关于pytorch中网络loss传播和参数更新的理解
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇。
TensorFlow: 228--->266
Keras: 42--->56
Pytorch: 87--->252
在使用pytorch中,自己有一些思考,如下:
1. loss计算和反向传播
import torch.nn as nn criterion = nn.MSELoss().cuda() output = model(input) loss = criterion(output, target) loss.backward()
通过定义损失函数:criterion,然后通过计算网络真实输出和真实标签之间的误差,得到网络的损失值:loss;
最后通过loss.backward()完成误差的反向传播,通过pytorch的内在机制完成自动求导得到每个参数的梯度。
需要注意,在机器学习或者深度学习中,我们需要通过修改参数使得损失函数最小化或最大化,一般是通过梯度进行网络模型的参数更新,通过loss的计算和误差反向传播,我们得到网络中,每个参数的梯度值,后面我们再通过优化算法进行网络参数优化更新。
2. 网络参数更新
在更新网络参数时,我们需要选择一种调整模型参数更新的策略,即优化算法。
优化算法中,简单的有一阶优化算法:
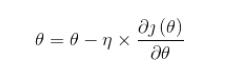
其中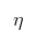 就是通常说的学习率,
就是通常说的学习率,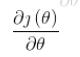 是函数的梯度;
是函数的梯度;
自己的理解是,对于复杂的优化算法,基本原理也是这样的,不过计算更加复杂。
在pytorch中,torch.optim是一个实现各种优化算法的包,可以直接通过这个包进行调用。
optimizer = torch.optim.Adam(model.parameters(), lr=0.01)
注意:
1)在前面部分1中,已经通过loss的反向传播得到了每个参数的梯度,然后再本部分通过定义优化器(优化算法),确定了网络更新的方式,在上述代码中,我们将模型的需要更新的参数传入优化器。
2)注意优化器,即optimizer中,传入的模型更新的参数,对于网络中有多个模型的网络,我们可以选择需要更新的网络参数进行输入即可,上述代码,只会更新model中的模型参数。对于需要更新多个模型的参数的情况,可以参考以下代码:
optimizer = torch.optim.Adam([{'params': model.parameters()}, {'params': gru.parameters()}], lr=0.01) 3) 在优化前需要先将梯度归零,即optimizer.zeros()。
3. loss计算和参数更新
import torch.nn as nn import torch criterion = nn.MSELoss().cuda() optimizer = torch.optim.Adam(model.parameters(), lr=0.01) output = model(input) loss = criterion(output, target) optimizer.zero_grad() # 将所有参数的梯度都置零 loss.backward() # 误差反向传播计算参数梯度 optimizer.step() # 通过梯度做一步参数更新
以上这篇关于pytorch中网络loss传播和参数更新的理解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
pytorch 在网络中添加可训练参数,修改预训练权重文件的方法
实践中,针对不同的任务需求,我们经常会在现成的网络结构上做一定的修改来实现特定的目的. 假如我们现在有一个简单的两层感知机网络: # -*- coding: utf-8 -*- import torch from torch.autograd import Variable import torch.optim as optim x = Variable(torch.FloatTensor([1, 2, 3])).cuda() y = Variable(torch.FloatTensor([4,
-

详解Pytorch 使用Pytorch拟合多项式(多项式回归)
使用Pytorch来编写神经网络具有很多优势,比起Tensorflow,我认为Pytorch更加简单,结构更加清晰. 希望通过实战几个Pytorch的例子,让大家熟悉Pytorch的使用方法,包括数据集创建,各种网络层结构的定义,以及前向传播与权重更新方式. 比如这里给出 很显然,这里我们只需要假定 这里我们只需要设置一个合适尺寸的全连接网络,根据不断迭代,求出最接近的参数即可. 但是这里需要思考一个问题,使用全连接网络结构是毫无疑问的,但是我们的输入与输出格式是什么样的呢? 只将一个x作为输入
-
关于pytorch中网络loss传播和参数更新的理解
相比于2018年,在ICLR2019提交论文中,提及不同框架的论文数量发生了极大变化,网友发现,提及tensorflow的论文数量从2018年的228篇略微提升到了266篇,keras从42提升到56,但是pytorch的数量从87篇提升到了252篇. TensorFlow: 228--->266 Keras: 42--->56 Pytorch: 87--->252 在使用pytorch中,自己有一些思考,如下: 1. loss计算和反向传播 import torch.nn as nn
-
在pytorch中如何查看模型model参数parameters
目录 pytorch查看模型model参数parameters pytorch查看模型参数总结 1:DNN_printer 2:parameters 3:get_model_complexity_info() 4:torchstat pytorch查看模型model参数parameters 示例1:pytorch自带的faster r-cnn模型 import torch import torchvision model = torchvision.models.detection.faster
-
浅谈pytorch中的BN层的注意事项
最近修改一个代码的时候,当使用网络进行推理的时候,发现每次更改测试集的batch size大小竟然会导致推理结果不同,甚至产生错误结果,后来发现在网络中定义了BN层,BN层在训练过程中,会将一个Batch的中的数据转变成正太分布,在推理过程中使用训练过程中的参数对数据进行处理,然而网络并不知道你是在训练还是测试阶段,因此,需要手动的加上,需要在测试和训练阶段使用如下函数. model.train() or model.eval() BN类的定义见pytorch中文参考文档 补充知识:关于pyto
-
Pytorch实现将模型的所有参数的梯度清0
有两种方式直接把模型的参数梯度设成0: model.zero_grad() optimizer.zero_grad()#当optimizer=optim.Optimizer(model.parameters())时,两者等效 如果想要把某一Variable的梯度置为0,只需用以下语句: Variable.grad.data.zero_() 补充知识:PyTorch中在反向传播前为什么要手动将梯度清零?optimizer.zero_grad()的意义 optimizer.zero_grad()意思
-
PyTorch中的Variable变量详解
一.了解Variable 顾名思义,Variable就是 变量 的意思.实质上也就是可以变化的量,区别于int变量,它是一种可以变化的变量,这正好就符合了反向传播,参数更新的属性. 具体来说,在pytorch中的Variable就是一个存放会变化值的地理位置,里面的值会不停发生片花,就像一个装鸡蛋的篮子,鸡蛋数会不断发生变化.那谁是里面的鸡蛋呢,自然就是pytorch中的tensor了.(也就是说,pytorch都是有tensor计算的,而tensor里面的参数都是Variable的形式).如果
-
对PyTorch中inplace字段的全面理解
例如 torch.nn.ReLU(inplace=True) inplace=True 表示进行原地操作,对上一层传递下来的tensor直接进行修改,如x=x+3: inplace=False 表示新建一个变量存储操作结果,如y=x+3,x=y: inplace=True 可以节省运算内存,不用多存储变量. 补充:PyTorch中网络里面的inplace=True字段的意思 在例如nn.LeakyReLU(inplace=True)中的inplace字段是什么意思呢?有什么用? inplace=
-
PyTorch中view()与 reshape()的区别详析
目录 前言 一.PyTorch中tensor的存储方式 1.PyTorch张量存储的底层原理 2.PyTorch张量的步长(stride)属性 二.对“视图(view)”字眼的理解 三.view() 和reshape() 的比较 1.对 torch.Tensor.view() 的理解 2.对 torch.reshape() 的理解 四.总结 前言 总之,两者都是用来重塑tensor的shape的.view只适合对满足连续性条件(contiguous)的tensor进行操作,而reshape同时还
-
Pytorch训练网络过程中loss突然变为0的解决方案
问题 // loss 突然变成0 python train.py -b=8 INFO: Using device cpu INFO: Network: 1 input channels 7 output channels (classes) Bilinear upscaling INFO: Creating dataset with 868 examples INFO: Starting training: Epochs: 5 Batch size: 8 Learning rate: 0.001
-
pytorch中的自定义反向传播,求导实例
pytorch中自定义backward()函数.在图像处理过程中,我们有时候会使用自己定义的算法处理图像,这些算法多是基于numpy或者scipy等包. 那么如何将自定义算法的梯度加入到pytorch的计算图中,能使用Loss.backward()操作自动求导并优化呢.下面的代码展示了这个功能` import torch import numpy as np from PIL import Image from torch.autograd import gradcheck class Bicu