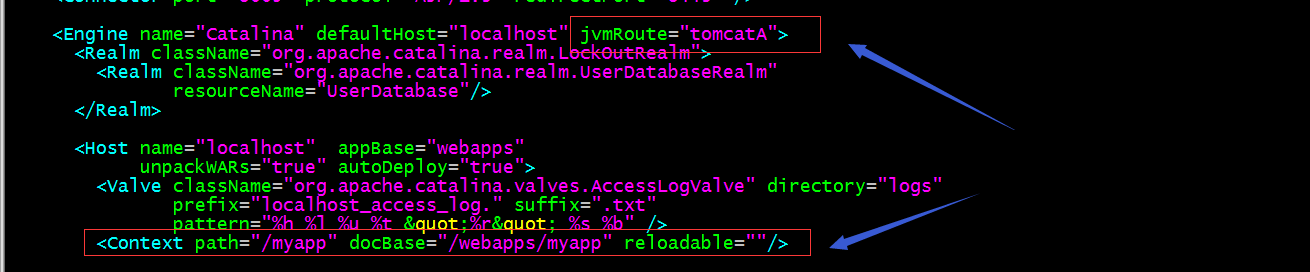
提示:以上配置表示部署一个/myapp的应用,它的文件路径在/webapps/myapp,并且在engine上配置了 jvmRoute=“tomcatA”;

提示:cluster配置需要注意上面打红框的位置,在官方配置文档中,后面的<ClusterListener 的后面没有把标签闭合了,我们在使用时需要给它闭合了,否则会出现语法错,导致tomcat起不来;其次就是我们需要更改接收器的ip地址,默认它是auto,auto表示自动监听本机一个地址,这个地址也可能是127.0.0.1,如果监听在127.0.0.1,那么主机就不能够接收到,其他节点发来的会话信息;说下这个配置文件吧,cluster组件中主要就是定义了DeltaManager的属性,该组件用于处理增量会话的事务,也就是用这个管理的功能实现多节点复制会话信息;其次我们要在其cluster内部定义个chanel,这个组件主要定义集群通信和各成员的一些属性,比如成员关系判定呀,接收器和发送器;Membership组件用于定义成员关系判定的,里面主要定义多播地址和端口等属性,如果多播地址相同,那么就是同一集群的成员,否则不是;Receiver主要用于定义接收器的相关属性,比如接收器监听的地址和端口超时时长,最大线程等等;Sender用于指定发送器,发送器我们这里不需要认为手动定义,用官方给定的示例即可;后面的Interceptor主要定义了tcp报文的检查以及消息摘要,后面两台哦Interceptor主要作用是保证tcp报文的完整和正确性;Deployer主要用于定义部署应用相关属性,它的主要作用是如果我们定义了集群,我们可以在集群成员中的一台server上部署好应用,然后其他成员可以通过网络自动部署;通常我们建议使用这个自动部署的功能;
完整的server.xml配置
<?xml version='1.0' encoding='utf-8'?>
<Server port="8005" shutdown="SHUTDOWN">
<Listener className="org.apache.catalina.startup.VersionLoggerListener" />
<Listener className="org.apache.catalina.core.AprLifecycleListener" SSLEngine="on" />
<Listener className="org.apache.catalina.core.JasperListener" />
<Listener className="org.apache.catalina.core.JreMemoryLeakPreventionListener" />
<Listener className="org.apache.catalina.mbeans.GlobalResourcesLifecycleListener" />
<Listener className="org.apache.catalina.core.ThreadLocalLeakPreventionListener" />
<GlobalNamingResources>
<Resource name="UserDatabase" auth="Container"
type="org.apache.catalina.UserDatabase"
description="User database that can be updated and saved"
factory="org.apache.catalina.users.MemoryUserDatabaseFactory"
pathname="conf/tomcat-users.xml" />
</GlobalNamingResources>
<Service name="Catalina">
<Connector port="8080" protocol="HTTP/1.1"
connectionTimeout="20000"
redirectPort="8443" />
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
<Engine name="Catalina" defaultHost="localhost" jvmRoute="tomcatA">
<Realm className="org.apache.catalina.realm.LockOutRealm">
<Realm className="org.apache.catalina.realm.UserDatabaseRealm"
resourceName="UserDatabase"/>
</Realm>
<Host name="localhost" appBase="webapps"
unpackWARs="true" autoDeploy="true">
<Valve className="org.apache.catalina.valves.AccessLogValve" directory="logs"
prefix="localhost_access_log." suffix=".txt"
pattern="%h %l %u %t "%r" %s %b" />
<Context path="/myapp" docBase="/webapps/myapp" reloadable=""/>
<Cluster className="org.apache.catalina.ha.tcp.SimpleTcpCluster"
channelSendOptions="8">
<Manager className="org.apache.catalina.ha.session.DeltaManager"
expireSessionsOnShutdown="false"
notifyListenersOnReplication="true"/>
<Channel className="org.apache.catalina.tribes.group.GroupChannel">
<Membership className="org.apache.catalina.tribes.membership.McastService"
address="228.0.0.4"
port="45564"
frequency="500"
dropTime="3000"/>
<Receiver className="org.apache.catalina.tribes.transport.nio.NioReceiver"
address="192.168.0.42"
port="4000"
autoBind="100"
selectorTimeout="5000"
maxThreads="6"/>
<Sender className="org.apache.catalina.tribes.transport.ReplicationTransmitter">
<Transport className="org.apache.catalina.tribes.transport.nio.PooledParallelSender"/>
</Sender>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.TcpFailureDetector"/>
<Interceptor className="org.apache.catalina.tribes.group.interceptors.MessageDispatch15Interceptor"/>
</Channel>
<Valve className="org.apache.catalina.ha.tcp.ReplicationValve"
filter=""/>
<Valve className="org.apache.catalina.ha.session.JvmRouteBinderValve"/>
<Deployer className="org.apache.catalina.ha.deploy.FarmWarDeployer"
tempDir="/tmp/war-temp/"
deployDir="/tmp/war-deploy/"
watchDir="/tmp/war-listen/"
watchEnabled="false"/>
<ClusterListener className="org.apache.catalina.ha.session.JvmRouteSessionIDBinderListener"/>
<ClusterListener className="org.apache.catalina.ha.session.ClusterSessionListener"/>
</Cluster>
</Host>
</Engine>
</Service>
</Server>
给我们定义的应用修改器web.xml 在其中加上<distributable/>元素

提示:对于web.xml配置文件,我们可以从/etc/tomcat/中复制一份到自己的应用目录结构里,然后在非注释掉位置加上<distributable/>元素即可
对于tomcatB来说,我们也需要准备好同样的文件,为了区分,我们把index.jsp修改成tomcatB ,在配置文件中我们需要修改接收器的监听地址,以及jvmRoute的值,其他的都可以不变


到此tomcat会话复制集群就配置好了;其实从上面的配置文件可以看大,tomcat的会话复制集群就是利用多播地址通信,一个请求不管到集群那个基点,它都会通过多播通信,把会话信息以组播的方式发送给其他成员;这里建议把接收器的地址专门用张网卡配置好地址;接下来我们启动下tomcatA,tomcatB,然后看看日志是否初始集群成功,并接收到集群成员接收器的地址;

提示:这里注意一点如果tomcat启动特别慢,就是8005端口要等很久才起来,可以尝试安装rng-tools,并启动rngd,这样可以加快tomcat启动


提示:如果在tomcatA的日志中能够看到tomcatB的接收器地址和端口,那么就表示tomcatA已经识别到tomcatB,并把tomcatB当作集群成员加入到集群;同样在tomcatB的日志中能够看到tomcatA的接收器地址和端口,表示tomcatB已经识别tomcatA并把它加入到集群;
配置nginx负载均衡后端两台tomcat server

提示:这里需要主要反代时需要把反代的URI和后面proxy_pass后面的URI相同,否则代理后,会话复制集群不会生效;
验证:检查nginx的配置文件语法,启动nginx访问192.168.0.41/myapp看看有什么变化




提示:可以看到访问192.168.0.41/myapp时sessionid始终没有发生变化,变化的只有后面的jvmRoute的值和页面的值;这说明我们访问nginx时,nginx也基于自己的轮询算法把请求调度到后端去了,第一次访问时,后端server会响应一个set-cookie的首部,把当前访问的页面的session信息响应给客户端,第二次访问客户端就会把上一次访问相应的cookie带上去访问,这时后端server接受到客户端发送过来的cookie,然后就在自己内存里找对应的session信息;由于后端server是把session信息基于多播通信的方式共享给集群其他节点,所以第二次不管调度到那台server上,对应server都会有该客户端第一次访问服务端的session信息;所以我们第二次访问时,sessionid还是第一次访问服务器的sessionid,后面的tomcatB表示由tomcatB这个jvmRoute处理的这次请求;
总结
到此这篇关于Java应用服务器之tomcat会话复制集群配置的文章就介绍到这了,更多相关java tomcat会话复制集群配置内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Java新手环境搭建 Tomcat安装配置教程
安装 Tomcat 之前请一定先安装 Java ,然后才能安装 Tomcat . 安装 Java .环境变量 path 的设置以及 cmd 小技巧请看:Java新手环境搭建 JDK8安装配置教程 下载 Tomcat 首先到 Tomcat 的官方网站下载 Windows 版本的 Tomcat 最新版,根据我们所使用的操作系统,我们下载 64 位 Windows 的 zip 版本.不建议使用 Installer 版本. 我们以 apache-tomcat-9.0.0.M15-windows-x64.
-
Java调用Redis集群代码及问题解决
前言 需要使用以下jar包 Maven项目引用以下配置: <dependency> <groupId>org.apache.commons</groupId> <artifactId>commons-pool2</artifactId> <version>2.6.2</version> </dependency> <dependency> <groupId>redis.clients&l
-
IDEA部署JavaWeb项目到Tomcat服务器的方法
IDEA创建一个传统JAVA WEB项目(不使用maven构建) 方法一 File --> NEW --> Project --> Java (勾选Web Application) 方法二 File --> NEW --> Project --> Java Enterprise(勾选Web Application) IDEA部署JAVA WEB项目 IDEA 并非把项目放到 tomcat 的 webapp目录中,而项目还是在源项目目录中,IDEA采用了一种无入侵Tomc
-
tomcat启动报错:java.util.zip.ZipException的解决方法
发现问题 早上起来报错误,Jenkins打包到tomcat服务器,死活启动不起来,一些定时任务也没跑成功. 报错如下: org.apache.catalina.startup.ContextConfig.beforeStart Exception fixing docBase for context [/test] java.util.zip.ZipException: error in opening zip file at java.util.zip.ZipFile.open(Native
-
java结合HADOOP集群文件上传下载
对HDFS上的文件进行上传和下载是对集群的基本操作,在<HADOOP权威指南>一书中,对文件的上传和下载都有代码的实例,但是对如何配置HADOOP客户端却是没有讲得很清楚,经过长时间的搜索和调试,总结了一下,如何配置使用集群的方法,以及自己测试可用的对集群上的文件进行操作的程序.首先,需要配置对应的环境变量: 复制代码 代码如下: hadoop_HOME="/home/work/tools/java/hadoop-client/hadoop" for f in $hadoo
-
java 分布式与集群的区别和联系
一.先说区别: 一句话:分布式是并联工作的,集群是串联工作的. 1.分布式是指将不同的业务分布在不同的地方. 而集群指的是将几台服务器集中在一起,实现同一业务. 分布式中的每一个节点,都可以做集群. 而集群并不一定就是分布式的. 举例:就比如新浪网,访问的人多了,他可以做一个群集,前面放一个响应服务器,后面几台服务器完成同一业务,如果有业务访问的时候,响应服务器看哪台服务器的负载不是很重,就将给哪一台去完成. 而分布式,从窄意上理解,也跟集群差不多, 但是它的组织比较松散,不像集群,有一个组织性
-
JAVA环境搭建之MyEclipse10+jdk1.8+tomcat8环境搭建详解
一.安装JDK 1.下载得到jdk-8u11-windows-i586.1406279697.exe,直接双击运行安装,一直next就可以,默认是安装到系统盘下面Program Files, 我这里装在D:\Program Files\Java下面,注意安装完jdk之后会自动运行安装jre,这时的安装路径最好和jdk一样,方便管理,我的都是在D:\Program Files\Java下面. 2.环境变量配置: 右击"我的电脑",点击"属性":选择"高级系统
-
Java应用服务器之tomcat会话复制集群配置的示例详解
会话是识别用户,跟踪用户访问行为的一个手段,通过cookie(存在客户端)或session(存在服务端)来判断本次请求是那个客户端发送过来:常用的会话保持有绑定会话,就是前边我们聊的在代理上通过算法或通过给客户端响应首部加cookie这种方式来保持同一cookie或同一ip地址的请求始终发送到同一后端server进行响应:但是这样的会话绑定的方式存在一个问题,就是当后端某一server宕机,那么之前上面的所有会话信息将消失,那么后续的客户端来请求,代理是否要把请求调度到后端宕机的server呢?
-
Java应用服务器之tomcat部署的详细教程
一.相关术语简介 首先我们来了解下tomcat是什么,tomcat是apache软件基金会中的一个项目,由apache.Sun 和其他一些公司及个人共同开发而成.主要作用是提供servlet和jsp类库:tomcat是一个免费开源的web服务器,它和nginx.httpd服务不同的是,它不擅长处理HTML代码,更多的是处理JSP程序:有点类似fpm服务专门处理php程序: jdk:java开发工具箱(Java Development Kit),主要提供java开发相关工具包,库文件以及jre和j
-
Nginx+Tomcat负载均衡集群的实现示例
目录 引言 一.案例概述 二.环境部署 三.Nginx 主机安装 四.Tomcat 安装及配置 1. 安装 Tomcat 2. Tomcat 服务器1配置 3. Tomcat 服务器2配置 五.Nginx server 配置 六.验证结果 总结 引言 通常情况下,一个 Tomcat 站点由于可能出现单点故障以及无法应付过多客户复杂多样的请求等问题,不能单独应用于生产环境中,所以需要一套更可靠的解决方案来完善 Web 站点架构. 一.案例概述 Nginx 是一款非常优秀的 http 服务器软件,它
-
Mongo复制集同步验证的实例详解
mongo复制集同步验证的实例详解 第一步:在主节点上插入一条数据 Sql代码 rs0:PRIMARY> use imooc switched to db imooc rs0:PRIMARY> db.imooc.insert({"name":"imooc"}) WriteResult({ "nInserted" : 1 }) 第二步:在从节点查看数据,看是否同步 Sql代码 rs0:SECONDARY> use imooc sw
-
Linux(Centos7)下redis5集群搭建和使用说明详解
1.简要说明 2018年十月 Redis 发布了稳定版本的 5.0 版本,推出了各种新特性,其中一点是放弃 Ruby的集群方式,改为 使用 C语言编写的 redis-cli的方式,是集群的构建方式复杂度大大降低.关于集群的更新可以在 Redis5 的版本说明中看到,如下: The cluster manager was ported from Ruby (redis-trib.rb) to C code inside redis-cli. check `redis-cli --cluster h
-
docker swarm 集群故障与异常详解
本文介绍了docker swarm 集群故障与异常详解,分享给大家,具体如下: 在上次遭遇 docker swarm 集群故障后,我们将 docker 由 17.10.0-ce 升级为最新稳定版 docker 17.12.0-ce . 前天晚上22:00之后集群中的2个节点突然出现CPU波动,在CPU波动之后,在凌晨夜深人静.访问量极低的时候,整个集群出现了故障,访问集群上的所有站点都出现了502,过了一段时间后自动恢复正常. ECS实例:swarm1-node5,CPU百分比于00:52发生告
-
Nginx+Tomcat+Https 服务器负载均衡配置实践方案详解
由于需要,得搭建个nginx+tomcat+https的服务器,搜了搜网上的发现总是有错,现在整理了些有用的,备忘. 环境:Centos6.5.JDK1.8.Tomcat8.Nginx1.10.1 准备材料: 1.JDK1.8安装包jdk-8u102-linux-x64.tar.gz 2.Tomcat8安装包apache-tomcat-8.0.37.tar.gz 3.Nginx1.10安装包nginx-1.10.1.tar.gz 1.JDK安装配置 解压并安装到/usr/local/jdk [r
-
Java实现BP神经网络MNIST手写数字识别的示例详解
目录 一.神经网络的构建 二.系统架构 服务器 客户端 采用MVC架构 一.神经网络的构建 (1):构建神经网络层次结构 由训练集数据可知,手写输入的数据维数为784维,而对应的输出结果为分别为0-9的10个数字,所以根据训练集的数据可知,在构建的神经网络的输入层的神经元的节点个数为784个,而对应的输出层的神经元个数为10个.隐层可选择单层或多层. (2):确定隐层中的神经元的个数 因为对于隐层的神经元个数的确定目前还没有什么比较完美的解决方案,所以对此经过自己查阅书籍和上网查阅资料,有以下的
-
java暴力匹配及KMP算法解决字符串匹配问题示例详解
目录 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 二.KMP算法 算法介绍 一个图例介绍KMP算法 代码实现 要解决的问题? 一.暴力匹配算法 一个图例介绍KMP算法 String str1 = "BBC ABCDAB ABCDABCDABDE"; String str2 = "ABCDABD"; 1. S[0]为B,P[0]为A,不匹配,执行第②条指令:"如果失配(即S[i]! = P[j]),令i = i - (j - 1),
-
java 常规轮询长轮询Long polling实现示例详解
目录 正文 常规轮询 长轮询 正文 长轮询是与服务器保持持久连接的最简单的方式,它不使用任何特定的协议,例如 WebSocket 或者 Server Sent Event. 它很容易实现,在很多场景下也很好用. 常规轮询 从服务器获取新信息的最简单的方式是定期轮询.也就是说,定期向服务器发出请求:“你好,我在这儿,你有关于我的任何信息吗?”例如,每 10 秒一次. 作为响应,服务器首先通知自己,客户端处于在线状态,然后 —— 发送目前为止的消息包. 这可行,但是也有些缺点: 消息传递的延迟最多为