Win10系统下安装labelme及json文件批量转化方法
一、安装环境:windows10,anaconda3,python3.6
由于框架maskrcnn需要json数据集,在没安装labelme环境和跑深度学习之前,我安装的是anaconda3,其中pyhton是3.7版本的,经网上查阅资料,经过一番查找资料,发现,原来在2019年,TensorFlow还不支持python3.7,所以,迫于无奈,我只能乖乖把python的版本退回到3.6版本,具体步骤也很简单。就是打开anaconda prompt ,然后输入conda install python=3.6,然后等待提示(y/n),输入y,等待十几分钟,就会提示done,这样的话,就表示python3.7已经退回到python3.6了。(经过尝试这种方法在我这里没有行得通,可能跟网速有关,又尝试了另一种方法,有兴趣的可以尝试一下。)索性就把labelme安装到3.6中了。
二、安装过程:
1、管理员身份打开 anaconda prompt
2、输入命令:conda create --name=labelme python=3.6
3、输入命令:activate labelme
4、输入命令:pip install pyqt5,pip install pyside2(自己刚开始没有安装pyside2,运行 \anaconda安装目录\envs\labelme\Scripts\label_json_to_dataset.exe 会出现module "pyside"缺失错误)
5、输入命令:pip install labelme(由于网络原因或者库的地址,经常运行一半出现错误,不要气馁,多执行几次)
6、输入命令:labelme 即可打开labelme。如下:

安装完成后,需要使用再次启动labelme。则需要重新打开anaconda prompt,输入activate labelme,进入labelme环境。再输入命令: labelme 即可
三、用labelme标注完图片后,会生成json文件
以小猫为例:点击保存会在自己的图片目录下生成json文件

点点
生成的json文件并不能直接用,我们需要对他进行批处理才能成为maskrcnn需要的数据集,批量转化如下:
abelme标注工具再转化.json文件有一个缺陷,一次只能转换一个.json文件,然而深度学习的项目通常需要大量的数据,那么转换.json文件就是一个比较耗时的工作;因此,对labelme做出了改进,可以实现批量转换.json文件。
在安装Anaconda中找到json_to_dataset.py文件如果未找到可以在计算机中搜索,将该文件代码修改为以下代码:
import argparse
import base64
import json
import os
import os.path as osp
import warnings
import PIL.Image
import yaml
from labelme import utils
def main():
warnings.warn("This script is aimed to demonstrate how to convert the\n"
"JSON file to a single image dataset, and not to handle\n"
"multiple JSON files to generate a real-use dataset.")
parser = argparse.ArgumentParser()
parser.add_argument('json_file')
parser.add_argument('-o', '--out', default=None)
args = parser.parse_args()
json_file = args.json_file
alist = os.listdir(json_file)
for i in range(0,len(alist)):
path = os.path.join(json_file,alist[i])
data = json.load(open(path))
out_dir = osp.basename(path).replace('.', '_')
out_dir = osp.join(osp.dirname(path), out_dir)
if not osp.exists(out_dir):
os.mkdir(out_dir)
if data['imageData']:
imageData = data['imageData']
else:
imagePath = os.path.join(os.path.dirname(path), data['imagePath'])
with open(imagePath, 'rb') as f:
imageData = f.read()
imageData = base64.b64encode(imageData).decode('utf-8')
img = utils.img_b64_to_arr(imageData)
label_name_to_value = {'_background_': 0}
for shape in data['shapes']:
label_name = shape['label']
if label_name in label_name_to_value:
label_value = label_name_to_value[label_name]
else:
label_value = len(label_name_to_value)
label_name_to_value[label_name] = label_value
# label_values must be dense
label_values, label_names = [], []
for ln, lv in sorted(label_name_to_value.items(), key=lambda x: x[1]):
label_values.append(lv)
label_names.append(ln)
assert label_values == list(range(len(label_values)))
lbl = utils.shapes_to_label(img.shape, data['shapes'], label_name_to_value)
captions = ['{}: {}'.format(lv, ln)
for ln, lv in label_name_to_value.items()]
lbl_viz = utils.draw_label(lbl, img, captions)
PIL.Image.fromarray(img).save(osp.join(out_dir, 'img.png'))
utils.lblsave(osp.join(out_dir, 'label.png'), lbl)
PIL.Image.fromarray(lbl_viz).save(osp.join(out_dir, 'label_viz.png'))
with open(osp.join(out_dir, 'label_names.txt'), 'w') as f:
for lbl_name in label_names:
f.write(lbl_name + '\n')
warnings.warn('info.yaml is being replaced by label_names.txt')
info = dict(label_names=label_names)
with open(osp.join(out_dir, 'info.yaml'), 'w') as f:
yaml.safe_dump(info, f, default_flow_style=False)
print('Saved to: %s' % out_dir)
if __name__ == '__main__':
main()
操作命令如下图:

生成效果如下:每张图片生成五个文件 ,这就是我们所需要的
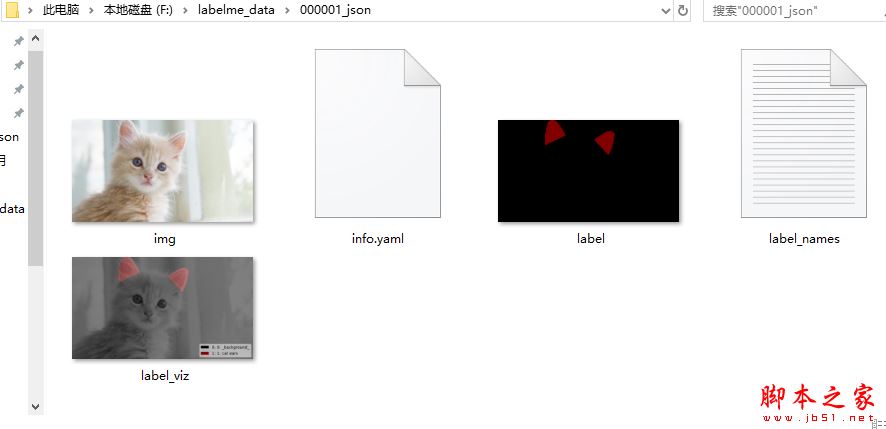
总结
以上所述是小编给大家介绍的Win10系统下安装labelme json文件批量转化方法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-

JS获取一个表单字段中多条数据并转化为json格式
如图需要获取下面两个li标签里面的数据,然后传给后台:而后台接收的数据格式是json的,所以需要把两个li里面的信息转化为以下格式的. {recieverName:小红,recieverPhone:12341234,recieverAddress:中国湖南},{recieverName:小明,recieverPhone:12345678,recieverAddress:中国上海} 代码如下: var recieverArr = []; //全局变量 var recieverMsg = {}; /
-
JS对象序列化成json数据和json数据转化为JS对象的代码
JS对象序列化成json数据: function Serialize(obj){ switch(obj.constructor){ case Object: var str = "{"; for(var o in obj){ str += o + ":" + Serialize(obj[o]) +","; } if(str.substr(str.length-1) == ",") str = str.substr(0,str.
-
JSON对象转化为字符串详解
序列化 定义 指将 JavaScript 值转化为 JSON 字符串的过程. JSON.stringify() 能够将 JavaScript 值转换成 JSON 字符串.JSON.stringify() 生成的字符串可以用 JSON.parse() 再还原成 JavaScript 值. 参数的含义 1)JSON.stringify(value[, replacer[, space]]) 2)value:必选参数.被变换的 JavaScript 值,一般是对象或数组. 3)replacer:可以省
-
java 将jsonarray 转化为对应键值的jsonobject方法
有时候我们再操作数据的时候,很多数据是jsonarry 格式的 如: [{"name":"测试数据","id":1},{"name":"测试数据2","id":2}] 这样的格式很类型表格数据类型.但是我们要取id 为1的name 这样我们就要先变量以便了.如果需要多次操作这样的类型,显得很麻烦. 这里的数据我们可以看出id 是唯一的.那么我们可以想办法将其转为jsonobject 这样
-
对python中xlsx,csv以及json文件的相互转化方法详解
最近需要各种转格式,这里对相关代码作一个记录,方便日后查询. xlsx文件转csv文件 import xlrd import csv def xlsx_to_csv(): workbook = xlrd.open_workbook('1.xlsx') table = workbook.sheet_by_index(0) with codecs.open('1.csv', 'w', encoding='utf-8') as f: write = csv.writer(f) for row_num
-
JSON字符串和JSON对象相互转化实例详解
本文实例讲述了JSON字符串和JSON对象相互转化的方法.分享给大家供大家参考,具体如下: 将json字符串转换为json对象的方法.在数据传输过程中,json是以文本,即字符串的形式传递的,而JS操作的是JSON对象,所以,JSON对象和JSON字符串之间的相互转换是关键 例如: JSON字符串: var str = '{ "name": "name1","sex": "m" }'; JSON对象: var obj = {
-
Win10系统下安装labelme及json文件批量转化方法
一.安装环境:windows10,anaconda3,python3.6 由于框架maskrcnn需要json数据集,在没安装labelme环境和跑深度学习之前,我安装的是anaconda3,其中pyhton是3.7版本的,经网上查阅资料,经过一番查找资料,发现,原来在2019年,TensorFlow还不支持python3.7,所以,迫于无奈,我只能乖乖把python的版本退回到3.6版本,具体步骤也很简单.就是打开anaconda prompt ,然后输入conda install pytho
-
在win10系统下安装Mysql 5.7.17图文教程
操作系统win10 MySQL为官网下载的64位zip解压缩Community版本. 因为想要在公司电脑上安装Mysql,于是到官网上下载了最新版本的Mysql-5.7.17,首先通过网上教程进行安装,解压,然后在C盘新建了一个Mysql0104目录(作为Mysql的安装目录),将解压过后Mysql-5.7.17文件夹中的内容拷贝至安装目录Mysql中. 文件内容如下: 之后按照网上攻略:以管理员身份运行命令行窗口,mysqld -install 安装mysql:这一步理论不会有什么问题 正常
-
win10系统下安装superset的步骤
superset是一个轻量级自助式BI框架,以优雅的界面和根据数据表动态生成数据为主要特点. 一. 环境 windows 10 64位 Python 3.7 二. 安装步骤 安装Python 建议安装Python 3.7 版本,Python官网:https://www.python.org/downloads/release/python-373/ 下载64位Python下载 python-3.7.3-amd64.exe,直接使用exe的安装包即可,安装过程中选中增加到环境变量. 安装VS201
-
Win10系统下安装编辑器之神(The God of Editor)Vim并且构建Python生态开发环境过程(2020年最新攻略)
目录 win10系统下配置python3开发环境 安装pathogen.vim插件(一个vim插件管理器) 众神殿内,依次坐着Editplus.Atom.Sublime.Vscode.JetBrains家族.Comodo等等一众编辑器界的大佬们,偌大的殿堂内几无立锥之地,然而在殿内的金漆雕龙宝座上,端坐着一位睥睨众生的王者,那就是被称之为编辑器之神的Vim,作为一个有着30余年历史的老牌神器,没有任何编辑器可以和它媲美,其时江湖有云:神编Vim不会玩,纵称大神也枉然.Vim在 1976 年发布,
-
Win10系统下MySQL8.0.16 压缩版下载与安装教程图解
官网下载: https://www.mysql.com 进入MySQL官网,选择download 选择社区 选择MySQL 社区 服务器 点击download下载 点击最下面不登陆下载 下载完成是这样一个压缩包 安装 解压文件 将bin文件的目录加入电脑系统环境配置path下 新建my.ini配置文件 [mysql] default-character-set = utf8 [mysqld] #端口 port = 3306 #mysql安装目录 basedir = E:/mysql-8.0.16
-
win10系统下python3安装及pip换源和使用教程
一.python3的安装 建议安装python3,python2在未来将不再维护. python官方下载地址 https://www.python.org/downloads/windows/ 选择 executable installer ,根据自己系统选择64位还是32位的安装包. 下载完成后双击运行 勾选Add Python 3.7 to PATH,方便在cmd命令行中调用,然后选择Customize installation. pip必选,其他根据自己的情况选择,无Pycharm等pyt
-
win10系统下 VS2019点云库PCL1.12.0的安装与配置教程
PCL简介:点云库全称是Point Cloud Library(PCL),是一个独立的.大规模的.开放的2D/3D图像和点云处理项目.PCL根据BSD许可条款发布的,是可以免费用于商用和研究使用. PCL相关网站: PCL官网.项目GitHub 项目开发需要用到PCL,下面记录一下我的PCL安装和配置过程. 参考博文:pcl1.8.0+vs2013环境配置(详细 1. 版本信息 win10系统 PCL:我安装的是PCL 1.12.0,需要下载两个文件: 下载地址: Releases · Poin
-
浅析Linux系统下安装wetty和使用说明
以下内容从wetty简介.环境准备.wetty安装.以及验证方面给大家分析,具体详情请看下文吧. 1. Wetty简介 Wetty是使用Node.js和websockets开发的一个开源Web-based SSH.关于Web-based SSH的更多资料请参考https://en.wikipedia.org/wiki/Web-based_SSH. 而wetty的资料请参考https://github.com/krishnasrinivas/wetty. 2. 环境准备 因为wetty是使用Nod
-
Win10环境下安装Mysql5.7.23问题及遇到的坑
看了很多教程,发现老是不能安装成功,经过一阵摸索,终于摸索出适合自己电脑的方法,遇到类似情况的朋友可以尝试一下该方法. 一.下载 1.官网下载网址:https://dev.mysql.com/downloads/mysql/ ,根据你的系统(32位或者64位)选择后缀是ZIP Archive的压缩包下载到本地.(MySQL分为安装版和解压版.为了以后MySQL出问题想重装时的各种不必要的麻烦,推荐解压版MySQL) 2.或者百度云下载:链接: https://pan.baidu.com/s/13
-
Win10 系统下VisualStudio2019 配置点云库 PCL1.11.0的图文教程
一.下载PCL1.11.0 Github下载地址:https://github.com/PointCloudLibrary/pcl/releases 下载红框内的两个文件 二.安装PCL1.11.0 2.1 安装"PCL-1.11.0-AllInOne-msvc2019-win64.exe". (1)选择第二个,自动添加系统变量 (2)安装路径选择D盘,系统会自动新建PCL 1.11.0文件夹. 2.2 安装完成之后打开文件夹 D:\PCL 1.11.0\3rdParty\OpenNI