我是如何用2个Unix命令给MariaDB SQL提速的
译者 | 薛命灯
我试图在 MariaDB(MySQL)上运行一个简单的连接查询,但性能简直糟糕透了。下面将介绍我是如何通过两个简单的 Unix 命令,将查询时间从 380 小时降到 12 小时以下的。
下面就是这个查询,它是 GHTorrent 分析的一部分,我使用了关系在线分析处理框架 simple-rolap 来实现这个分析。
select distinct project_commits.project_id, date_format(created_at, ‘%x%v1') as week_commit from project_commits left join commits on project_commits.commit_id = commits.id;
两个连接字段都有索引。不过,MariaDB 是通过对 project_commits 进行全表扫描和对 commits 进行索引查找来实现连接的。这可以从 EXPLAIN 的输出看出来。
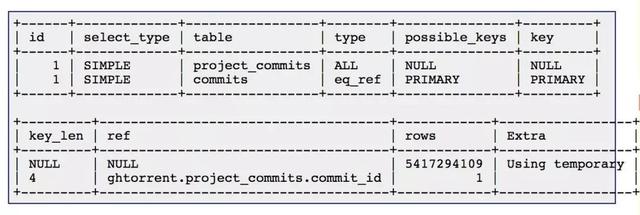
这两个表中的记录比较多:project_commits 有 50 亿行记录,commits 有 8.47 亿行记录。服务器的内存比较小,只有 16GB。所以很可能是因为内存放不下那么大的索引,需要读取磁盘,因此严重影响到了性能。从 pmonitor 对临时表的分析结果来看,这个查询已经运行半天了,还需要 373 个小时才能运行完。
/home/mysql/ghtorrent/project_commits#P#p0.MYD 6.68% ETA 373:38:11
在我看来,这个太过分了,因为排序合并连接(sort-merge join)所需的 I/O 时间应该要比预计的执行时间要低一个数量级。我在 dba.stackexchange.com 上寻求帮助,有人给出了一些建议让我尝试,但我没有信心它们能够解决我的问题。我尝试了第一个建议,结果并不乐观。尝试每个建议都需要至少半天的时间,后来,我决定采用一种我认为可以有效解决这个问题的办法。
我将这两个表导出到文件中,使用 Unix 的 join 命令将它们连接在一起,将结果传给 uniq,把重复的行移除掉,然后将结果导回到数据库。导入过程(包括重建索引)从 20:41 开始,到第二天的 9:53 结束。以下是具体操作步骤。
1. 将数据库表导出为文本文件
我先导出连接两个表需要用到的字段,并按照连接字段进行排序。为了确保排序顺序与 Unix 工具的排序顺序兼容,我将字段转换为字符类型。
我将以下 SQL 查询的输出保存到文件 commits_week.txt 中。
select cast(id as char) as cid, date_format(created_at, ‘%x%v1') as week_commit from commits order by cid;
然后将以下 SQL 查询的输出保存到 project_commits.txt 文件中:
select cast(commit_id as char) as cid, project_id from project_commits order by cid;
这样就生成了以下两个文件。
-rw-r–r– 1 dds dds 15G Aug 4 21:09 commits_week.txt
-rw-r–r– 1 dds dds 93G Aug 5 00:36 project_commits.txt
为了避免内存不足,我使用 –quick 选项来运行 mysql 客户端,否则客户端会在输出结果之前尝试收集所有的记录。
2. 使用 Unix 命令行工具处理文件
接下来,我使用 Unix 的 join 命令来连接这两个文本文件。这个命令线性扫描两个文件,并将第一个字段相同的记录组合在一起。由于文件中的记录已经排好序,因此整个过程完成得很快,几乎就是 I/O 的速度。我还将连接的结果传给 uniq,用以消除重复记录,这就解决了原始查询中的 distinct 问题。同样,在已经排好序的输出结果上,可以通过简单的线性扫描完成去重。
这是我运行的 Unix 命令。
join commits_week.txt project_commits.txt | uniq >joined_commits.txt
经过一个小时的处理,我得到了想要的结果。
-rw-r–r– 1 dds dds 133G Aug 5 01:40 joined_commits.txt
3. 将文本文件导回数据库
最后,我将文本文件导回数据库。
create table half_life.week_commits_all ( project_id INT(11) not null, week_commit CHAR(7)) ENGINE=MyISAM; load data local infile ‘joined_commits.txt' into table half_life.week_commits_all fields terminated by ‘ ‘;
结语
理想情况下,MariaDB 应该支持排序合并连接,并且在预测到备用策略的运行时间过长时,优化器应该使用排序合并连接。但在此之前,使用 70 年代设计的 Unix 命令就可以解决这个问题。
相关推荐
-
我是如何用2个Unix命令给MariaDB SQL提速的
译者 | 薛命灯 我试图在 MariaDB(MySQL)上运行一个简单的连接查询,但性能简直糟糕透了.下面将介绍我是如何通过两个简单的 Unix 命令,将查询时间从 380 小时降到 12 小时以下的. 下面就是这个查询,它是 GHTorrent 分析的一部分,我使用了关系在线分析处理框架 simple-rolap 来实现这个分析. select distinct project_commits.project_id, date_format(created_at, '%x%v1') as we
-
几个有用的unix命令快捷键整理
几个有用的unix命令快捷键 1.!$ bash或者zsh中表示上一个命令的最后一个参数,比如这里的!$表示的是file-b,那么就很方便的查看file-b的文件内容: 复制代码 代码如下: $ cp file-a file-b $ vim !$ 2.grep -ri -r表示递归查找,在所有子目录中查找,i表示大小写敏感: 比如$ grep */*/*/* 我们就可以替换为grep -r 3.cd - 这个会返回上一次的目录 复制代码 代码如下: [/usr/share/fonts/dejav
-

浅谈我是如何用redis做实时订阅推送的
前阵子开发了公司领劵中心的项目,这个项目是以redis作为关键技术落地的. 先说一下领劵中心的项目吧,这个项目就类似京东app的领劵中心,当然图是截取京东的,公司的就不截了... 其中有一个功能叫做领劵的订阅推送.什么是领劵的订阅推送?就是用户订阅了该劵的推送,在可领取前的一分钟就要把提醒信息推送到用户的app中.本来这个订阅功能应该是消息中心那边做的,但他们说这个短时间内做不了.所以让我这个负责优惠劵的做了-.-!.具体方案就是到具体的推送时间点了,coupon系统调用消息中心的推送接口,把信
-
MySQL从命令行导入SQL脚本时出现中文乱码的解决方法
本文实例讲述了MySQL从命令行导入SQL脚本时出现中文乱码的解决方法.分享给大家供大家参考,具体如下: 在图形界面管理工具 MySql Query Browser中打开脚本(脚本包括建库.建表.添加数据),并执行,不会有任何问题:但是使用mysql命令行工具执行建库脚本时,添加数据中如果包含中文,存入的数据就是乱码或是???... 解决方法1:在MySql安装目录下找到my.ini,将[mysql]下的default-character-set=latin1改为default-characte
-
Mysql命令行导入sql数据的代码
我的个人实践是:phpmyadmin 导出 utf-8 的 insert 模式的 abc.sql ftp abc.sql 到服务器 ssh 到服务器 mysql -u abc -p use KKK(数据库名,如果没有就 create database KKK) set names 'utf8' source abc.sql 注意:我看到 set character set utf8; 的说法,那样不行,中文乱码. 1.首先在命令行控制台中打开mysql 或许命令的如下: mysql -u roo
-
Mysql命令行导入sql数据
我的个人实践是:phpmyadmin 导出 utf-8 的 insert 模式的 abc.sql ftp abc.sql 到服务器 ssh 到服务器 mysql -u abc -p use KKK(数据库名,如果没有就 create database KKK) set names 'utf8' source abc.sql 注意:我看到 set character set utf8; 的说法,那样不行,中文乱码. 1.首先在命令行控制台中打开mysql 或许命令的如下: mysql -u roo
-
在postgresql中通过命令行执行sql文件
通过命令行执行初始化sql脚本是比较常见的需求,命令行下执行如下操作即可: 若是执行的命名只是创建用户,编辑用户,创建数据库的话可以不指定-d参数. psql -U username -d myDataBase -a -f init.sql 如果是远程数据库加入-h参数指定主机地址即可 psql -h host -U username -d myDataBase -a -f init.sql 补充:PostgreSQL操作-psql基本命令 一.建立数据库连接 接入PostgreSQL数据库:
-
网络基础版各种命令行集锦
Switching 命令大全 Switching 命令大全 1. 在基于IOS的交换机上设置主机名/系统名: switch(config)# hostname hostname 在基于CLI的交换机上设置主机名/系统名: switch(enable) set system name name-string 2.在基于IOS的交换机上设置登录口令: switch(config)# enable password level 1 password 在基于CLI的交换机上设置登录口令: switch(
-
Perl学习教程之单行命令详解
前言 本文主要给大家介绍了关于Perl单行命令的相关内容,分享出来供大家参考学习,下面话不多说了,来一起看看详细的介绍吧. 与One-Liner相关的perl参数 -a 自动分隔模式,用空格分隔$并保存在@F中,也就是@F=split //, $ -F 指定-a的分隔符 -l 对输入的内容进行自动chomp,对输出的内容自动加换行符 -n 相当于while(<>) -e 执行命令,也就是脚本 -p 自动循环+输出,也就是while(<>){命令(脚本); print;} 记住以上几
-
PostgreSQL教程(十八):客户端命令(2)
七.pg_dump: pg_dump是一个用于备份PostgreSQL数据库的工具.它甚至可以在数据库正在并发使用时进行完整一致的备份,而不会阻塞其它用户对数据库的访问.该工具生成的转储格式可以分为两种,脚本和归档文件.其中脚本格式是包含许多SQL命令的纯文本格式,这些SQL命令可以用于重建该数据库并将之恢复到生成此脚本时的状态,该操作需要使用psql来完成.至于归档格式,如果需要重建数据库就必须和pg_restore工具一起使用.在重建过程中,可以对恢复的对象进行选择,甚至可以在恢复之前对需要