SQLServer2005 中的几个统计技巧
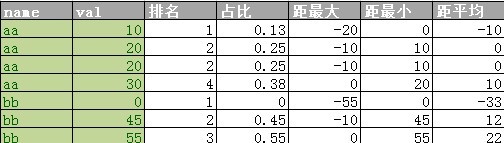
在SQLServer中我们可以用over子句中来代替子查询实现来提高效率,over子句除了排名函数之外也可以和聚合函数配合。实现代码如下:
代码如下:
use tempdb
go
if (object_id ('tb' ) is not null )
drop table tb
go
create table tb (name varchar (10 ), val int )
go
insert into tb
select 'aa' , 10
union all select 'aa' , 20
union all select 'aa' , 20
union all select 'aa' , 30
union all select 'bb' , 55
union all select 'bb' , 45
union all select 'bb' , 0
select *
, 排名 = rank ()over (partition by name order by val )
, 占比 = cast (val * 1.0 / sum (val )over (partition by name ) as decimal (2 , 2 ))
, 距最大 = val - max (val )over (partition by name )
, 距最小 = val - min (val )over (partition by name )
, 距平均 = val - avg (val )over (partition by name )
from tb
相关推荐
-
SQLSERVER语句的执行时间显示的统计结果是什么意思
在SQL语句调优的时候,大部分都会查看语句执行时间,究竟SQLSERVER显示出来的统计结果是什么意思? 下面看一下例子 比较简单的语句: 复制代码 代码如下: 1 SET STATISTICS TIME ON 2 USE [pratice] 3 GO 4 SELECT * FROM [dbo].[Orders] 结果: 复制代码 代码如下: SQL Server 分析和编译时间: CPU 时间 = 0 毫秒,占用时间 = 0 毫秒. SQL Server 执行时间: CPU 时间 = 0 毫秒
-
sqlserver 统计sql语句大全收藏
1.计算每个人的总成绩并排名 select name,sum(score) as allscore from stuscore group by name order by allscore 2.计算每个人的总成绩并排名 select distinct t1.name,t1.stuid,t2.allscore from stuscore t1,( select stuid,sum(score) as allscore from stuscore group by stuid)t2where t1
-

SQLserver 实现分组统计查询(按月、小时分组)
设置AccessCount字段可以根据需求在特定的时间范围内如果是相同IP访问就在AccessCount上累加. 复制代码 代码如下: Create table Counter ( CounterID int identity(1,1) not null, IP varchar(20), AccessDateTime datetime, AccessCount int ) 该表在这儿只是演示使用,所以只提供了最基本的字段 现在往表中插入几条记录 insert into Counter selec
-
如何统计全天各个时间段产品销量情况(sqlserver)
数据库环境:SQL SERVER 2005 现有一个产品销售实时表,表数据如下: 字段name是产品名称,字段type是销售类型,1表示售出,2表示退货,字段num是数量,字段ctime是操作时间. 要求: 在一行中统计24小时内所有货物的销售(售出,退货)数据,把日期考虑在内. 分析: 这实际上是行转列的一个应用,在进行行转列之前,需要补全24小时的所有数据.补全数据可以通过系统的数字辅助表 spt_values来实现,进行行转列时,根据type和处理后的ctime分组即可. 1.建表,导入数
-
SQLSERVER收集语句运行的统计信息并进行分析
对于语句的运行,除了执行计划本身,还有一些其他因素要考虑,例如语句的编译时间.执行时间.做了多少次磁盘读等. 如果DBA能够把问题语句单独测试运行,可以在运行前打开下面这三个开关,收集语句运行的统计信息. 这些信息对分析问题很有价值. 复制代码 代码如下: SET STATISTICS TIME ON SET STATISTICS IO ON SET STATISTICS PROFILE ON SET STATISTICS TIME ON ----------------------------
-
SQLServer2005 中的几个统计技巧
在SQLServer中我们可以用over子句中来代替子查询实现来提高效率,over子句除了排名函数之外也可以和聚合函数配合.实现代码如下: 复制代码 代码如下: use tempdb go if (object_id ('tb' ) is not null ) drop table tb go create table tb (name varchar (10 ), val int ) go insert into tb select 'aa' , 10 union all select 'a
-
Oracle数据库中SQL语句的优化技巧
在SQL语句优化过程中,我们经常会用到hint,现总结一下在SQL优化过程中常见Oracle HINT的用法: 1. /*+ALL_ROWS*/ 表明对语句块选择基于开销的优化方法,并获得最佳吞吐量,使资源消耗最小化. 例如: SELECT /*+ALL+_ROWS*/ EMP_NO,EMP_NAM,DAT_IN FROM BSEMPMS WHERE EMP_NO='SCOTT'; 2. /*+FIRST_ROWS*/ 表明对语句块选择基于开销的优化方法,并获得最佳响应时间,使资源消耗最小化.
-
整理Linux中字符串的相关操作技巧
我们在linux的操作中经常会对文件中的字符串进行替换.统计等操作,我们现在来做一次整理,如有错误请批评指正. 统计字符串个数 grep -c str filename grep -o str filename |wc -l 替换字符串 替换当前行匹配字符串 :s/oldStr/newStr 替换当前文件中所有匹配字符串 :%s/原字符串/替换字符串/gg 批量替换字符串 sed -i "s/查找字段/替换字段/g" grep 查找字段 -rl 路径 -rl 表示所有子目录 sed -
-
在DB2中提高INSERT性能的技巧(1)
正在看的db2教程是:在DB2中提高INSERT性能的技巧(1). INSERT 处理过程概述 首先让我们快速地看看插入一行时的处理步骤.这些步骤中的每一步都有优化的潜力,对此我们在后面会一一讨论. 在客户机准备 语句.对于动态 SQL,在语句执行前就要做这一步,此处的性能是很重要的:对于静态 SQL,这一步的性能实际上关系不大,因为语句的准备是事先完成的. 在客户机,将要插入的行的各个 列值组装起来,发送到 DB2 服务器. DB2 服务器确定将这一行插入到哪一页中. DB2 在 用于该页的缓
-
SQLServer 2008 R2中使用Cross apply统计最新数据和最近数据
使用 APPLY 运算符可以为实现查询操作的外部表表达式返回的每个行调用表值函数.表值函数作为右输入,外部表表达式作为左输入.通过对右输入求值来获得左输入每一行的计算结果,生成的行被组合起来作为最终输出.APPLY 运算符生成的列的列表是左输入中的列集,后跟右输入返回的列的列表. 注意:若要使用 APPLY,数据库兼容级别必须至少为 90. APPLY 有两种形式:CROSS APPLY 和 OUTER APPLY.CROSS APPLY 仅返回外部表中通过表值函数生成结果集的行.OUTER A
-
Android中ListView Item布局优化技巧
本文实例讲述了Android中ListView Item布局优化技巧.分享给大家供大家参考,具体如下: 之前一直都不知道ListView有多种布局的优化方法,只能通过隐藏来实现,自己也知道效率肯定是很低的,但是也不知道有什么方法,这些天又查了一些资料,然后知道 其实google早就帮我们想好了优化方案了. 假设你的ListView Item有三种布局样式的可能:就比如很简单的显示一行字,要靠左,居中,靠右. 这时我们就可以在BaseAdapter里面重写两个方法: private static
-
Python中字符串的常见操作技巧总结
本文实例总结了Python中字符串的常见操作技巧.分享给大家供大家参考,具体如下: 反转一个字符串 >>> S = 'abcdefghijklmnop' >>> S[::-1] 'ponmlkjihgfedcba' 这种用法叫做three-limit slices 除此之外,还可以使用slice对象,例如 >>> 'spam'[slice(None, None, -1)] >>> unicode码与字符(single-characte
-
SQLite在C#中的安装与操作技巧
SQLite 介绍 SQLite,是一款轻型的数据库,用于本地的数据储存. 先说说优点,它占用资源非常的低,在嵌入式设备中需要几百K的内存就够了:作为轻量级数据库,他的处理速度也足够快:支持的的容量级别为T级:独立: 没有额外依赖:开源:支持多种语言: 我的用途 在项目开发中,需要做一次数据数据同步.因为数据库实时数据的同步,需要记录更新时间,系统日志等等数据:当然,你也可以选择写ini和xml等等配置文件来解决,但是都如数据库可读性高不是. 安装 1. 引用 .NET 驱动 http://sy
-
Python 中 list 的各项操作技巧
最近在学习 python 语言.大致学习了 python 的基础语法.觉得 python 在数据处理中的地位和它的 list 操作密不可分. 特学习了相关的基础操作并在这里做下笔记. ''' Python --version Python 2.7.11 Quote : https://docs.python.org/2/tutorial/datastructures.html#more-on-lists Add by camel97 2017-04 ''' list.append(x) #在列表
-
一次性压缩Sqlserver2005中所有库日志的存储过程
有没有办法更快一点? 有没有办法一次性收缩所有数据库? 复制代码 代码如下: alter database 数据库名 set recovery simple go dbcc shrinkdatabase (数据库名) go alter database 数据库名 set recovery full go 目前也有压缩日志的工具,一个B/S界面形式的操作压缩数据库的,就是在选择数据库的时候老需要重新去选择具体的库,而且数据库数量很大的时候,有些库被压缩了,并没有自动排序; 目前需要的是被压缩后的数