快速解决mysql导数据时,格式不对、导入慢、丢数据的问题
如果希望一劳永逸的解决慢的问题,不妨把你的mysql升级到mysql8.0吧,mysql8.0默认的字符集已经从latin1改为utf8mb4,因此现在UTF8的速度要快得多,在特定查询时速度提高了1800%!
但是如果时间等不及,就先用下面的办法快速解决一下。
问题一:格式不对(常出现时间格式不对的情况);
方法1:将excel文件另存为csv,再导入数据库;
方法2:导入的第一步时,默认编码方式是65001(UTF-8),可以尝试选择【10008 (MAC - Simplified Chinese GB 2312)】,或者【Current Windows Codepage】,这是常见的三种编码,多试几次,总能找到匹配你的电脑的编码格式。
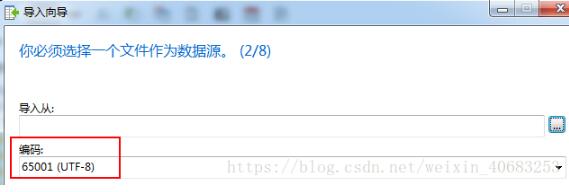
方法3:在导入的最后几步,可以设置时间那一栏位的类型为datetime或者time,总之数据是什么类型就尽量选择什么类型,默认都是varchar。
问题二:导入慢(数据量大导致的慢还请慢慢等他导完);
方法1:如果是别人导给你的数据(不管是sql文件、csv文件、excel文件),你都导的极慢,导入速度一般是:sql文件>csv文件>excel文件。那就让他给你重新导一份吧。不管他之前是什么方式导的,请让他严格按照下面的步骤重新导一次:
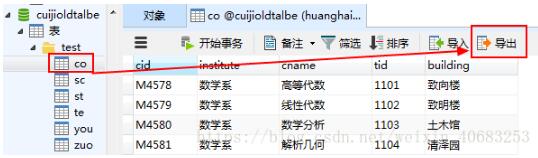
打开要导出的表--在打开表的右上角有一个导出--用这个导出导;
注意:上述的【导出】与右键表的选项中的【导出向导】不一样,用【导出向导】导出来的表有时候会比较慢,所以我一般都用右上角的【导出】来导出数据。
问题三:丢数据(一般是用excel的时候会出现丢数据的情况);
方法1:把Excel另存为csv再导入;
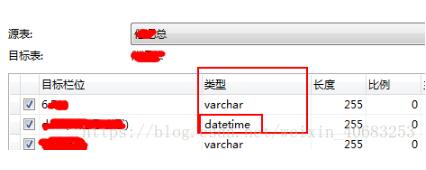
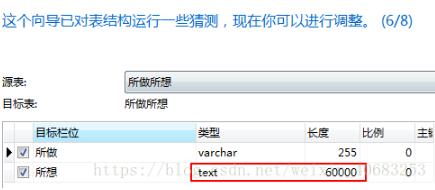
方法2:可能是原始数据中有一列数据量比较大,比如成绩表的最后一列可能是老师的评语,而这一列中有那么几条数据评语写太多了,超过mysql默认的单个package的限制(一般是255),因此在导入的最后一步,把评语这一列的类型改为text,长度改为65535,65535是text类型的最大长度,日常记不住的话,就填60000,基本上就够用了,而且还好记。
方法3:如果是导出的时候丢数据,那么可能是选择了“Excel数据表”,按照下图的方式找适合你的导出方式吧。

但如果上面的办法都没有涵盖你要解决的问题,那么你是不是在mysql导出数据的时候出现问题了呢?不妨看看下面这篇文章。
快速解决mysql导出scv文件乱码、蹿行的问题
以上这篇快速解决mysql导数据时,格式不对、导入慢、丢数据的问题就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Mysql导入导出时遇到的问题解决
背景 自从把我手上的任务全部转换成docker运行和管理之后,遇到了一系列的坑,这次是mysql备份的问题. 原因是启动mysql镜像的时候没有指定-v,导致一段时间之后docker很大,原来的磁盘不够了,需要迁移到新磁盘. 在使用导入导出的时候出现了一些问题,浪费了很多时间去解决. 解决过程 定位mysql镜像过大 查看容器占用的空间 ```docker system df``` 查看详细信息 Local Volumes space usage: VOLUME NAME LINKS SIZE
-
MySQL数据库导出与导入及常见错误解决
MySQL命令行导出数据库: 1,进入MySQL目录下的bin文件夹:cd MySQL中到bin文件夹的目录 如我输入的命令行:cd C:\Program Files\MySQL\MySQL Server 4.1\bin (或者直接将windows的环境变量path中添加该目录) 2,导出数据库:mysqldump -u 用户名 -p 数据库名 > 导出的文件名 如我输入的命令行:mysqldump -u root -p jluibmclub > d:\ jluibmclub .sql (输入
-
MySQL数据库迁移快速导出导入大量数据
数据库迁移是我们经常可遇到的问题,对于少量的数据,迁移基本上不会有什么问题.生产环境中,有以下情况需要做迁移工作: 磁盘空间不够.比如一些老项目,选用的机型并不一定适用于数据库.随着时间的推移,硬盘很有可能出现短缺: 业务出现瓶颈.比如项目中采用单机承担所有的读写业务,业务压力增大,不堪重负.如果 IO 压力在可接受的范围,会采用读写分离方案: 机器出现瓶颈.机器出现瓶颈主要在磁盘 IO 能力.内存.CPU,此时除了针对瓶颈做一些优化以外,选择迁移是不错的方案: 项目改造.某些项目的数据库存在跨
-
MySQL 导入慢的解决方法
导入注意点:使用phpmyadmin或navicat之类的工具的导入功能还是会相当慢,可以直接使用mysql进行导入导入命令如下:mysql> -uroot -psupidea jb51.net<E:\www.jb51.net.sql便可以了说明:mysql> -umysql用户名 -pmysql密码 要导入到的数据库名<要导入MYSQL的SQL文件路径这样导入将会非常快,之前数小时才能导入的sql现在几十秒就可以完成了. 导出时候注意点:-e 使用包括几个VALUES列表的多行I
-
快速解决mysql导数据时,格式不对、导入慢、丢数据的问题
如果希望一劳永逸的解决慢的问题,不妨把你的mysql升级到mysql8.0吧,mysql8.0默认的字符集已经从latin1改为utf8mb4,因此现在UTF8的速度要快得多,在特定查询时速度提高了1800%! 但是如果时间等不及,就先用下面的办法快速解决一下. 问题一:格式不对(常出现时间格式不对的情况): 方法1:将excel文件另存为csv,再导入数据库: 方法2:导入的第一步时,默认编码方式是65001(UTF-8),可以尝试选择[10008 (MAC - Simplified Chin
-
快速解决mysql导出scv文件乱码、蹿行的问题
工作原因,常常不能实现完全的线上化(即,所有数据都在线上完成,不需要导入导出),而导出Excel常常比修炼成仙还慢,因此,我们将数据库文件导出到本地使用的时候,常常使用的方法的是导成CSV格式. 而csv格式的也常常出现导出的中文乱码,或者蹿行等问题,从而陷入两难境地.老板要数据,你却导不出来,急死人了. 1.问题:我们原本要把如左图所示的数据库中的数据导出成他原本的样子,无奈成了右边的乱七八糟的东西: 2.解决: a:原本怎么导出为csv的还是怎么导: b:选中你导出的csv文件,右键选择打开
-
快速解决mysql深分页问题
目录 背景 概括 1.limit深分页问题描述 2.sql慢原因分析 聚簇索引和非聚簇索引 常见解决方案 通过子查询优化 标签记录法 方案对比 实战案例 总结 背景 日常需求开发过程中,相信大家对于limit一定不会陌生,但是使用limit时,当偏移量(offset)非常大时,会发现查询效率越来越慢.一开始limit 2000时,可能200ms,就能查询出需要的到数据,但是当limit 4000 offset 100000时,会发现它的查询效率已经需要1S左右,那要是更大的时候呢,只会越来越慢.
-
解决MySQL读写分离导致insert后select不到数据的问题
MySQL设置独写分离,在代码中按照如下写法,可能会出现问题 // 先录入 this.insert(obj); // 再查询 Object res = this.selectById(obj.getId()); res: null; 线上的一个坑,做了读写分离以后,有一个场景因为想方法复用,只传入一个ID就好,直接去库里查出一个对象再做后续处理,结果查不出来,事务隔离级别各种也都排查了,最后发现是读写分离的问题,所以换个思路去实现吧. 补充知识:MySQL INSERT插入条件判断:如果不存在则
-
解决MySQL安装重装时出现could not start the service mysql error:0问题的方法
当各位在安装.重装时出现could not start the service mysql error:0 原因: 卸载mysql时并没有完全删除相关文件和服务,需要手动清除. 安装到最后一步execute时不能启动服务的解决方法: 首先,在管理工具->服务里面将MySQL的服务给停止(有的是没有安装成功,有这个服务,但是已经停止了的),win+R->cmd,打开命令提示符窗口,输入命令:sc delete mysql(查看服务,此时服务中已没有mysql),将已停的服务删除,卸载MySQL记
-
MySQL数据误删除的快速解决方法(MySQL闪回工具)
概述 Binlog2sql是一个Python开发开源的MySQL Binlog解析工具,能够将Binlog解析为原始的SQL,也支持将Binlog解析为回滚的SQL,去除主键的INSERT SQL,是DBA和运维人员数据恢复好帮手. 一.安装配置 1.1 用途 数据快速回滚(闪回) 主从切换后新master丢数据的修复 从binlog生成标准SQL,带来的衍生功能 支持MySQL5.6,5.7 1.2 安装 shell> git clone https://github.com/danfengc
-
MySQL中使用binlog时格式该如何选择
一.binlog的三种模式 1.statement level模式 每一条会修改数据的sql都会记录到master的bin-log中.slave在复制的时候sql进程会解析成和原来master端执行过的相同的sql来再次执行. 优点:statement level下的优点,首先就是解决了row level下的缺点,不需要记录每一行数据的变化,减少bin-log日志量,节约io,提高性能.因为他只需要记录在master上所执行的语句的细节,以及执行语句时候的上下文的信息. 缺点:由于它是记录的执行
-
pandas读取csv格式数据时header参数设置方法
目录 写在前面 参考文档 read_csv的header参数 header参数测试 思考 写在前面 使用pandas中read_csv读取csv数据时,对于有表头的数据,将header设置为空(None),会报错:pandas_libs\parsers.pyx in pandas._libs.parsers.raise_parser_error() ParserError: Error tokenizing data. C error: Expected 4 fields in line 2,
-
解决MySQL客户端输出窗口显示中文乱码问题的办法
最近发现,在MySQL的dos客户端输出窗口中查询表中的数据时,表中的中文数据都显示成乱码,如下图所示: 上网查了一下原因:之所以会显示乱码,就是因为MySQL客户端输出窗口显示中文时使用的字符编码不对造成的,可以使用如下的命令查看输出窗口使用的字符编码:show variables like 'char%'; 命令执行完成之后显示结果如下所示: 可以看到,现在是使用utf8字符编码来显示中文数据的,但是因为操作系统是中文操作系统,默认使用的字符集是GB2312,所以需要把输出窗口使用的字符编码
-
java实现批量导入Excel表格数据到数据库
本文是基于Apache poi类实现的批量导入读取Excel文件,所以要先引入Apache poi的依赖 <dependency> <groupId>org.apache.poi</groupId> <artifactId>poi</artifactId> <version>4.1.1</version> </dependency> <dependency> <groupId>org.a