python爬虫爬取淘宝商品信息(selenum+phontomjs)
本文实例为大家分享了python爬虫爬取淘宝商品的具体代码,供大家参考,具体内容如下
1、需求目标 :
进去淘宝页面,搜索耐克关键词,抓取 商品的标题,链接,价格,城市,旺旺号,付款人数,进去第二层,抓取商品的销售量,款号等。

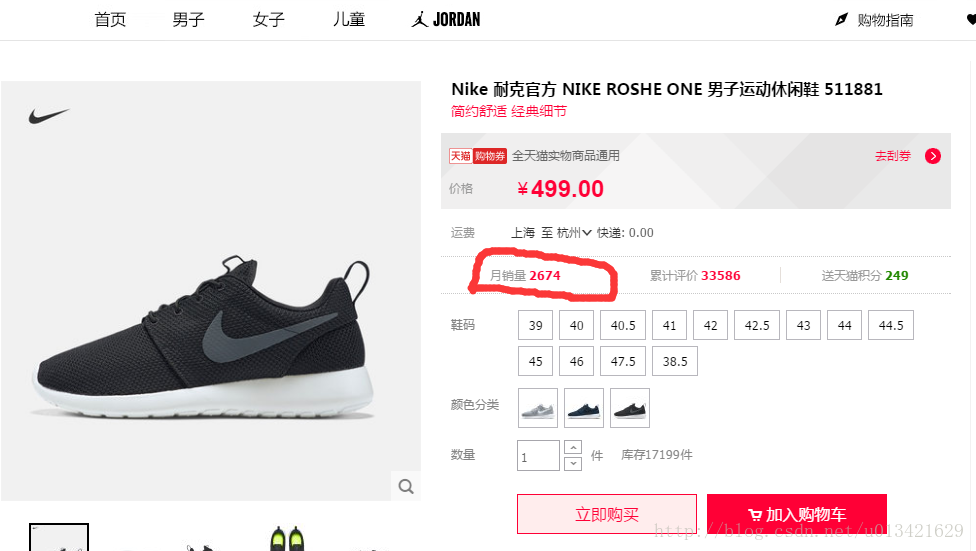

2、结果展示
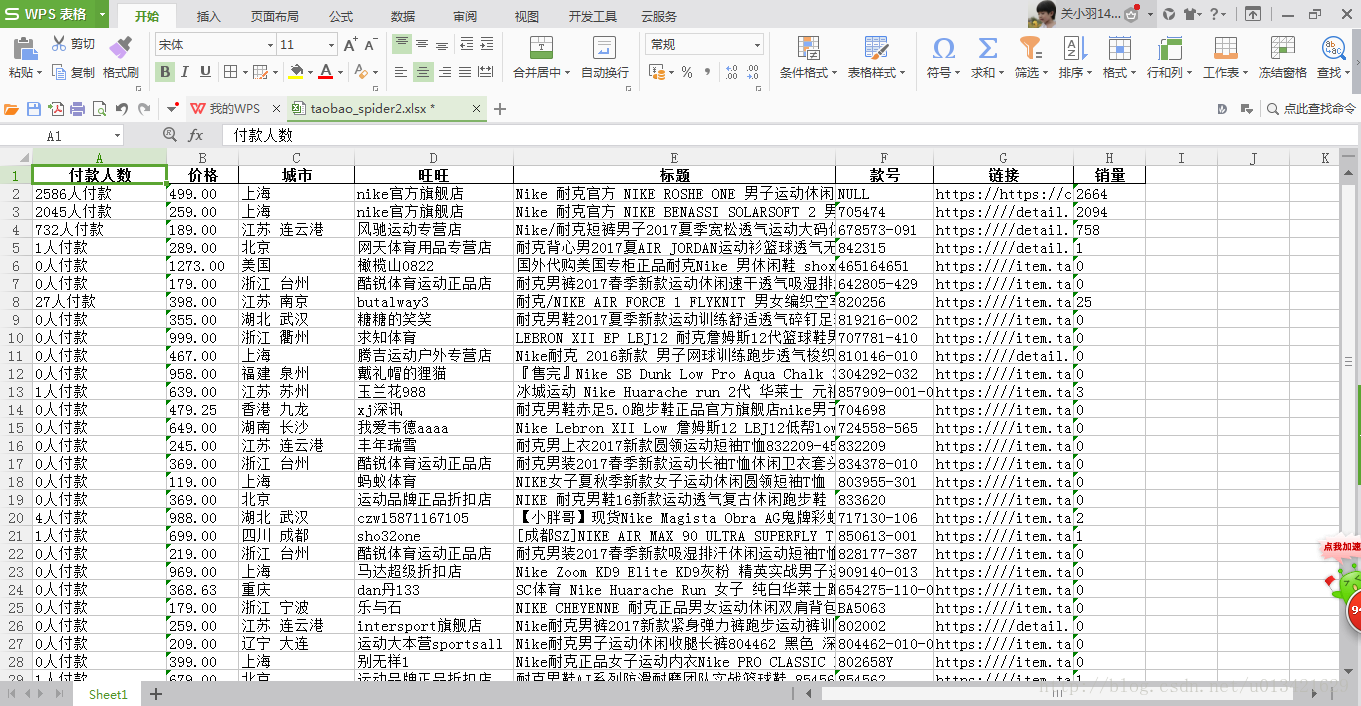
3、源代码
# encoding: utf-8
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
import time
import pandas as pd
time1=time.time()
from lxml import etree
from selenium import webdriver
#########自动模拟
driver=webdriver.PhantomJS(executable_path='D:/Python27/Scripts/phantomjs.exe')
import re
#################定义列表存储#############
title=[]
price=[]
city=[]
shop_name=[]
num=[]
link=[]
sale=[]
number=[]
#####输入关键词耐克(这里必须用unicode)
keyword="%E8%80%90%E5%85%8B"
for i in range(0,1):
try:
print "...............正在抓取第"+str(i)+"页..........................."
url="https://s.taobao.com/search?q=%E8%80%90%E5%85%8B&imgfile=&js=1&stats_click=search_radio_all%3A1&initiative_id=staobaoz_20170710&ie=utf8&bcoffset=4&ntoffset=4&p4ppushleft=1%2C48&s="+str(i*44)
driver.get(url)
time.sleep(5)
html=driver.page_source
selector=etree.HTML(html)
title1=selector.xpath('//div[@class="row row-2 title"]/a')
for each in title1:
print each.xpath('string(.)').strip()
title.append(each.xpath('string(.)').strip())
price1=selector.xpath('//div[@class="price g_price g_price-highlight"]/strong/text()')
for each in price1:
print each
price.append(each)
city1=selector.xpath('//div[@class="location"]/text()')
for each in city1:
print each
city.append(each)
num1=selector.xpath('//div[@class="deal-cnt"]/text()')
for each in num1:
print each
num.append(each)
shop_name1=selector.xpath('//div[@class="shop"]/a/span[2]/text()')
for each in shop_name1:
print each
shop_name.append(each)
link1=selector.xpath('//div[@class="row row-2 title"]/a/@href')
for each in link1:
kk="https://" + each
link.append("https://" + each)
if "https" in each:
print each
driver.get(each)
else:
print "https://" + each
driver.get("https://" + each)
time.sleep(3)
html2=driver.page_source
selector2=etree.HTML(html2)
sale1=selector2.xpath('//*[@id="J_DetailMeta"]/div[1]/div[1]/div/ul/li[1]/div/span[2]/text()')
for each in sale1:
print each
sale.append(each)
sale2=selector2.xpath('//strong[@id="J_SellCounter"]/text()')
for each in sale2:
print each
sale.append(each)
if "tmall" in kk:
number1 = re.findall('<ul id="J_AttrUL">(.*?)</ul>', html2, re.S)
for each in number1:
m = re.findall('>*号: (.*?)</li>', str(each).strip(), re.S)
if len(m) > 0:
for each1 in m:
print each1
number.append(each1)
else:
number.append("NULL")
if "taobao" in kk:
number2=re.findall('<ul class="attributes-list">(.*?)</ul>',html2,re.S)
for each in number2:
h=re.findall('>*号: (.*?)</li>', str(each).strip(), re.S)
if len(m) > 0:
for each2 in h:
print each2
number.append(each2)
else:
number.append("NULL")
if "click" in kk:
number.append("NULL")
except:
pass
print len(title),len(city),len(price),len(num),len(shop_name),len(link),len(sale),len(number)
# #
# ######数据框
data1=pd.DataFrame({"标题":title,"价格":price,"旺旺":shop_name,"城市":city,"付款人数":num,"链接":link,"销量":sale,"款号":number})
print data1
# 写出excel
writer = pd.ExcelWriter(r'C:\\taobao_spider2.xlsx', engine='xlsxwriter', options={'strings_to_urls': False})
data1.to_excel(writer, index=False)
writer.close()
time2 = time.time()
print u'ok,爬虫结束!'
print u'总共耗时:' + str(time2 - time1) + 's'
####关闭浏览器
driver.close()
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
您可能感兴趣的文章:
- python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
- Python使用Selenium+BeautifulSoup爬取淘宝搜索页
- python3爬取各类天气信息
- 使用Python爬取最好大学网大学排名
- python爬取淘宝商品详情页数据
- python3爬取淘宝信息代码分析
- python爬虫爬取某站上海租房图片
- python爬取拉勾网职位数据的方法
- Python爬虫爬取一个网页上的图片地址实例代码
- python正则表达式爬取猫眼电影top100
相关推荐
-
Python使用Selenium+BeautifulSoup爬取淘宝搜索页
使用Selenium驱动chrome页面,获得淘宝信息并用BeautifulSoup分析得到结果. 使用Selenium时注意页面的加载判断,以及加载超时的异常处理. import json import re from bs4 import BeautifulSoup from selenium import webdriver from selenium.common.exceptions import TimeoutException from selenium.webdriver.com
-

Python爬虫爬取一个网页上的图片地址实例代码
本文实例主要是实现爬取一个网页上的图片地址,具体如下. 读取一个网页的源代码: import urllib.request def getHtml(url): html=urllib.request.urlopen(url).read() return html print(getHtml(http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=%E5%A3%81%E7%BA%B8&ct=201326592&am
-
python正则表达式爬取猫眼电影top100
用正则表达式爬取猫眼电影top100,具体内容如下 #!/usr/bin/python # -*- coding: utf-8 -*- import json # 快速导入此模块:鼠标先点到要导入的函数处,再Alt + Enter进行选择 from multiprocessing.pool import Pool #引入进程池 import requests import re import csv from requests.exceptions import RequestException
-
python爬取淘宝商品详情页数据
在讲爬取淘宝详情页数据之前,先来介绍一款 Chrome 插件:Toggle JavaScript (它可以选择让网页是否显示 js 动态加载的内容),如下图所示: 当这个插件处于关闭状态时,待爬取的页面显示的数据如下: 当这个插件处于打开状态时,待爬取的页面显示的数据如下: 可以看到,页面上很多数据都不显示了,比如商品价格变成了划线价格,而且累计评论也变成了0,说明这些数据都是动态加载的,以下演示真实价格的找法(评论内容找法类似),首先检查页面元素,然后点击Network选项卡,刷新页面,可
-
python爬取拉勾网职位数据的方法
今天写的这篇文章是关于python爬虫简单的一个使用,选取的爬取对象是著名的招聘网站--拉钩网,由于和大家的职业息息相关,所以爬取拉钩的数据进行分析,对于职业规划和求职时的信息提供有很大的帮助. 完成的效果 爬取数据只是第一步,怎样使用和分析数据也是一大重点,当然这不是本次博客的目的,由于本次只是一个上手的爬虫程序,所以我们的最终目的只是爬取到拉钩网的职位信息,然后保存到Mysql数据库中.最后中的效果示意图如下: 控制台输入 数据库显示 准备工作 首先需要安装python,这个网上已经有很多的
-
python爬虫 正则表达式使用技巧及爬取个人博客的实例讲解
这篇博客是自己<数据挖掘与分析>课程讲到正则表达式爬虫的相关内容,主要简单介绍Python正则表达式爬虫,同时讲述常见的正则表达式分析方法,最后通过实例爬取作者的个人博客网站.希望这篇基础文章对您有所帮助,如果文章中存在错误或不足之处,还请海涵.真的太忙了,太长时间没有写博客了,抱歉~ 一.正则表达式 正则表达式(Regular Expression,简称Regex或RE)又称为正规表示法或常规表示法,常常用来检索.替换那些符合某个模式的文本,它首先设定好了一些特殊的字及字符组合,通过组合的&
-
使用Python爬取最好大学网大学排名
本文实例为大家分享了Python爬取最好大学网大学排名的具体代码,供大家参考,具体内容如下 源代码: #-*-coding:utf-8-*- ''''' Created on 2017年3月17日 @author: lavi ''' import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status r.encodi
-
python3爬取各类天气信息
本来是想从网上找找有没有现成的爬取空气质量状况和天气情况的爬虫程序,结果找了一会儿感觉还是自己写一个吧. 主要是爬取北京包括北京周边省会城市的空气质量数据和天气数据. 过程中出现了一个错误:UnicodeDecodeError: 'utf-8' codec can't decode byte 0xa1 in position 250. 原来发现是页面的编码是gbk,把语句改成data=urllib.request.urlopen(url).read().decode("gbk")就可以
-
python3爬取淘宝信息代码分析
# encoding:utf-8 import re # 使用正则 匹配想要的数据 import requests # 使用requests得到网页源码 这个函数是用来得到源码 # 得到主函数传入的链接 def getHtmlText(url): try: # 异常处理 # 得到你传入的URL链接 设置超时时间3秒 r = requests.get(url, timeout=3) # 判断它的http状态码 r.raise_for_status() # 设置它的编码 encoding是设置它的头
-
python爬虫爬取某站上海租房图片
对于一个net开发这爬虫真真的以前没有写过.这段时间开始学习python爬虫,今天周末无聊写了一段代码爬取上海租房图片,其实很简短就是利用爬虫的第三方库Requests与BeautifulSoup.python 版本:python3.6 ,IDE :pycharm.其实就几行代码,但希望没有开发基础的人也能一下子看明白,所以大神请绕行. 第三方库首先安装 我是用的pycharm所以另为的脚本安装我这就不介绍了. 如上图打开默认设置选择Project Interprecter,双击pip或者点击加