详解Python3 pandas.merge用法
摘要
数据分析与建模的时候大部分时间在数据准备上,包括对数据的加载、清理、转换以及重塑。pandas提供了一组高级的、灵活的、高效的核心函数,能够轻松的将数据规整化。这节主要对pandas合并数据集的merge函数进行详解。(用过SQL或其他关系型数据库的可能会对这个方法比较熟悉。)码字不易,喜欢请点赞!!!
1.merge函数的参数一览表


2.创建两个DataFrame
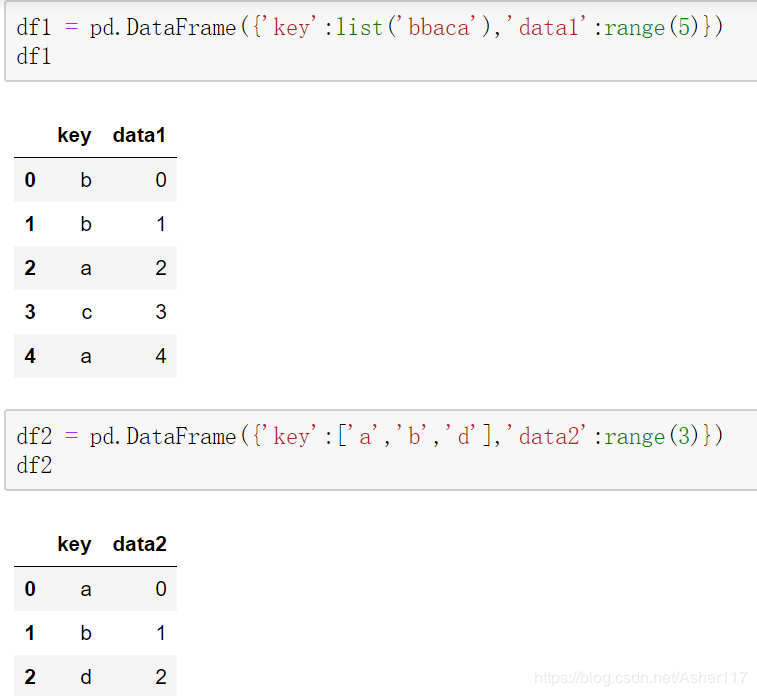
3.pd.merge()方法设置连接字段。
默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于on=‘key'。
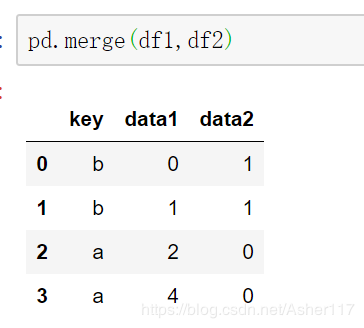
也可以显示的设置on=‘key',这里也推荐这么做。

当两边合并字段不同时,可以使用left_on和right_on参数设置合并字段。当然这里合并字段都是key所以left_on和right_on参数值都是key。
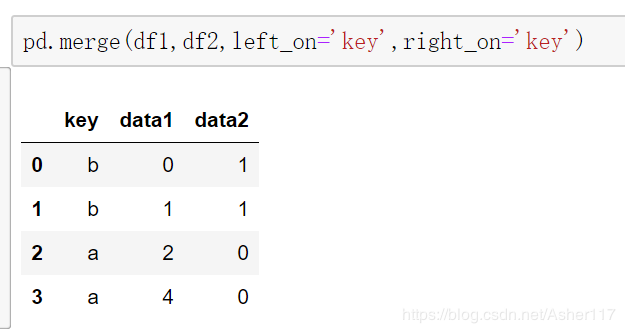
4.pd.merge()方法设置连接方法。
主要包括inner(内连接)、outer(外链接)、left(左连接)、right(右连接)。
参数how默认值是inner内连接,上面的都是采用内连接,连接两边都有的值。
当采用outer外连接时,会取并集,并用NaN填充。
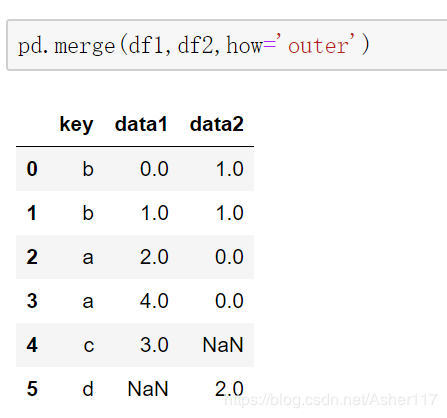
外连接其实左连接和右连接的并集。左连接是左侧DataFrame取全部数据,右侧DataFrame匹配左侧DataFrame。(右连接right和左连接类似)

5.pd.merge()方法索引连接,以及重复列名命名。
pd.merge()方法可以通过设置left_index或者right_index的值为True来使用索引连接,例如这里df1使用data1当连接关键字,而df2使用索引当连接关键字。
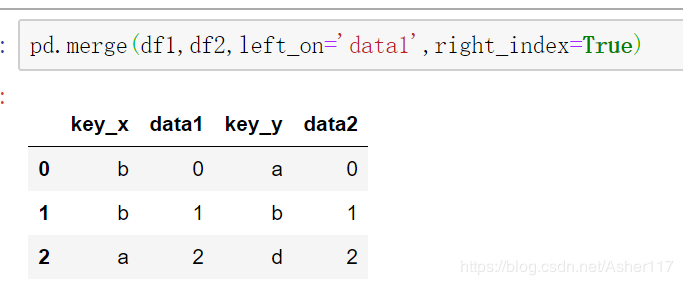
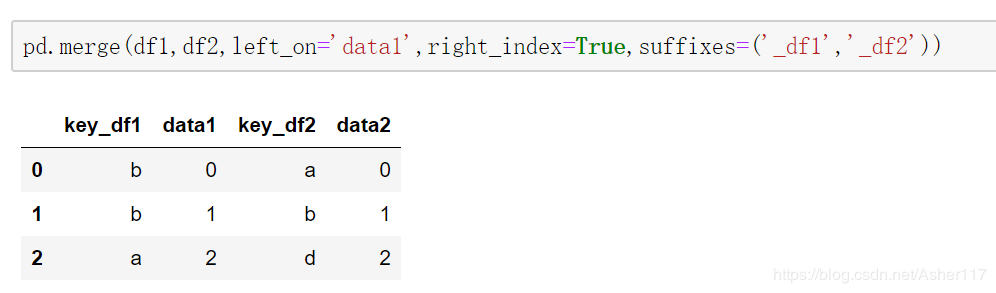
从上面可以发现两个DataFrame中都有key列,merge合并之后,pandas会自动在后面加上(_x,_y)来区分,我们也可以通过设置suffixes来设置名字。
总结
以上所述是小编给大家介绍的详解Python3 pandas.merge用法,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
python3 pandas 读取MySQL数据和插入的实例
python 代码如下: # -*- coding:utf-8 -*- import pandas as pd import pymysql import sys from sqlalchemy import create_engine def read_mysql_and_insert(): try: conn = pymysql.connect(host='localhost',user='user1',password='123456',db='test',charset='utf8')
-
Python3.5 Pandas模块缺失值处理和层次索引实例详解
本文实例讲述了Python3.5 Pandas模块缺失值处理和层次索引.分享给大家供大家参考,具体如下: 1.pandas缺失值处理 import numpy as np import pandas as pd from pandas import Series,DataFrame df3 = DataFrame([ ["Tom",np.nan,456.67,"M"], ["Merry",34,345.56,np.nan], [np.nan,np
-
Python3.5 Pandas模块之DataFrame用法实例分析
本文实例讲述了Python3.5 Pandas模块之DataFrame用法.分享给大家供大家参考,具体如下: 1.DataFrame的创建 (1)通过二维数组方式创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu import numpy as np import pandas as pd from pandas import Series,DataFrame #1.DataFrame通过二维数组创建 pr
-
Python3.5 Pandas模块之Series用法实例分析
本文实例讲述了Python3.5 Pandas模块之Series用法.分享给大家供大家参考,具体如下: 1.Pandas模块引入与基本数据结构 2.Series的创建 #!/usr/bin/env python # -*- coding:utf-8 -*- # Author:ZhengzhengLiu #模块引入 import numpy as np import pandas as pd from pandas import Series,DataFrame #1.Series通过numpy一
-
python3使用pandas获取股票数据的方法
如下所示: from pandas_datareader import data, wb from datetime import datetime import matplotlib.pyplot as plt end = datetime.now() start = datetime(end.year - 1, end.month, end.day) alibaba = data.DataReader('BABA', 'yahoo', start, end) alibaba['Adj Clo
-
Python3使用pandas模块读写excel操作示例
本文实例讲述了Python3使用pandas模块读写excel操作.分享给大家供大家参考,具体如下: 前言 Python Data Analysis Library 或 pandas 是基于NumPy 的一种工具,该工具是为了解决数据分析任务而创建的.Pandas 纳入了大量库和一些标准的数据模型,提供了高效地操作大型数据集所需的工具,能使我们快速便捷地处理数据.本文介绍如何用pandas读写excel. 1. 读取excel 读取excel主要通过read_excel函数实现,除了pandas
-
详解Python3 pandas.merge用法
摘要 数据分析与建模的时候大部分时间在数据准备上,包括对数据的加载.清理.转换以及重塑.pandas提供了一组高级的.灵活的.高效的核心函数,能够轻松的将数据规整化.这节主要对pandas合并数据集的merge函数进行详解.(用过SQL或其他关系型数据库的可能会对这个方法比较熟悉.)码字不易,喜欢请点赞!!! 1.merge函数的参数一览表 2.创建两个DataFrame 3.pd.merge()方法设置连接字段. 默认参数how是inner内连接,并且会按照相同的字段key进行合并,即等价于o
-
详解Python3 pickle模块用法
pickle(python3.x)和cPickle(python2.x的模块)相当于java的序列化和反序列化操作. 常采用下面的方式使用: import pickle pickle.dump(obj,f) pickle.dumps(obj,f) pickle.load(f) pickle.loads(f) 使用pickle模块你可以把Python对象直接保存到文件,而不需要把他们转化为字符串,也不用底层的文件访问操作把它们写入到一个二进制文件里. pickle模块会创建一个python语言专用
-

详解利用Pandas求解两个DataFrame的差集,交集,并集
目录 模拟数据 差集 方法1:concat + drop_duplicates 方法2:append + drop_duplicates 交集 方法1:merge 方法2:concat + duplicated + loc 方法3:concat + groupby + query 并集 方法1:concat + drop_duplicates 方法2:append + drop_duplicates 方法3:merge 大家好,我是Peter~ 本文讲解的是如何利用Pandas函数求解两个Dat
-
linux 详解useradd 命令基本用法
linux 详解useradd 命令基本用法 概要: 在 Linux 中 useradd 是个很基本的命令,但是使用起来却很不直观.以至于在 Ubuntu 中居然添加了一个 adduser 命令来简化添加用户的操作.本文主要描述笔者在学习使用 useradd 命令时的一些测试结果. 说明:本文中的所有试验都是在 Ubuntu14.04 上完成. 功能 在Linux中 useradd 命令用来创建或更新用户信息. useradd 命令属于比较难用的命令 (low level utility for
-
详解Python3 中hasattr()、getattr()、setattr()、delattr()函数及示例代码数
hasattr()函数 hasattr()函数用于判断是否包含对应的属性 语法: hasattr(object,name) 参数: object--对象 name--字符串,属性名 返回值: 如果对象有该属性返回True,否则返回False 示例: class People: country='China' def __init__(self,name): self.name=name def people_info(self): print('%s is xxx' %(self.name))
-
示例详解Python3 or Python2 两者之间的差异
每门编程语言在发布更新之后,主要版本之间都会发生很大的变化. 在本文中,Vinodh Kumar 通过示例解释了 Python 2 和 Python 3 之间的一些重大差异,以帮助说明语言的变化. 本教程主要介绍内容: 表达式 Print 选项 Unequal 操作 Range 自动迁移 性能问题 主要的内部事务更改 1.表达式 在 Python 2 中为获得计算表达式,你会键入: 但在 Python 3 中,你会键入: 因此,无论我们输入什么,值都会分配给 2 和 3 中的变量 x.当在 Py
-
详解Sed命令的用法与正则表达式元字符
sed命令用法 sed是一种流编辑器,它是文本处理中非常有用的工具,能够完美的配合正则表达式使用,功能不同凡响.处理时,把当前处理的行存储在临时缓冲区中,称为『模式空间』(pattern space),接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕.接着处理下一行,这样不断重复,直到文件末尾.文件内容并没有改变,除非你使用重定向存储输出.sed主要用来自动编辑一个或多个文件,简化对文件的反复操作,编写转换程序等. 1.简介 sed是非交互式的编辑器.它不会修改文件,除非使
-
对sklearn的使用之数据集的拆分与训练详解(python3.6)
研修课上讲了两个例子,融合一下. 主要演示大致的过程: 导入->拆分->训练->模型报告 以及几个重要问题: ①标签二值化 ②网格搜索法调参 ③k折交叉验证 ④增加噪声特征(之前涉及) from sklearn import datasets #从cross_validation导入会出现warning,说已弃用 from sklearn.model_selection import train-test_split from sklearn.grid_search import Gri
-
详解Python3中的 input() 函数
一.知识介绍: 1.input() 函数,接收任意输入,将所有输入默认为字符串处理,并返回字符串类型: 2.可以用作文本输入,如用户名,密码框的值输入: 3.语法:input("提示信息:") . 二.运用演示: 1.接收任意输入,并返回字符串类型: >>>height = input("输入身高:") #运行 输入身高: 170 #输入整数170 >>> type(a)
-
Node.js API详解之 console模块用法详解
本文实例讲述了Node.js API详解之 console模块用法.分享给大家供大家参考,具体如下: console模块简介 说明: console 模块提供了一个简单的调试控制台,类似于 Web 浏览器提供的 JavaScript 控制台. console 模块导出了两个特定的组件: 一个 Console 类,包含 console.log() . console.error() 和 console.warn() 等方法,可以被用于写入到任何 Node.js 流. 一个全局的 console 实