PHP网页抓取之抓取百度贴吧邮箱数据代码分享
百度贴吧大家都经常逛,去逛百度贴吧的时候,经常会看到楼主分享一些资源,要求留下邮箱,楼主才给发。
对于一个热门的帖子,留下的邮箱数量是非常多的,楼主需要一个一个的去复制那些回复的邮箱,然后再粘贴发送邮件,不是被折磨死就是被累死。无聊至极写了一个抓取百度贴吧邮箱数据的程序,需要的拿走。
程序实现了一键抓取帖子全部邮箱和分页抓取邮箱两个功能,界面懒得做了,效果如下:
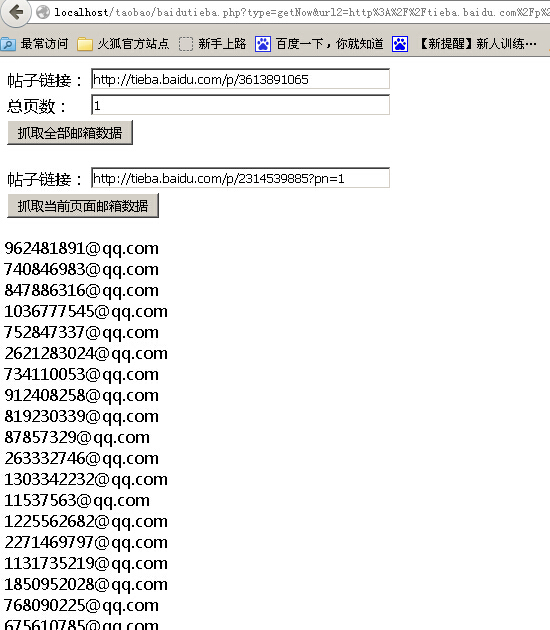
老规矩,直接贴源码
<?php
$url2="";
$page="";
if($_GET['url2']==""){
$url2="http://tieba.baidu.com/p/2314539885?pn=1";
}else{
$url2=$_GET['url2'];
}
if($_GET['page']==""){
$page="1";
}else{
$page=$_GET['page'];
}
?>
<form action="" method="get">
<input type="hidden" value="getAll" name="type" />
<table>
<tr>
<td>帖子链接:</td><td><input type="text" name="url" value="http://tieba.baidu.com/p/2314539885" style="width:300px;" /></td>
</tr>
<tr>
<td>总页数:</td><td><input type="text" name="page" style="width:300px;" value="<?php echo $page;?>" /></td>
</tr>
<tr>
<td colspan=2><input type="submit" value="抓取全部邮箱数据" /></td>
</tr>
</table>
</form>
<form action="" method="get">
<input type="hidden" value="getNow" name="type" />
<table>
<tr>
<td>帖子链接:</td><td><input type="text" name="url2" value="<?php echo $url2;?>" style="width:300px;" /></td>
</tr>
<tr>
<td colspan=2><input type="submit" value="抓取当前页面邮箱数据" /></td>
</tr>
</table>
</form>
<?php
if($_GET['type']!=""){
$counts=0;
if($_GET['type']=="getAll"){
$pages=$_GET['page'];
$url = $_GET['url'];
for($i=0;$i<$pages;$i++){
$ch2 = curl_init();
curl_setopt($ch2, CURLOPT_URL, $url);
curl_setopt($ch2, CURLOPT_FOLLOWLOCATION, TRUE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch2, CURLOPT_RETURNTRANSFER, TRUE);
$texts = curl_exec($ch2);
curl_close($ch2);
$dat=getEmail($texts);
for($j=0;$j<count($dat);$j++){
echo $dat[$j]."<br />";
$counts++;
}
}
}else if($_GET['type']=="getNow"){
$url = $_GET['url2'];
$ch2 = curl_init();
curl_setopt($ch2, CURLOPT_URL, $url);
curl_setopt($ch2, CURLOPT_FOLLOWLOCATION, TRUE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYHOST, FALSE);
curl_setopt($ch2, CURLOPT_SSL_VERIFYPEER, false);
curl_setopt($ch2, CURLOPT_RETURNTRANSFER, TRUE);
$texts = curl_exec($ch2);
curl_close($ch2);
$dat=getEmail($texts);
for($i=0;$i<count($dat);$i++){
echo $dat[$i]."<br />";
$counts++;
}
}
echo '<h2>共采集到数据:'.$counts.'条</h2>';
}
function getEmail($str){
$pattern = "/([a-z0-9\-_\.]+@[a-z0-9]+\.[a-z0-9\-_\.]+)/";
preg_match_all($pattern,$str,$emailArr);
return $emailArr[0];
}
?>
相关推荐
-

PHP抓取淘宝商品的用户晒单评论+图片+搜索商品列表实例
说起来做这个功能还真是一时好奇.前段时间在做一个淘客网站的时候,想到是否能抓取到淘宝商品的买家秀呢?经过一番折腾发现,淘宝商品用户评价信息是通过Ajax来调取的,通过嗅探网址发现,评论数据的请求接口是: https://rate.tmall.com/list_detail_rate.htm?itemId=524394294771&spuId=341564036&sellerId=100414600&order=3¤tPage=1&append=0&
-
PHP怎样用正则抓取页面中的网址
前言 链接也就是超级链接,是从一个元素(文字.图片.视频等)链接到另一个元素(文字.图片.视频等).网页中的链接一般有三种,一种是绝对URL超链接,也就是一个页面的完整路径:另一种是相对URL超链接,一般都链接到同一网站的其他页面:还有一种是页面内的超链接,这种一般链接到同一页面内的其他位置. 搞清楚了链接的种类,就知道要抓链接,主要还是绝对URL超链接和相对URL超链接.要写出正确的正则表达式,就必须要了解我们查找的对象的模式. 先说绝对链接,也叫作URL(Uniform Resource L
-
洪恩在线成语词典小偷程序php版
主要函数是file_get_contents,主程序分两段,跟我一起看过来吧(凡人博客原创代码,转载请注明). 复制代码 代码如下: function escape($str){ preg_match_all('/[\x80-\xff].|[\x01-\x7f]+/',$str,$r); $ar = $r[0]; foreach($ar as $k=>$v){ if(ord($v[0]) < 128) $ar[$k] = rawurlencode($v); else $ar[$k] = '%u
-
php下通过IP获取地理位置的代码(小偷程序)
复制代码 代码如下: function get_ip_place() { $ip=file_get_contents("http://fw.qq.com/ipaddress"); $ip=str_replace('"',' ',$ip); $ip2=explode("(",$ip); $a=substr($ip2[1],0,-2); $b=explode(",",$a); return $b; } 上面来自开源中国写的真XXX,新闻我都
-
分享PHP源码批量抓取远程网页图片并保存到本地的实现方法
做为一个仿站工作者,当遇到网站有版权时甚至加密的时候,WEBZIP也熄火,怎么扣取网页上的图片和背景图片呢.有时候,可能会想到用火狐,这款浏览器好像一个强大的BUG,文章有版权,屏蔽右键,火狐丝毫也不会被影响. 但是作为一个热爱php的开发者来说,更多的是喜欢自己动手.所以,我就写出了下面的一个源码,php远程抓取图片小程序.可以读取css文件并抓取css代码中的背景图片,下面这段代码也是针对抓取css中图片而编写的. <?php header("Content-Type: text/ht
-
利用php抓取蜘蛛爬虫痕迹的示例代码
前言 相信许多的站长.博主可能最关心的无非就是自己网站的收录情况,一般情况下我们可以通过查看空间服务器的日志文件来查看搜索引擎到底爬取了我们哪些个页面,不过,如果用php代码分析web日志中蜘蛛爬虫痕迹,是比较好又比较直观方便操作的!下面是示例代码,有需要的朋友们下面来一起看看吧. 示例代码 <?php //获取蜘蛛爬虫名或防采集 function isSpider(){ $bots = array( 'Google' => 'googlebot', 'Baidu' => 'baidus
-
PHP小偷程序的设计与实现方法详解
本文实例讲述了PHP小偷程序的设计与实现方法.分享给大家供大家参考,具体如下: 其实自己一直想做一个内涵图片的网站,以前的想法是做一个CMS,然后自己上传一些图片.. 开始真这么做的,没什么动力.之后就放弃了,后来研究了一个CURL.反正还是把这个想法实现比较好. 用PHP盗图,就好比:穿着袜子穿凉鞋一样.虽然没问题,但看着确实蛋疼. 我先说一下我对PHP小偷程序的设计,PHP不支持多线程,这样就只能分先后顺序来做了 获取到目标网站的HTML页面+解析HTML页面获取到图片存储的连接+用二进制方
-
一个图片地址分解程序(用于PHP小偷程序)
如题,返回一个数组,可以获得图片地址的base url,相对地址,名称等,具体见下例: <? error_reporting(E_ALL ^ E_NOTICE); $imgurl='http://files.jb51.net/file_images/article/201408/201408232212306.png'; $imgurl_dir='/img/2014/07/02/14520384.gif'; //echo getimg($imgurl,'./img'); var_dump(url
-
PHP通过CURL实现定时任务的图片抓取功能示例
本文实例讲述了PHP通过CURL实现定时任务的图片抓取功能.分享给大家供大家参考,具体如下: 下文为各位介绍一个PHP定时任务通过CURL图片的抓取例子,希望例子对大家帮助,基本思路就是通过一个URL连接,将所有图片的地址抓取下来,然后循环打开图片,利用文件操作函数下载下来,保存到本地,并且把图片的alt属性也抓取下来,最后将数据保存到自己数据库. 废话不多说,看程序就能明白了,其中,需要用到PHP定时任务和PHP的一个第三方插件simple_html_dom.php 的使用,参考simple_
-
PHP抓取HTTPS内容和错误处理的方法
问题 在研究Hacker News API的时候遇到一个HTTPS问题.因为所有的Hacker News API都是通过加密的HTTPS协议访问的,跟普通的HTTP协议不同,当使用PHP里的函数 file_get_contents() 来获取API里提供的数据时,出现错误 使用的代码是这样的: <?php $data = file_get_contents("/http://blog.it985.com/"); ?> 当运行上面的代码是遇到下面的错误提示: PHP Warn
-
php curl抓取网页的介绍和推广及使用CURL抓取淘宝页面集成方法
php的curl可以用来实现抓取网页,分析网页数据用, 简洁易用, 这里介绍其函数等就不详细描述, 放上代码看看: 只保留了其中几个主要的函数. 实现模拟登陆, 其中可能涉及到session捕获, 然后前后页面涉及参数提供形式. libcurl主要功能就是用不同的协议连接和沟通不同的服务器~也就是相当封装了的sock PHP 支持libcurl(允许你用不同的协议连接和沟通不同的服务器)., libcurl当前支持http, https, ftp, gopher, telnet, dict, f